This repository includes source code for training and evaluating the Task-Aware Unified Source Separation (TUSS) model, proposed in the following ICASSP2025 paper:
@InProceedings{Saijo2025_tuss,
author = {Saijo, Kohei and Ebbers, Janek and Germain, Fran\c{c}ois G. and Wichern, Gordon and {Le Roux}, Jonathan},
title = {Task-Aware Unified Source Separation},
booktitle = {Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year = 2025,
month = apr
}
- Model Overview
- Audio Samples
- Installation
- Data preparation
- How to run
- Pre-trained models
- Separate a sample with a pre-trained model
- Notes
- Contributing
- Copyright and license
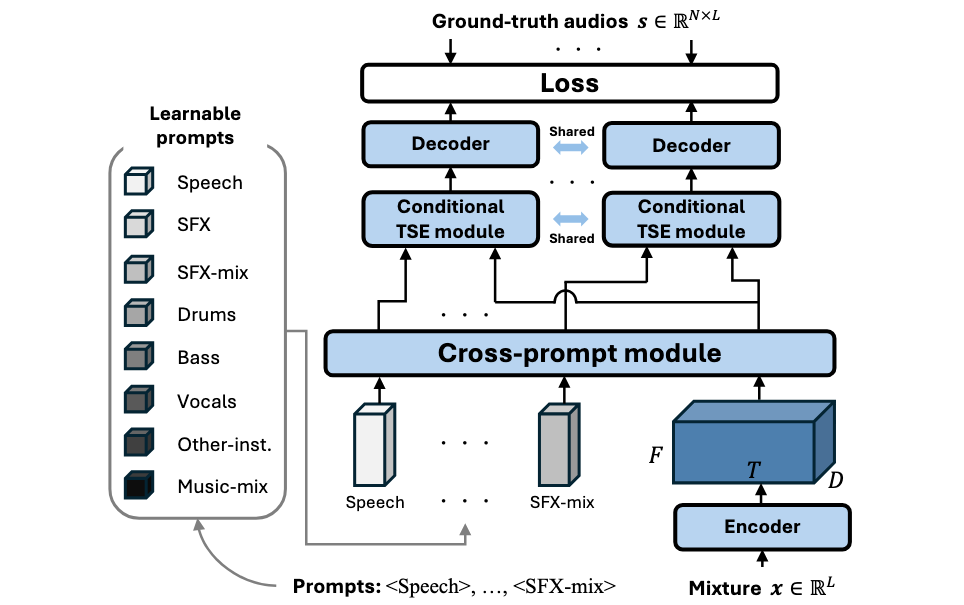
Our proposed task-aware unified source separation model can handle a varying number of input prompts that specify which types of source are present in the mixture and should be separated. Receiving the input mixture's encoded feature and learnable prompt embeddings that specify which source to separate, the cross-prompt module first jointly models both as a sequence to condition one on the other. Then, the source specified by each prompt is extracted by the conditional target source extraction (TSE) module. N sources are speparated given N prompts, where N can be a variable number.
We provide multiple audio examples showcasing different use cases of TUSS on our Demo Page.
Clone this repo and create the conda environment
$ git clone https://github.com/merlresearch/unified-source-separation
$ cd unified-source-separation && conda env create -f environment.yaml
$ conda activate tussData preparation scripts for all the datasets used in the paper are under dataprep.
They automatically download the datasets to output_dir defined in each dataprep/prepare_${dataset_name}.sh and generate .json files containing metadata under datasets/json_files. The scripts are set to automatically skip any step that has already been completed (including dataset downloads, which can be used to avoid re-downloading datasets you already have by setting symlinks; please see below).
Note that the python environment has to be activated in this stage.
As some datasets need manual download, please follow these steps:
- Download the MOISESDB dataset from here and put it under
./moisesdb. - Unzip the downloaded .zip file. Data will be under
./moisesdb/moisesdb/moisesdb_v0.1.
- Get the WSJ0 dataset from LDC (license is required)
- Make a symbolic link to the downloaded WSJ0 data as
./wsj/wsj0.
- Simulate the WHAMR! dataset following this webpage.
- Make a symbolic link to the WHAMR! directory (including
metadata,wav8k, andwav16kdirectories) as./whamr.
dataprep/dataprep.sh automatically prepares all the datasets and metadata .json files:
$ . dataprep/dataprep.shYou can run each dataprep/prepare_${dataset_name}.sh instead if you want to prepare datasets one by one:
# please do not forget this command when you run the script for the first time
$ mkdir -p "./datasets/json_files"
# please change the ${dataset_name} accordingly
$ . dataprep/prepare_${dataset_name}.shIf you already have some datasets, you can skip re-downloading by making a symbolic link from that directory to output_dir defined in each dataprep/prepare_${dataset_name}.sh (set to ./${dataset_name} by default).
$ ln -s /path/to/your/dataset ./${dataset_name}A convenient way to do this is to edit create_symlinks.sh with the correct paths for your system, commenting out the datasets you do not have, and run the script:
$ ./create_symlinks.shIf you do not have access to the WSJ0 speech, you can comment out wsj_speech and whamr in dataprep.sh to skip them.
Once the data preparation is done, 19 .json files can be seen under ./datasets/json_files:
./datasets/json_files/
├── demand_48k.json
├── dnr_44.1k.json
├── fma_44.1k.json
├── fsd50k_44.1k.json
├── fuss_16k.json
├── fuss_1src_16k.json
├── fuss_2src_16k.json
├── fuss_3src_16k.json
├── fuss_4src_16k.json
├── librivox_urgent2024.json
├── moisesdb_44.1k.json
├── moisesdb_44.1k_sad.json
├── musdb18hq_44.1k.json
├── musdb18hq_44.1k_sad.json
├── vctk_48k.json
├── vctk_demand_48k.json
├── wham_max_16k.json
├── wham_noise_48k.json
└── wsj0_speech_16k.json
The main script for training is in train.py, which can be run by
$ python train.py --config /path/to/configThe configuration files can be found under ./configs/ directory, where the configs/unified directory includes the configuration files to train a model using all the data, while configs/${dataset_name} directories contain those to train data- or task-specialist models (see our paper for the definition of the data- and task-specialists).
The checkpoints and tensorboard logs will be saved under exp/oss/*config-name* directory.
This is specified in train.py but you can change it if necessary.
After finishing the training, one can evaluate the separation performance using eval.py:
# please specify the GPU to use by, e.g., CUDA_VISIBLE_DEVICES=0, if necessary
$ python eval.py --ckpt_path /path/to/.ckpt-fileNote that --ckpt_path can be either a path to a single .ckpt file or a path to a directory containing .ckpt files.
If a directory is specified, all the .ckpt files under that directory except for last.ckpt are averaged, and the averaged weights are used for evaluation.
Evaluation in a single-prompt setup (refer to the paper for more details) can be run with a --single_prompt flag:
$ python eval.py --ckpt_path /path/to/.ckpt-file --single_promptOne can specify the segment and shift lengths of the long-recording separation as command-line arguments:
$ python eval.py --ckpt_path /path/to/.ckpt-file --css_segment_size 8 --css_shift_size 4By default, --css_segment_size and --css_shift_size are set to the values specified in hparams.yaml.
If you want to change other inference-related parameters, you can modify hparams.yaml saved under each exp/oss/*config-name* directory.
The implementation in this repository by default supports the following 8 types of prompts.
speechsfxsfxbg(mixture of sfx sources)drumsbassvocalsothermusicbg(mixture of instrumental sounds)
However, TUSS can algorithmically support more prompts.
One can extend TUSS to support, e.g., more instrumental sounds such as piano.
Note that mixtures of SFX and music instruments are denoted as sfx-mix and music-mix in our paper, but we name them sfxbg and musicbg in this implementation (bg stands for background).
We provide the pre-trained parameters of the medium and large models under ./pretrained_models/.
One can use these weights to, e.g., fine-tune the models on a specific task or separate some samples (see below to know how to separate a sample).
Please note that our re-trained models may not reproduce the exact results reported in the paper, since we used the refactored code in this repository. Although our performance remains competitive on most tasks, we observed occasional loss spikes on VCTK-DEMAND, which led to lower results than those presented in the original paper.
While eval.py automatically loads the corresponding prompts for each task, separate.py allows us to specify any combination of the supported prompts.
For instance, for the DnR dataset where we usually aim to separate a mixture into speech, sfxbg, and musicbg, we can also separate it into speech, sfx, sfx, and musicbg (see our audio example page).
One can use the provided pre-trained models to separate a sample. Following is an example to separate audio.wav using the medium model:
ckpt_path=pretrained_models/tuss.medium.2-4src/checkpoints/model.pth
# separate a sample into speech, sfxbg, and musicbg
$ python separate.py --ckpt_path ${ckpt_path} --audio_path /path/to/audio.wav --prompts speech sfxbg musicbg --audio_output_dir /path/to/output_dir
# separate a sample into speech, sfx, sfx, and musicbg
$ python separate.py --ckpt_path ${ckpt_path} --audio_path /path/to/audio.wav --prompts speech sfx sfx musicbg --audio_output_dir /path/to/output_dirOne can specify the start and end times (in second) by adding start_time and end_time arguments. This is useful when the input audio is very long (e.g., MSS or CASS) but only a specific part needs to be separated. For instance, the following command performs CASS on the 10-second segment cut out from from the input mixture between 5 and 15 seconds:
# cut out the segment between 5 and 15 seconds and process the resulting chunk.
$ python separate.py --ckpt_path ${ckpt_path} --audio_path /path/to/audio.wav --prompts speech sfxbg musicbg --audio_output_dir /path/to/output_dir --start_time 5 --end_time 15Note that the pre-trained models we provide were trained with 6-second chunks, and thus the models may perform poorly when the input is much longer than 6 seconds.
To separate entire long audio, one can specify css_segment_size and css_shift_size to perform the chunk-wise processing (a.k.a CSS):
# css_shift_size is set to css_segment_size // 2 if not given.
# One can also specify start_time and end_time if necessary.
$ python separate.py --ckpt_path ${ckpt_path} --audio_path /path/to/audio.wav --prompts speech sfxbg musicbg --audio_output_dir /path/to/output_dir --css_segment_size 8 --css_shift_size 4Note that source permutation between chunks is not solved in our CSS implmentation.
When training with a single GPU, we recommend users to change strategy in the .yaml config file to auto from ddp_find_unused_parameters_true.
The default config files specify ddp_find_unused_parameters_true as the pytorch lightning's trainer strategy for compatibility with DDP training, as some of the TUSS model's learnable prompts are not used in each forward pass.
However, ddp_find_unused_parameters_true may make training a bit slower, and it is not needed when DDP is not used.
When using multi-GPU DDP training, make sure to set the strategy in the .yaml config file to ddp_find_unused_parameters_true.
This is required because some of the TUSS model's learnable prompts are not used in each forward pass.
If exp/oss/*config-name* already exists when you start training with python train.py --config /path/to/config, train.py automatically resumes the training from exp/oss/*config-name*/checkpoints/last.ckpt.
If you want to initialize the model with pre-trained weights but do not want to load the other states saved in the .ckpt file (e.g., optimizer states), you can specify the path to the .ckpt file in the .yaml config file.
Please refer to configs/unified/tuss.large.2-4src.promptdropout.yaml as an example.
During training, errors like the following may appear:
[src/libmpg123/layer3.c:INT123_do_layer3():1801] error: dequantization failed!
[src/libmpg123/layer3.c:INT123_do_layer3():1773] error: part2_3_length (3264) too large for available bit count (3240)
This happens when loading some .mp3 files from the FMA dataset. We checked some samples causing this error, but they sounded normal. This error does not stop the training and thus can be ignored.
Current implementation assumes that the input is a monaural signal. When evaluating the performance in MSS, we process each channel independently and then concatenate them to make the signal stereo. Any multi-channel signal can be processed in the same way, but TUSS can be easily extended to handle multi-channel inputs by modifying the input/output dimension of the encoder/decoder, respectively.
See CONTRIBUTING.md for our policy on contributions.
Released under AGPL-3.0-or-later license, as found in the LICENSE.md file.
All files, except as noted below:
Copyright (C) 2025 Mitsubishi Electric Research Laboratories (MERL)
SPDX-License-Identifier: AGPL-3.0-or-later
Part of the following files:
nets/model_wrapper.pyutils/average_model_params.py
were adapted from https://github.com/espnet/espnet (license included in LICENSES/Apache-2.0.md)
Copyright (C) 2025 Mitsubishi Electric Research Laboratories (MERL)
Copyright (C) 2025 ESPnet Developers
SPDX-License-Identifier: AGPL-3.0-or-later
SPDX-License-Identifier: Apache-2.0
The following files:
dataprep/prepare_librivox_urgent2024.shdataprep/download_librivox_speech.shdataprep/filter_via_dnsmos.pydataprep/filter_via_vad.pydataprep/resample_to_estimated_bandwidth.pydataprep/tar_extractor.py
were adapted from https://github.com/urgent-challenge/urgent2024_challenge (license included in LICENSES/Apache-2.0.md)
# Copyright (C) 2025 Mitsubishi Electric Research Laboratories (MERL)
# Copyright (C) 2024 Wangyou Zhang
#
# SPDX-License-Identifier: AGPL-3.0-or-later
# SPDX-License-Identifier: Apache-2.0
The following files:
dataprep/prepare_fsd50k_noise.shdataprep/prepare_fma_noise.sh
were adapted from https://github.com/urgent-challenge/urgent2025_challenge (license included in LICENSES/Apache-2.0.md)
# Copyright (C) 2025 Mitsubishi Electric Research Laboratories (MERL)
# Copyright (C) 2024 Kohei Saijo
#
# SPDX-License-Identifier: AGPL-3.0-or-later
# SPDX-License-Identifier: Apache-2.0
Part of the following file:
dataprep/fma.py
was adapted from https://github.com/mdeff/fma (license included in LICENSES/MIT.md)
# Copyright (C) 2025 Mitsubishi Electric Research Laboratories (MERL)
# Copyright (c) 2016 Michaël Defferrard
#
# SPDX-License-Identifier: AGPL-3.0-or-later
# SPDX-License-Identifier: MIT