Bridging Signal Processing and Group Equivariant Deep Learning "Sampling theory meets symmetry preservation"
Tutorial and Example Codes on Google Colab
We present the first group-equivariant downsampling layer with built-in anti-aliasing that:
Maintains equivariance guarantees
Reduces feature map dimensions while preserving critical information
Outperforms naive subsampling in G-CNNs
-
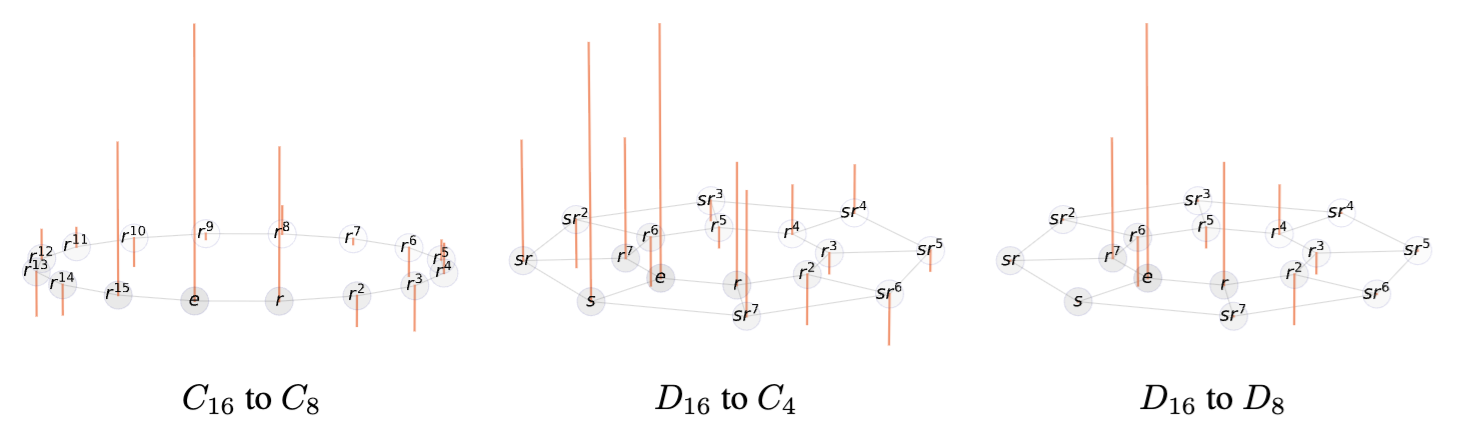
Uniform sub-group subsampling for arbitrary finite groups.
-
Automatic subgroup selection based on group structure.
-
Equivariant anti-aliasing filters learned via spectral optimization.
-
Seamless integration with existing group equivariant architectures.
git clone https://github.com/ashiq24/Group_Sampling.git
cd Group_Sampling
pip install -e .External Dependencies: ESCNN (for group operations)
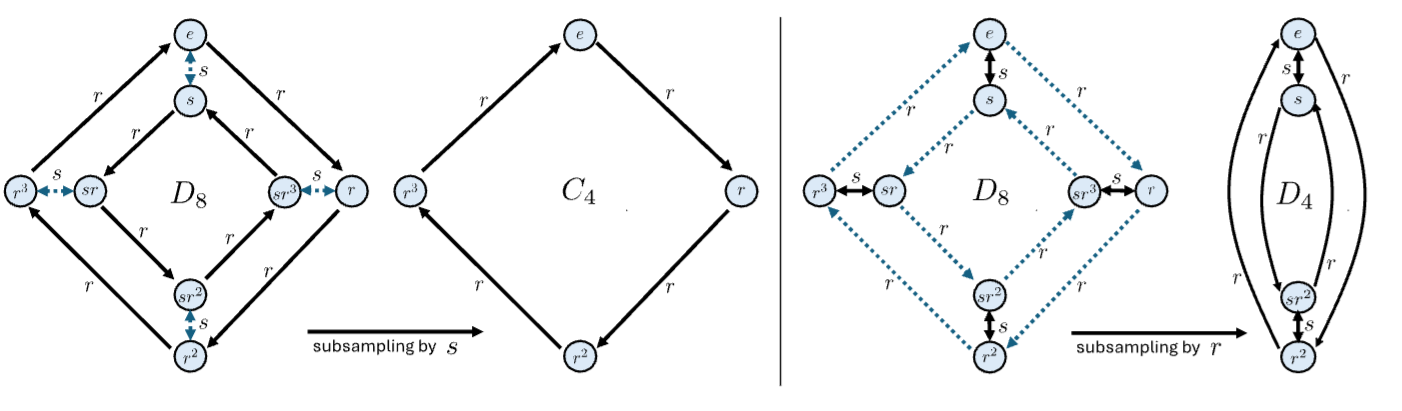
Performs subgroup subsampling based on the corresponding Cayley graph and performs equivariant anti-aliasing operation. Applicable for any group equivariant architecture using the regular representation of groups.
- Basic Integration
from gsampling.layers.downsampling import SubgroupDownsample
d_layer = SubgroupDownsample(
group_type="dihedral", # Parent group type
order=12, # Order of rotation elements
sub_group_type="dihedral", # Subgroup type to downsample to
subsampling_factor=2, # Factor to reduce group by
num_features=10, # Number of input feature channels
generator="r-s", # Generators for Cayley graph construction
dtype=torch.float32, # Data type
apply_antialiasing=True, # Enable equivariant anti-aliasing
anti_aliasing_kwargs={ # Anti-aliasing optimization params
"iterations": 100, # Number of optimization steps
"smoothness_loss_weight": 0.1, # Smoothness strength in optimization
},
).to(device=device)
input_tensor = torch.randn( batch_size, 10 * 24, 32, 32, device=device, dtype=dtype)
out, canonicalization_element = d_layer(input_tensor)
print("Input shape:", input_tensor.shape)
print("Output shape:", out.shape)- Whole Model Integration
from gsampling.models.model_handler import get_model
# Configure hierarchical group-equivariant architecture
model = get_model(
input_channel=3, # RGB input channels
num_channels=[32, 64, 128], # Feature channels per stage
num_layers=3, # Number of processing stages
dwn_group_types=[
["dihedral", "dihedral"], # [input_group, subgroup] for stage 1
["dihedral", "dihedral"], # For stage 2
["dihedral", "dihedral"] # For stage 3
],
subsampling_factors=[2, 1, 1], # Group reduction factors per stage
spatial_subsampling_factors=[2, 1, 1], # Spatial downsampling factors
num_classes=10, # STL-10 has 10 classes
antialiasing_kwargs={
"iterations": 100, # number of optimization steps
"smoothness_loss_weight": 0.5 # smoothness weight
}
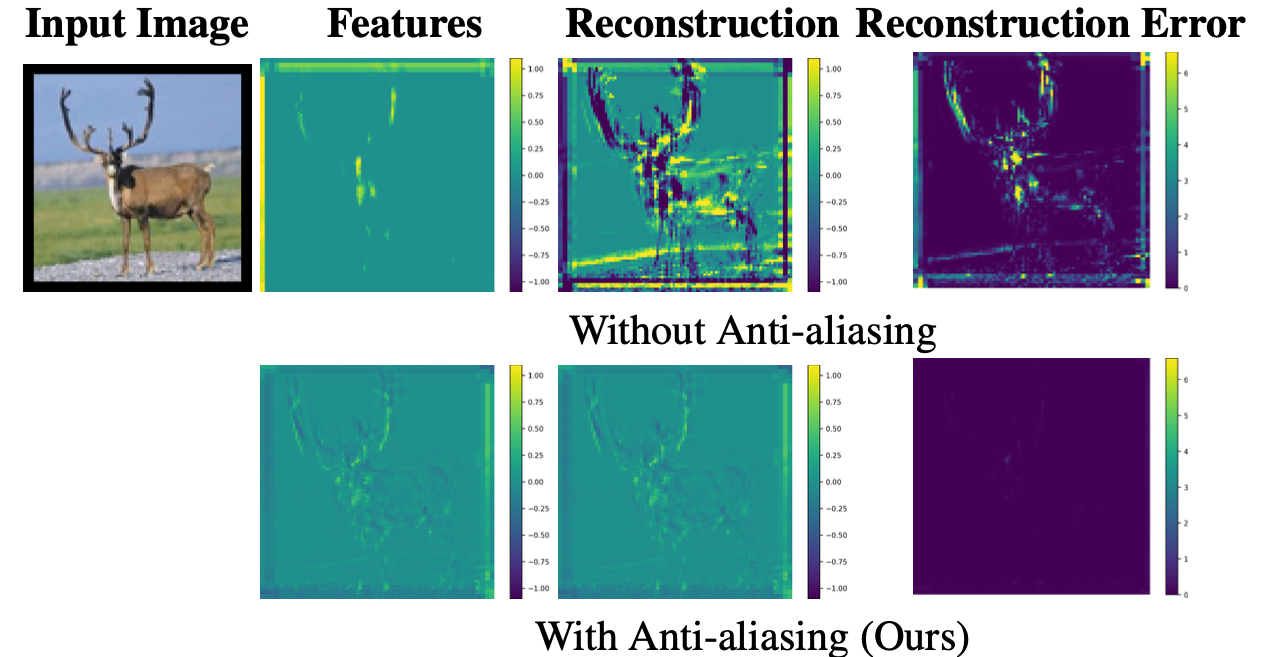
)Traditional downsampling in the group-equivariant model creates aliasing and introduces error.
Our method
Provides provable reconstruction guarantees via the group sampling theorem Preserves symmetry guarantees Reduces parameters while maintaining performance
Our anti-aliasing maintains lower error rates in deeper layers compared to naive subsampling. 🎯

We can perfectly reconstruct features corresponding to the discarded group elements during the subsampling process. This follows directly from the proposed Subgroup sampling theorem.