Qiita記事「日本語Pre-Trained BERTを用いた対話Botの作成」で使用したソースコード
学習済みモデル:model.pth
N-gram言語モデル:ngram.binary
基本的な構造は、多層LSTMのAttention付きEncoder-DecoderモデルのEncoderにBERTを追加したものになります。 DecoderへのLSTM状態の入力はLSTMが担い、AttentionのKey-Valueへの入力はBERTが行います。
実行環境
- OS:Ubuntu 20.04
- Python 3.7.13 (conda 4.12.0)
- CUDA 11.1
- cuDNN 8.4.1
Python ライブラリ
- PyTorch 1.8.2 +CUDA 11.1
- protbuf 3.19.4
- transformers 3.4.0
- pyknp 0.6.1
- kenlm 0.0.0
使用したコーパス
- Twitterのツイートとリプライのペア
- 落語コーパス
- 名大コーパス
- 日本語Wikipedia(N-gramの構築のみ)
今回使用するBERTは、京都大学の黒橋・褚・河原研究室で公開されている学習済みモデル(BASE WWM版)を利用します。 BERT日本語Pretrainedモデル - 黒橋・褚・村脇研究室
ダウンロードして解凍したBERTモデルは resource/bert に移します。 また、解凍したディレクトリの中にはvocab.txtがあるので、 ngram/bert にコピーしておきます。 これでBERTのインストールは完了です。
京大BERTを利用するにあたり、形態素解析器としてJuman++をインストールします。 必要Pythonライブラリで示した pyknp は Python コード内でJuman++を使用するためのライブラリです。
さらに、対話の応答生成では、応答の自然さ向上のため、N-gram言語モデルによる応答文のスコアリングを行います。 そのため、KenLMをインストールし、N-gram言語モデルの構築も行います。
次節より、各ライブラリのインストール作業を始めます。 各ライブラリのインストールにあたり、cmakeが入ってない方はcmakeのインストールを行ってください。
$ sudo apt-get install build-essential libboost-all-dev cmake zlib1g-dev libbz2-dev liblzma-dev
$ sudo apt install cmake
$ cd ~/
$ wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc2/jumanpp-2.0.0-rc2.tar.xz
$ tar xfv jumanpp-2.0.0-rc2.tar.xz
$ cd jumanpp-2.0.0-rc2
$ mkdir bld
$ cd bld
$ sudo cmake .. -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/usr/local
$ sudo make install -j2
動作確認
$ echo "外国人参政権" | jumanpp
外国 がいこく 外国 名詞 6 普通名詞 1 * 0 * 0 "代表表記:外国/がいこく ドメイン:政治 カテゴリ:場所-その他"
人 じん 人 名詞 6 普通名詞 1 * 0 * 0 "代表表記:人/じん カテゴリ:人 漢字読み:音"
@ 人 じん 人 名詞 6 普通名詞 1 * 0 * 0 "代表表記:人/ひと カテゴリ:人 漢字読み:訓"
参政 さんせい 参政 名詞 6 サ変名詞 2 * 0 * 0 "代表表記:参政/さんせい ドメイン:政治 カテゴリ:抽象物"
権 けん 権 名詞 6 普通名詞 1 * 0 * 0 "代表表記:権/けん カテゴリ:抽象物 漢字読み:音"
EOS
$ cd ~/
$ wget -O - https://kheafield.com/code/kenlm.tar.gz |tar xz
$ mkdir kenlm/build
$ cd kenlm/build
$ sudo cmake ..
$ sudo make -j2
$ cd ~/
$ chmod u+x ./kenlm/bin/*
(ディレクトリ構造で示した ngram ディレクトリ下に build ディレクトリをコピー)
$ cp -r kenlm/build /path/to/dialog_sys/ngram/
$ mv build kenlm
実際にpythonライブラリとしてkenlmを使用する際には、Python仮想環境(Anacondaなど)を立ち上げた上で kenlm ディレクトリ下にある setup.py を実行する必要があります。
$ python setup.py install
これで必要なライブラリのインストールは完了です。
先ほどインストールしたKenLMを用いて応答文スコアリング用のN-gram言語モデルを作成します。
事前にコーパスを用意したうえで読み進めてください。
ここで使用するコーパスデータは1行に1文の形式を想定しています。 (対話システムモデルの学習に使うデータは、発話と応答のペア形式で別形式なので、注意してください)
まず、用意したデータに preprocess.py を用いて前処理を行います。 ここでは、データのファイル名を inputs.txt としています。
preprocess.py では用意したコーパスをさらに読点で分割します。 読点で分割するのは、対話システムが生成した応答を評価する際、読点の有無で評価結果(出現確率)が揺れることを防ぐためです。
例えば、3-gram 言語モデルは以下の式で表されますが、
この
そこで単純な解決策として、読点で文を分割し、ある程度の語彙のまとまりを一つの文として扱う方法を採用しています。
preprocess.py の実行後、同じディレクトリ内に inputs_tknz.txt が作成されているはずなので、この inputs_tknz.txt を使用し3-gram言語モデルの構築を行います。
$ cat inputs_tknz.txt |./kenlm/bin/lmplz -o 3 > ngram.arpa
出来上がった ngram.arpa は、高速化のためバイナリ形式に変換します。
$ ./kenlm/bin/build_binary trie ngram.arpa ngram.binary
出力された ngram.binary は dialog_sys/ngram/scoring/models ディレクトリ下に配置してください。
これでN-gram言語モデルの構築は完了です。
学習データは dialog_sys/data ディレクトリ下の train に訓練データを、eval に検証データを配置します。
今回、学習で使用するデータの形式は以下の通りになっています。
- ヘッダーにファイルが持つデータのレコード数(行数)
- 各レコードは「発話文 , 応答文」の形式。
- 発話・応答文はそれぞれ、ID化された形態素がスペース区切りで並ぶ。
以下に例を示します。(データは公開できないため数字は適当です)
3
2 52 40 56 789 321 7 3,2 78 54 2 67 7 3
2 76 7324 567 3,2 5532 44 901 7 3
2 690 1702 7 3,2 590 112 68 7 3また、Jumann++ を形態素解析器として利用するため、学習の高速化の観点から、学習データの形態素解析とID化は事前に済ませておきます。
(こちらは、興味のある方のみ取り組んでみてください。)
transformers の BertForMaskedLM を用いて未知語である [UNK]トークンを [MASK]トークンに置き換えて単語予測を行います。こうすることで、学習データから未知語を削除します。
こちらは先ほど述べた形式のデータに replace_unk.pyを適用することで達成できます。
実行は、dialog_sysディレクトリから行います。
$ python utils/replace_unk.py
BERTモデルとデータセットが適切に配置されていれば問題なく実行され、dialog_sys/data ディレクトリに train_cleaned, eval_cleaned の2つが生成されているはずなので、train, eval にそれぞれ名前を変えておいてください。
以上で事前準備は終了です。
作成するモデルの概要は以下のようになっています。
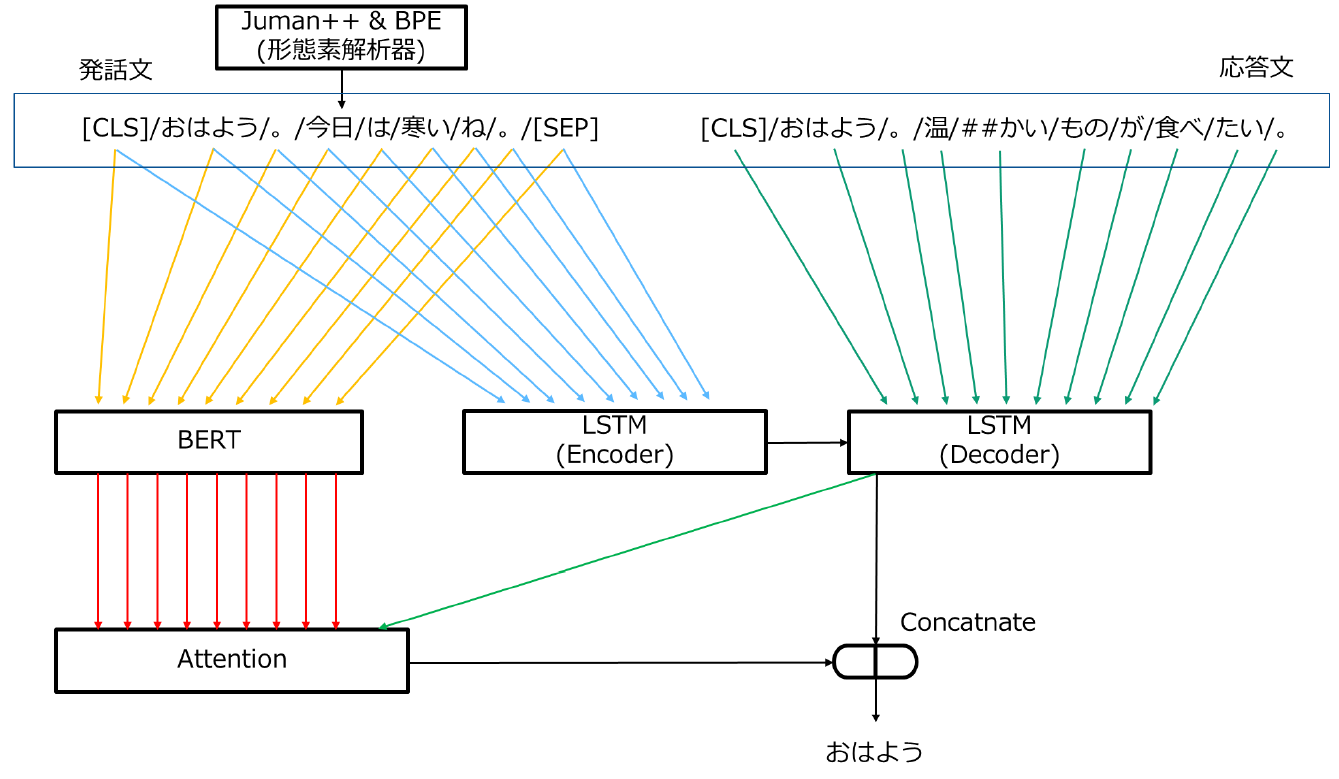
なお、損失関数にはCrossEntropyLossとKLDivLossを用いています。 CrossEntropyLoss には教師データと出力の誤差を計算させ、KLDivLoss には BertForMaskedLM と出力分布の誤差を計算させています。
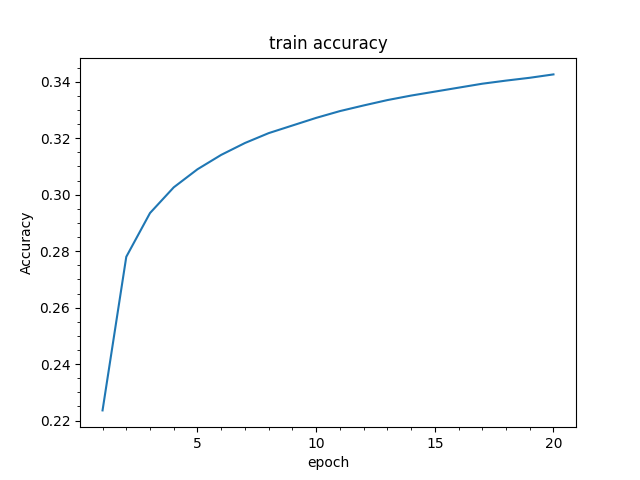
以降、以下のハイパーパラメータで学習を行うことを想定しています。
- エポック数:20
- 隠れ層のサイズ:128
- LSTMの隠れベクトルサイズ:128
- Encoder:双方向LSTM
- LSTM層:2層
- 学習率:1e-4
- AdamW eps:1e-9
- バッチサイズ:64
- CrossEntropyLoss係数:1
- KLDivLoss係数:1
学習は dialog_sysディレクトリで main.pyを実行します。
python main.py \
--model-path params/model.pth \
--epoch-num 20 \
--batch-size 64 \
--enc-len 128 \
--max-len 64 \
--lr 1e-4 \
--beta1 0.9 \
--beta2 0.98 \
--criterion-reduction batchmean \
--adamw-eps 1e-9 \
--disp-progress \
--train-data data/train \
--eval-data data/eval \
--bert-path resource/bert/Japanese_L-12_H-768_A-12_E-30_BPE_WWM/pytorch_model.bin \
--bert-config resource/bert/Japanese_L-12_H-768_A-12_E-30_BPE_WWM/bert_config.json \
--bert-vocab resource/bert/Japanese_L-12_H-768_A-12_E-30_BPE_WWM/vocab.txt \
--num-layer 2 \
--use-bidirectional \
--cross-loss-coef 1 \
--mse-loss-coef 1 \
--bert-hsize 768 \
--hidden-size 128 \
--lstm-hidden-size 128


対話には、dialog.pyと BJtokenizer.pyを用います。
dialog.pyでは、応答候補をコマンドライン引数で指定された回数だけ生成し、生成した応答候補をN-gram言語モデルでスコアリングします。 また、応答候補にバリエーションを持たせるために、モデルは推論モードではなく、学習モードで動作させています。 推論モードでは、Dropoutレイヤの動作が一定になってしまいランダム性がなくなるためです。
BJtokenizer.py で実装した remove_duplication() は、Seq2Seqモデルが発生させがちな、同じ単語列の繰り返しを除去するための関数です。2単語の繰り返しと、3単語の繰り返しを除去することが可能です。
対話を行うには、dialog_sysディレクトリで dialog.pyを実行します。
python dialog.py \
--model-path params/mode.pth \
--enc-len 128 \
--max-len 64 \
--bert-path resource/bert/Japanese_L-12_H-768_A-12_E-30_BPE_WWM/pytorch_model.bin \
--bert-config resource/bert/Japanese_L-12_H-768_A-12_E-30_BPE_WWM/bert_config.json \
--bert-vocab resource/bert/Japanese_L-12_H-768_A-12_E-30_BPE_WWM/vocab.txt \
--num-layer 2 \
--use-bidirectional \
--bert-hsize 768 \
--hidden-size 128 \
--lstm-hidden-size 128 \
--used-ngram-model ngram/scoring/models/ngram.binary \
--remove-limit -5.0 \
--resp-gen 50 \
--length-dist-mean 15 \
--length-dist-var 7 \
--length-dist-scale 1
>>おはようございます
2022-08-07 00:30:00,176 | INFO | dialog | ['おはよう', 'ございます']
2022-08-07 00:30:00,176 | INFO | dialog | [2, 20401, 26296, 16613, 3]
2022-08-07 00:30:00,177 | INFO | dialog | ['[CLS]', 'おはよう', 'ござい', '##ます', '[SEP]']
2022-08-07 00:30:00,338 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'ましょう', '。'], -1.5390460212279398
2022-08-07 00:30:00,340 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'みた', '##いで', '##す', 'ね', '。'], -0.8311027577638342
2022-08-07 00:30:00,341 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'ました', '。', 'また', '一', '週間', '頑', '##張り', 'ましょう', '。'], -1.0192636977063367
2022-08-07 00:30:00,342 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,343 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,344 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,345 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,346 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '体調', 'に', '気', 'を', 'つけて', 'お', '過ごし', 'ください', '。'], -0.9675886409728524
2022-08-07 00:30:00,347 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,348 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'と', 'は', '。', 'また', '寒', '##く', 'なる', 'と', '良い', 'です', 'ね', '。', 'また', '寒', '##く', 'なる', 'ので', '体調', 'に', '気', 'を', 'つけて', 'お', '過ごし', 'ください', 'ね', '。'], -1.1559675664573703
2022-08-07 00:30:00,349 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'ました', 'ね', '。', 'また', '、', 'よろ', '##しく', 'お', '願い', 'し', 'ます', '。'], -0.6966054774457718
2022-08-07 00:30:00,350 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '体調', 'に', '気', 'を', 'つけて', '過ごし', 'ましょう', 'ね', '。'], -1.0263286904042204
2022-08-07 00:30:00,351 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '、', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8167832432378189
2022-08-07 00:30:00,352 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,353 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'ました', '。'], -1.0285498902465497
2022-08-07 00:30:00,354 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '1', '週間', '始まり', 'ました', '。'], -1.2970063627483002
2022-08-07 00:30:00,355 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '今日', 'から', 'また', '頑', '##張り', 'ます', '。'], -1.017103444330368
2022-08-07 00:30:00,357 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '、', '体調', '管理', 'は', '気', 'を', 'つけて', 'ね', '。'], -1.3521428182655357
2022-08-07 00:30:00,358 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,359 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '、', 'また', '寒', '##く', 'なる', 'みた', '##いで', '##す', 'ね', '。'], -0.9943853372248633
2022-08-07 00:30:00,360 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '、', 'また', '寒', '##く', 'なる', 'みた', '##いで', '##す', 'ね', '。'], -0.9943853372248633
2022-08-07 00:30:00,361 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,362 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,363 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'から', '体調', 'が', '気', 'を', 'つけて', 'ね', '。'], -1.3306418438806813
2022-08-07 00:30:00,364 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,365 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,366 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', '今日', 'から', 'また', '1', '週間', '頑', '##張り', 'ましょう', '。'], -0.5892339273855319
2022-08-07 00:30:00,367 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'みた', '##いで', '##す', 'ね', '。'], -0.8311027577638342
2022-08-07 00:30:00,368 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'みた', '##いで', '##す', 'ね', '。'], -0.8311027577638342
2022-08-07 00:30:00,369 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '。'], -1.0449508894977235
2022-08-07 00:30:00,370 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.9198907347992531
2022-08-07 00:30:00,371 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', 'また', '寒', '##く', 'なる', 'と', '。'], -1.6968229345808978
2022-08-07 00:30:00,372 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'みた', '##いで', '##す', 'ね', '。'], -0.8311027577638342
2022-08-07 00:30:00,373 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,375 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'から', 'また', '寒', '##く', 'なる', 'ので', '体調', 'に', '気', 'を', 'つけて', 'ね', '。'], -1.078991015065561
2022-08-07 00:30:00,376 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,377 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'みた', '##いで', '##す', 'ね', '。'], -0.8311027577638342
2022-08-07 00:30:00,378 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '、', 'また', '寒', '##く', 'なる', 'ので', '体調', 'に', '気', 'を', 'つけて', 'ください', 'ね', '。'], -1.0855622981239614
2022-08-07 00:30:00,379 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', 'また', '寒', 'さ', 'に', '。'], -1.9063656110538225
2022-08-07 00:30:00,380 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '、', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -1.0222690919643314
2022-08-07 00:30:00,381 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', '。'], -0.9307650350838713
2022-08-07 00:30:00,382 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,383 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,384 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'ました', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -1.0059363044132827
2022-08-07 00:30:00,385 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,386 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'ので', '、', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -1.0222690919643314
2022-08-07 00:30:00,387 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,388 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なる', 'から', 'また', '寒', '##く', 'なる', 'ので', '体調', 'に', '気', 'を', 'つけて', '。'], -1.1024721344772854
2022-08-07 00:30:00,389 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', 'また', '寒', '##く', 'なり', 'そう', '##です', 'ね', '。'], -0.8654009120203885
2022-08-07 00:30:00,390 | INFO | dialog | cand: ['おはよう', 'ござい', '##ます', '。', '今日', 'は', '寒い', 'です', 'ね', '。', 'また', '寒', '##く', 'なる', 'と', '良い', 'です', 'ね', '。'], -0.9382374299182704
2022-08-07 00:30:00,390 | INFO | dialog | Before (duplication): おはよう ございます 。 今日 から また 1 週間 頑張り ましょう 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP] 。 [SEP]
2022-08-07 00:30:00,391 | INFO | dialog | After (duplication): [['おはよう', 'ござい', '##ます', '。', '今日', 'から', 'また', '1', '週間', '頑', '##張り', 'ましょう', '。'], -0.5892339273855319]
2022-08-07 00:30:00,391 | INFO | dialog | sys: おはようございます。今日からまた1週間頑張りましょう。
上は「おはようございます」と入力した際の出力結果です。
結果ログの出力形式は出力順に、次のようになっています。
- ユーザ入力(>> が付いているもの)
- ID化形態素系列
- 形態素系列
- 応答候補とそのスコア(cand: と付いているもの)
- remove_duplication の効果の確認(duplication と付いているもの)
- 対話システムの最終的な応答(sys: と付いているもの)
他の対話結果は、ユーザ入力とシステムの最終的な応答のみに絞って紹介します。 右がユーザの発話、左が発話に対するシステムの返答です。
| User | System |
|---|---|
| 今日のバイト疲れた | お疲れ様です。 |
| やっと記事が書けたよ | おめでとうございます。 |
| また飲みに行こう! | また行きたいです。 |
| 今日は寒かった | おはようございます。寒いですね。寒いですね。 |
| 今日は暑かった | 今日は、お疲れ様です。 |
| 名古屋までサイクリングした | うん。 |
| 機械学習難しい | そうですね。 |
Qiita記事
- 実践PyTorch
- 【深層学習】図で理解するAttention機構
- 作って理解する Transformer / Attention
- Visual Studio Code でPythonファイルをデバッグする方法
Webページ