{kind=link}
{kind=link}
Tokenizer, POS-tagger, lemmatizer, and dependency-parser for modern and contemporary Japanese, working on Universal Dependencies.
>>> import unidic2ud
>>> nlp=unidic2ud.load("kindai")
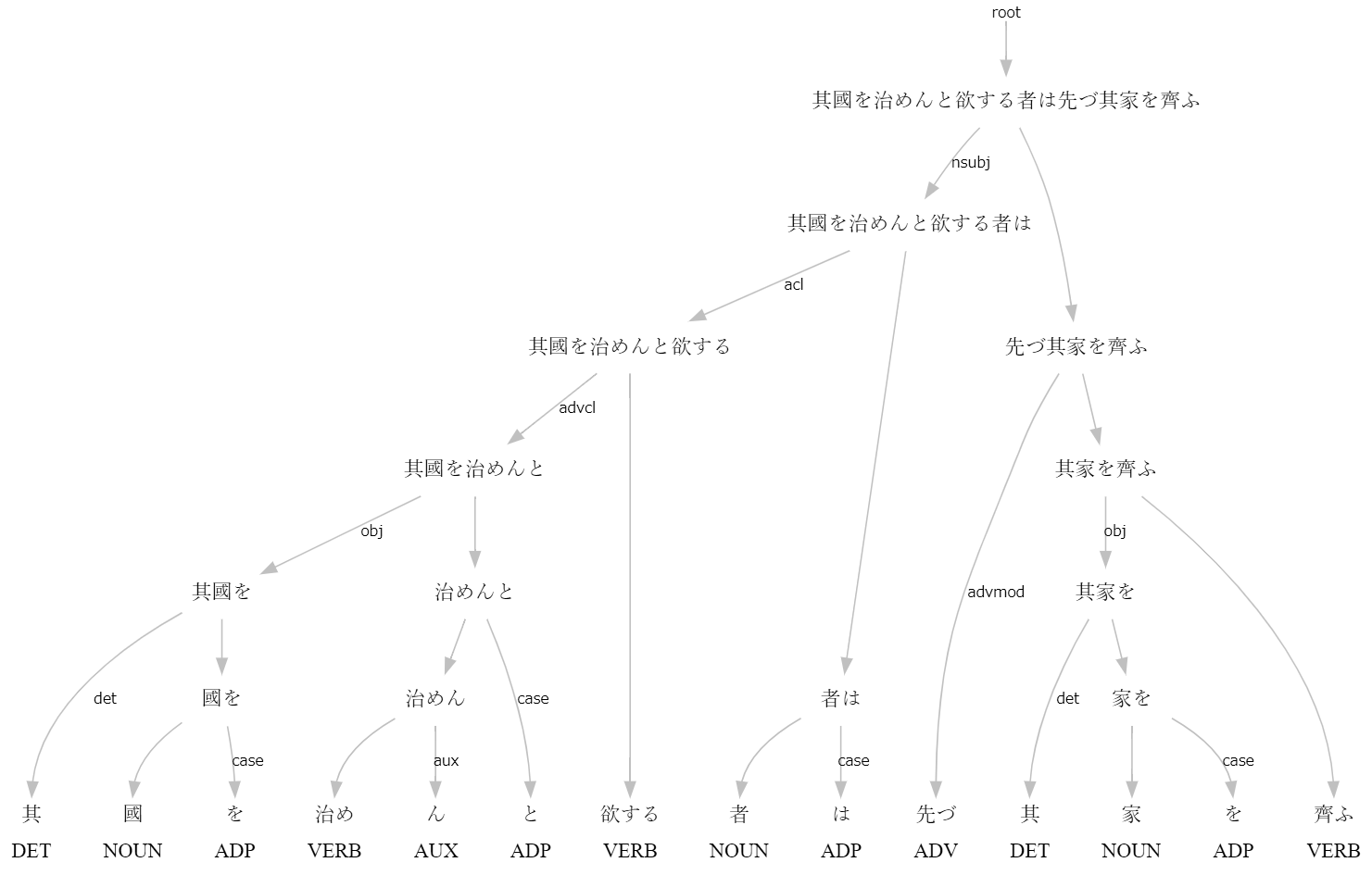
>>> s=nlp("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(s)
# text = 其國を治めんと欲する者は先づ其家を齊ふ
1 其 其の DET 連体詞 _ 2 det _ SpaceAfter=No|Translit=ソノ
2 國 国 NOUN 名詞-普通名詞-一般 _ 4 obj _ SpaceAfter=No|Translit=クニ
3 を を ADP 助詞-格助詞 _ 2 case _ SpaceAfter=No|Translit=ヲ
4 治め 収める VERB 動詞-一般 _ 7 advcl _ SpaceAfter=No|Translit=オサメ
5 ん む AUX 助動詞 _ 4 aux _ SpaceAfter=No|Translit=ン
6 と と ADP 助詞-格助詞 _ 4 case _ SpaceAfter=No|Translit=ト
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
8 者 者 NOUN 名詞-普通名詞-一般 _ 14 nsubj _ SpaceAfter=No|Translit=モノ
9 は は ADP 助詞-係助詞 _ 8 case _ SpaceAfter=No|Translit=ハ
10 先づ 先ず ADV 副詞 _ 14 advmod _ SpaceAfter=No|Translit=マヅ
11 其 其の DET 連体詞 _ 12 det _ SpaceAfter=No|Translit=ソノ
12 家 家 NOUN 名詞-普通名詞-一般 _ 14 obj _ SpaceAfter=No|Translit=ウチ
13 を を ADP 助詞-格助詞 _ 12 case _ SpaceAfter=No|Translit=ヲ
14 齊ふ 整える VERB 動詞-一般 _ 0 root _ SpaceAfter=No|Translit=トトノフ
>>> t=s[7]
>>> print(t.id,t.form,t.lemma,t.upos,t.xpos,t.feats,t.head.id,t.deprel,t.deps,t.misc)
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
>>> print(s.to_tree())
其 <══╗ det(決定詞)
國 ═╗═╝<╗ obj(目的語)
を <╝ ║ case(格表示)
治め ═╗═╗═╝<╗ advcl(連用修飾節)
ん <╝ ║ ║ aux(動詞補助成分)
と <══╝ ║ case(格表示)
欲する ═══════╝<╗ acl(連体修飾節)
者 ═╗═══════╝<╗ nsubj(主語)
は <╝ ║ case(格表示)
先づ <══════╗ ║ advmod(連用修飾語)
其 <══╗ ║ ║ det(決定詞)
家 ═╗═╝<╗ ║ ║ obj(目的語)
を <╝ ║ ║ ║ case(格表示)
齊ふ ═════╝═╝═══╝ root(親)
>>> f=open("trial.svg","w")
>>> f.write(s.to_svg())
>>> f.close()
unidic2ud.load(UniDic,UDPipe) loads a natural language processor pipeline, which uses UniDic for tokenizer POS-tagger and lemmatizer, then uses UDPipe for dependency-parser. The default UDPipe is UDPipe="japanese-modern". Available UniDic options are:
UniDic="gendai": Use 現代書き言葉UniDic.UniDic="spoken": Use 現代話し言葉UniDic.UniDic="novel": Use 近現代口語小説UniDic.UniDic="qkana": Use 旧仮名口語UniDic.UniDic="kindai": Use 近代文語UniDic.UniDic="kinsei": Use 近世江戸口語UniDic.UniDic="kyogen": Use 中世口語UniDic.UniDic="wakan": Use 中世文語UniDic.UniDic="wabun": Use 中古和文UniDic.UniDic="manyo": Use 上代語UniDic.UniDic=None: UseUDPipefor tokenizer, POS-tagger, lemmatizer, and dependency-parser.
unidic2ud.UniDic2UDEntry.to_tree() has an option to_tree(BoxDrawingWidth=2) for old terminals, whose Box Drawing characters are "fullwidth".
You can simply use unidic2ud on the command line:
echo 其國を治めんと欲する者は先づ其家を齊ふ | unidic2ud -U kindai>>> import unidic2ud.cabocha as CaboCha
>>> c=CaboCha.Parser("kindai")
>>> s=c.parse("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(s.toString(CaboCha.FORMAT_TREE_LATTICE))
其-D
國を-D
治めんと-D
欲する-D
者は-------D
先づ-----D
其-D |
家を-D
齊ふ
EOS
* 0 1D 0/0 0.000000
其 連体詞,*,*,*,*,*,其の,ソノ,*,DET O 1<-det-2
* 1 2D 0/1 0.000000
國 名詞,普通名詞,一般,*,*,*,国,クニ,*,NOUN O 2<-obj-4
を 助詞,格助詞,*,*,*,*,を,ヲ,*,ADP O 3<-case-2
* 2 3D 0/1 0.000000
治め 動詞,一般,*,*,*,*,収める,オサメ,*,VERB O 4<-advcl-7
ん 助動詞,*,*,*,*,*,む,ン,*,AUX O 5<-aux-4
と 助詞,格助詞,*,*,*,*,と,ト,*,ADP O 6<-case-4
* 3 4D 0/0 0.000000
欲する 動詞,一般,*,*,*,*,欲する,ホッスル,*,VERB O 7<-acl-8
* 4 8D 0/1 0.000000
者 名詞,普通名詞,一般,*,*,*,者,モノ,*,NOUN O 8<-nsubj-14
は 助詞,係助詞,*,*,*,*,は,ハ,*,ADP O 9<-case-8
* 5 8D 0/0 0.000000
先づ 副詞,*,*,*,*,*,先ず,マヅ,*,ADV O 10<-advmod-14
* 6 7D 0/0 0.000000
其 連体詞,*,*,*,*,*,其の,ソノ,*,DET O 11<-det-12
* 7 8D 0/1 0.000000
家 名詞,普通名詞,一般,*,*,*,家,ウチ,*,NOUN O 12<-obj-14
を 助詞,格助詞,*,*,*,*,を,ヲ,*,ADP O 13<-case-12
* 8 -1D 0/0 0.000000
齊ふ 動詞,一般,*,*,*,*,整える,トトノフ,*,VERB O 14<-root
EOS
>>> for c in [s.chunk(i) for i in range(s.chunk_size())]:
... if c.link>=0:
... print(c,"->",s.chunk(c.link))
...
其 -> 國を
國を -> 治めんと
治めんと -> 欲する
欲する -> 者は
者は -> 齊ふ
先づ -> 齊ふ
其 -> 家を
家を -> 齊ふCaboCha.Parser(UniDic) is an alias for unidic2ud.load(UniDic,UDPipe="japanese-modern"), and its default is UniDic=None. CaboCha.Tree.toString(format) has five available formats:
CaboCha.FORMAT_TREE: tree (numbered as 0)CaboCha.FORMAT_LATTICE: lattice (numbered as 1)CaboCha.FORMAT_TREE_LATTICE: tree + lattice (numbered as 2)CaboCha.FORMAT_XML: XML (numbered as 3)CaboCha.FORMAT_CONLL: Universal Dependencies CoNLL-U (numbered as 4)
You can simply use udcabocha on the command line:
echo 其國を治めんと欲する者は先づ其家を齊ふ | udcabocha -U kindai -f 2-U UniDic specifies UniDic. -f format specifies the output format in 0 to 4 above (default is -f 0) and in 5 to 8 below:
-f 5:to_tree()-f 6:to_tree(BoxDrawingWidth=2)-f 7:to_svg()-f 8: raw DOT graph through Immediate Catena Analysis
Try notebook for Google Colaboratory.
If you have already installed spaCy 2.1.0 or later, you can use UniDic via spaCy Language pipeline.
>>> import unidic2ud.spacy
>>> nlp=unidic2ud.spacy.load("kindai")
>>> d=nlp("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(unidic2ud.spacy.to_conllu(d))
# text = 其國を治めんと欲する者は先づ其家を齊ふ
1 其 其の DET 連体詞 _ 2 det _ SpaceAfter=No|Translit=ソノ
2 國 国 NOUN 名詞-普通名詞-一般 _ 4 obj _ SpaceAfter=No|Translit=クニ
3 を を ADP 助詞-格助詞 _ 2 case _ SpaceAfter=No|Translit=ヲ
4 治め 収める VERB 動詞-一般 _ 7 advcl _ SpaceAfter=No|Translit=オサメ
5 ん む AUX 助動詞 _ 4 aux _ SpaceAfter=No|Translit=ン
6 と と ADP 助詞-格助詞 _ 4 case _ SpaceAfter=No|Translit=ト
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
8 者 者 NOUN 名詞-普通名詞-一般 _ 14 nsubj _ SpaceAfter=No|Translit=モノ
9 は は ADP 助詞-係助詞 _ 8 case _ SpaceAfter=No|Translit=ハ
10 先づ 先ず ADV 副詞 _ 14 advmod _ SpaceAfter=No|Translit=マヅ
11 其 其の DET 連体詞 _ 12 det _ SpaceAfter=No|Translit=ソノ
12 家 家 NOUN 名詞-普通名詞-一般 _ 14 obj _ SpaceAfter=No|Translit=ウチ
13 を を ADP 助詞-格助詞 _ 12 case _ SpaceAfter=No|Translit=ヲ
14 齊ふ 整える VERB 動詞-一般 _ 0 root _ SpaceAfter=No|Translit=トトノフ
>>> t=d[6]
>>> print(t.i+1,t.orth_,t.lemma_,t.pos_,t.tag_,t.head.i+1,t.dep_,t.whitespace_,t.norm_)
7 欲する 欲する VERB 動詞-一般 8 acl ホッスル
>>> from deplacy.deprelja import deprelja
>>> for b in unidic2ud.spacy.bunsetu_spans(d):
... for t in b.lefts:
... print(unidic2ud.spacy.bunsetu_span(t),"->",b,"("+deprelja[t.dep_]+")")
...
其 -> 國を (決定詞)
國を -> 治めんと (目的語)
治めんと -> 欲する (連用修飾節)
欲する -> 者は (連体修飾節)
其 -> 家を (決定詞)
者は -> 齊ふ (主語)
先づ -> 齊ふ (連用修飾語)
家を -> 齊ふ (目的語)unidic2ud.spacy.load(UniDic,parser) loads a spaCy pipeline, which uses UniDic for tokenizer POS-tagger and lemmatizer (as shown above), then uses parser for dependency-parser. The default parser is parser="japanese-modern" and available options are:
parser="ja_core_news_sm": Use spaCy Japanese model (small).parser="ja_core_news_md": Use spaCy Japanese model (middle).parser="ja_core_news_lg": Use spaCy Japanese model (large).parser="ja_ginza": Use GiNZA.parser="japanese-gsd": Use UDPipe Japanese model.parser="stanza_ja": Use Stanza Japanese model.
Tar-ball is available for Linux, and is installed by default when you use pip:
pip install unidic2udBy default installation, UniDic is invoked through Web APIs. If you want to invoke them locally and faster, you can download UniDic which you use just as follows:
python -m unidic2ud download kindai
python -m unidic2ud dictlistLicenses of dictionaries and models are: GPL/LGPL/BSD for gendai and spoken; CC BY-NC-SA 4.0 for others.
Make sure to get gcc-g++ python37-pip python37-devel packages, and then:
pip3.7 install unidic2udUse python3.7 command in Cygwin instead of python.
!pip install unidic2udResults of 舞姬/雪國/荒野より-Benchmarks
| 舞姬 | LAS | MLAS | BLEX |
|---|---|---|---|
| UniDic="kindai" | 81.13 | 70.37 | 77.78 |
| UniDic="qkana" | 79.25 | 70.37 | 77.78 |
| UniDic="kinsei" | 72.22 | 60.71 | 64.29 |
| 雪國 | LAS | MLAS | BLEX |
|---|---|---|---|
| UniDic="qkana" | 89.29 | 85.71 | 81.63 |
| UniDic="kinsei" | 89.29 | 85.71 | 77.55 |
| UniDic="kindai" | 84.96 | 81.63 | 77.55 |
| 荒野より | LAS | MLAS | BLEX |
|---|---|---|---|
| UniDic="kindai" | 76.44 | 61.54 | 53.85 |
| UniDic="qkana" | 75.39 | 61.54 | 53.85 |
| UniDic="kinsei" | 71.88 | 58.97 | 51.28 |
Koichi Yasuoka (安岡孝一)
- 安岡孝一: 形態素解析部の付け替えによる近代日本語(旧字旧仮名)の係り受け解析, 情報処理学会研究報告, Vol.2020-CH-124「人文科学とコンピュータ」, No.3 (2020年9月5日), pp.1-8.
- 安岡孝一: 漢日英Universal Dependencies平行コーパスとその差異, 人文科学とコンピュータシンポジウム「じんもんこん2019」論文集 (2019年12月), pp.43-50.