feat: Vertex AI Search Tuning sample notebook #1944
Conversation
…ure of Vertex AI Search
…ure of Vertex AI Search - V_1_0_0_ALPHA
There was a problem hiding this comment.
Hello @JincheolKim, I'm Gemini Code Assist1! I'm currently reviewing this pull request and will post my feedback shortly. In the meantime, here's a summary to help you and other reviewers quickly get up to speed!
Summary of Changes
This pull request introduces a new sample notebook for Vertex AI Search Tuning. The notebook guides users through the process of tuning Vertex AI Search with sample data, including preparing data in JSONL and TSV formats, configuring a search tuning job, and submitting it to Vertex AI. The notebook also includes steps for creating a data store and search app, and testing the tuned search app endpoint. The author also included FAQ documents from the Kubernetes project, and transformed them into PDF format for use with Vertex AI Search.
Highlights
- New Notebook: Adds a new notebook,
sample-search-tuning.ipynb, demonstrating Vertex AI Search Tuning. - Data Preparation: Includes code to generate training and test datasets from Kubernetes FAQ markdown files, converting them to JSONL and TSV formats.
- Datastore and Search App Creation: Provides steps and code for creating a data store and search app using the Vertex AI Search SDK.
- Search Tuning Configuration: Demonstrates how to configure and submit a search tuning job to Vertex AI.
- PDF Conversion: Includes steps to convert Markdown files to PDF format for compatibility with Vertex AI Search.
- Clean Up: Includes code to clean up resources created during the notebook execution.
Changelog
Click here to see the changelog
- search/vertexai-search-options/vertexai-search-tuning/sample-search-tuning.ipynb
- Initial commit of the sample notebook.
- Includes sections for data preparation, datastore creation, search app creation, search tuning configuration, and testing.
- Provides code examples and explanations for each step of the process.
- Includes clean up steps to remove created resources.
- search/vertexai-search-options/vertexai-search-tuning/tuning_data/FAQ-Kubernetes-Client.md
- Added FAQ document for Kubernetes Client
- search/vertexai-search-options/vertexai-search-tuning/tuning_data/FAQ.md
- Added FAQ document for Kubernetes
- search/vertexai-search-options/vertexai-search-tuning/tuning_data/README.md
- Added README document for Kubernetes
- search/vertexai-search-options/vertexai-search-tuning/tuning_data/query_file.jsonl
- Added query file for Kubernetes
- search/vertexai-search-options/vertexai-search-tuning/tuning_data/test_data.tsv
- Added test data file for Kubernetes
- search/vertexai-search-options/vertexai-search-tuning/tuning_data/training_data.tsv
- Added training data file for Kubernetes
Using Gemini Code Assist
The full guide for Gemini Code Assist can be found on our documentation page, here are some quick tips.
Invoking Gemini
You can request assistance from Gemini at any point in your pull request via creating an issue comment (i.e. comment on the pull request page) using either /gemini <command> or @gemini-code-assist <command>. Below is a summary of the supported commands.
| Feature | Command | Description |
|---|---|---|
| Code Review | /gemini review |
Performs a code review for the current pull request in its current state. |
| Pull Request Summary | /gemini summary |
Provides a summary of the current pull request in its current state. |
| Comment | @gemini-code-assist | Responds in comments when explicitly tagged, both in issue comments and review comments. |
| Help | /gemini help |
Displays a list of available commands. |
Customization
To customize Gemini Code Assist for GitHub experience, repository maintainers can create a configuration file and/or provide a custom code review style guide (such as PEP-8 for Python) by creating and adding files to a .gemini/ folder in the base of the repository. Detailed instructions can be found here.
Limitations & Feedback
Gemini Code Assist is currently in preview and may make mistakes. Please leave feedback on any instances where its feedback is incorrect or counter productive. You can react with 👍 and 👎 on @gemini-code-assist comments to provide feedback.
You can also get AI-powered code generation, chat, as well as code reviews directly in the IDE at no cost with the Gemini Code Assist IDE Extension.
In clouds of data, search does reside,
Relevance sought, with nowhere to hide.
Tune the LLM's ear,
Make the answers clear,
Find the right doc, with knowledge applied.
Footnotes
-
Review the Privacy Notices, Generative AI Prohibited Use Policy, Terms of Service, and learn how to configure Gemini Code Assist in GitHub here. Gemini can make mistakes, so double check it and use code with caution. ↩
There was a problem hiding this comment.
Code Review
The notebook introduces a workflow for tuning Vertex AI Search using FAQ data from Kubernetes. It covers data preparation, datastore updates, search app rebuilding, and evaluation. The notebook is comprehensive, but there are some areas where improvements can be made to enhance clarity and robustness.
Summary of Findings
- TODO comments: The notebook contains a TODO comment that should be addressed by uncommenting the variables or providing a default implementation.
- Inconsistent code execution: The notebook contains code that is commented out for MacOS but not for Linux, which could lead to confusion for users on different operating systems.
- Missing Error Handling: The notebook lacks explicit error handling for cloud storage operations, which could lead to unexpected behavior if these operations fail.
Merge Readiness
The notebook provides a good starting point for users to understand Vertex AI Search Tuning. However, addressing the TODO comment and adding error handling would improve the notebook's completeness and robustness. I am unable to directly approve this pull request, and recommend that others review and approve this code before merging. Given the presence of a high severity comment, I recommend that the pull request not be merged until this is addressed.
| "# TODO(developer): Uncomment these variables before running the sample.\n", | ||
| "data_store_id = f\"{SEARCH_DATASTORE_ID}\"\n", | ||
| "corpus_data_path = f\"{TUNING_DATA_PATH_REMOTE}/corpus_file.jsonl\"\n", | ||
| "query_data_path = f\"{TUNING_DATA_PATH_REMOTE}/query_file.jsonl\"\n", | ||
| "train_data_path = f\"{TUNING_DATA_PATH_REMOTE}/training_data.tsv\"\n", | ||
| "test_data_path = f\"{TUNING_DATA_PATH_REMOTE}/test_data.tsv\"" |
There was a problem hiding this comment.
This section is marked as TODO. Either uncomment these variables or provide a default implementation. Leaving them commented will cause the notebook to fail if a user tries to run it without modification. It's also not clear what the user should set these variables to.
data_store_id = f"{SEARCH_DATASTORE_ID}"
corpus_data_path = f"{TUNING_DATA_PATH_REMOTE}/corpus_file.jsonl"
query_data_path = f"{TUNING_DATA_PATH_REMOTE}/query_file.jsonl"
train_data_path = f"{TUNING_DATA_PATH_REMOTE}/training_data.tsv"
test_data_path = f"{TUNING_DATA_PATH_REMOTE}/test_data.tsv"
| "# For Linux\n", | ||
| "!pandoc --pdf-engine=pdflatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf\n", | ||
| "!pandoc --pdf-engine=pdflatex FAQ.md -o FAQ.pdf\n", | ||
| "!pandoc --pdf-engine=pdflatex README.md -o README.pdf\n", | ||
| "## For MacOS\n", | ||
| "#!pandoc --pdf-engine=xelatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf\n", | ||
| "#!pandoc --pdf-engine=xelatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf\n", | ||
| "#!pandoc --pdf-engine=xelatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf" |
There was a problem hiding this comment.
Consider using the same approach for MacOS as for Linux, or provide a conditional execution based on the OS to avoid confusion. What's the reasoning for commenting out these lines for MacOS?
| "!gcloud storage cp \"{TUNING_DATA_PATH_LOCAL}/*.pdf\" \"{SEARCH_DATASTORE_PATH_REMOTE}\"\n", | ||
| "!gcloud storage ls \"{SEARCH_DATASTORE_PATH_REMOTE}\"" |
There was a problem hiding this comment.
Consider adding error handling to the cloud storage copy operations. If these operations fail, the notebook may not function correctly, and the user will not know why.
| " ClientOptions(api_endpoint=f\"{location}-discoveryengine.googleapis.com\")\n", | ||
| " if location != \"global\"\n", |
There was a problem hiding this comment.
Consider adding error handling to the cloud storage copy operations. If these operations fail, the notebook may not function correctly, and the user will not know why.
|
Would you give me a guidance to resolve the failures from Check spelling checks during the PR process? Thank you very much. |
There was a problem hiding this comment.
Remove all of the duplicate files.
Move the Notebook to a folder called search/tuning.
Title it vertex-ai-search-tuning.ipynb
Change the Image link to be https://storage.googleapis.com/github-repo/generative-ai/search/tuning/images/key_user_journey_search_tuning.png
Remove all of the tuning data from this PR, and use the data from this public GCS Bucket gs://github-repo/generative-ai/search/tuning/tuning_data/ Either have the users pull directly from this Bucket for the tuning job, or have them create the bucket and do gsutil cp to copy the data into their own bucket from this one.
Also, be sure to fix the spelling and lint errors
|
Please create a subfolder named "awesome_rlhf" under the "gs://github-repo/generative-ai/search/tuning" subfolder. I will move all of the data under the public bucket. Thank you. |
Please create a subfolder named "awesome_rlhf" under the "gs://github-repo/generative-ai/search/tuning" subfolder or would you be able to give me the ""Create/Delete/Read/Write" right to the "gs://github-repo/generative-ai/search/tuning" folder to create the subfolder? I need to move all of the test data under the subfolder to make the asset complied with your comments. |
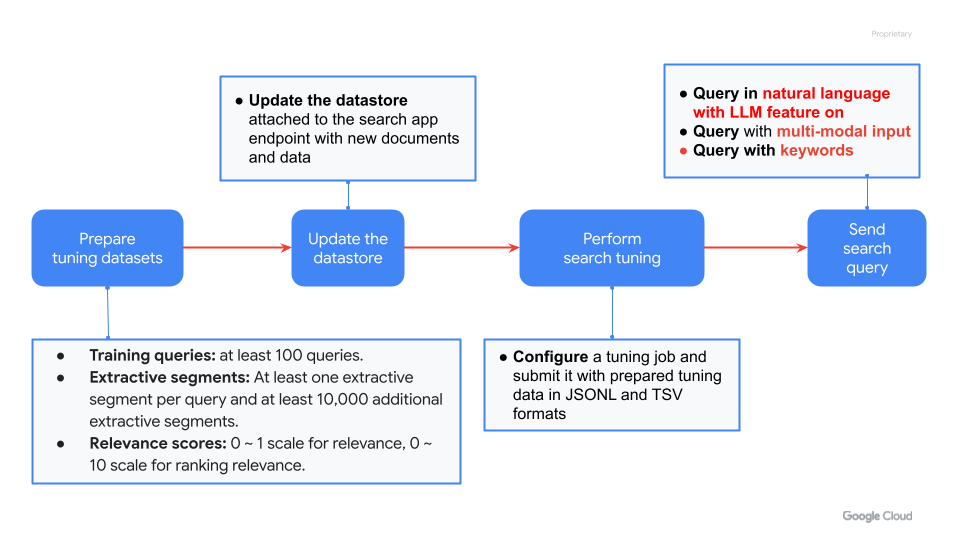
…ets were added. 1. Removed all of the duplicate files. 2. Moved the Notebook to a folder called search/tuning. 3. Retitled the notebook to "vertex-ai-search-tuning.ipynb". 4. Changed the Image link to be "https://storage.googleapis.com/github-repo/generative-ai/search/tuning/images/key_user_journey_search_tuning.png" 5. Removed all of the tuning data from this PR, and moved them to the public GCS Bucket gs://github-repo/generative-ai/search/tuning/tuning_data/, The logic in the notebook has been changed together corresponding to the changes.
{kind=link}
…ets were added. 1. Added jincheolkim@ to the "CODEOWNDERS" for search/tuning. 2. Moved the location of the contributed assets to search/tuning and detached all of the old files from the old path vertexai-search-options/vertexai-search-tuning from the working tree. 3. Removed all of the test data from the repository.
…ets were added. 1. Wrong spells of the text are corrected.
…ets were added. 1. The spell checking exception (vertexai-search-tuning.ipynb) has been added.
…ets were added. 1. The spell-checking exception is corrected again. 2. Added 4 exceptional words (FHIR, Jincheol, reidx, tscore)
|
All of the requested corrections and actions are completed and committed. Please review them again. Thank you. |
| "def generate_source_dataset(\n", | ||
| " source_file, corpus_filepath, query_filepath, cleanup_at_start=True\n", | ||
| "):\n", |
There was a problem hiding this comment.
Add typing for function parameters and return values.
There was a problem hiding this comment.
Added descriptions on the helper function arguments, return values, and their functions.
| " import logging\n", | ||
| " import os\n", |
There was a problem hiding this comment.
Move all imports to a dedicated section at the top of the notebook
There was a problem hiding this comment.
All of the imports were aggregated to a cell in the section "Set Google Cloud project information and initialize Vertex AI SDK for Python".
| "# For Linux\n", | ||
| "!pandoc --pdf-engine=pdflatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf\n", | ||
| "!pandoc --pdf-engine=pdflatex FAQ.md -o FAQ.pdf\n", | ||
| "!pandoc --pdf-engine=pdflatex README.md -o README.pdf\n", | ||
| "## For macOS\n", | ||
| "#!pandoc --pdf-engine=xelatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf\n", | ||
| "#!pandoc --pdf-engine=xelatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf\n", | ||
| "#!pandoc --pdf-engine=xelatex FAQ-Kubernetes-Client.md -o FAQ-Kubernetes-Client.pdf" |
There was a problem hiding this comment.
You can check with Python for which platform the user is running on so the user doesn't need to uncomment lines.
This notebook has an example: https://github.com/GoogleCloudPlatform/generative-ai/blob/main/audio/speech/use-cases/storytelling/storytelling.ipynb
There was a problem hiding this comment.
Added a conditional branch statements with the value of the platform.system() function.
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "!git clone https://gitlab.com/jincheolkim/awesome-rlhf.git\n", |
There was a problem hiding this comment.
Should users be cloning from your Gitlab repo? Will public users have permission for this? Can this be replaced with the data from the GCS bucket?
There was a problem hiding this comment.
Corrected as you suggested. All of the data will be downloaded from the GCS bucket.
| "from google.api_core.client_options import ClientOptions\n", | ||
| "from google.cloud import discoveryengine\n", |
There was a problem hiding this comment.
Move all imports to a dedicated section at the top of the notebook.
There was a problem hiding this comment.
All of the imports were aggregated to a cell in the section "Set Google Cloud project information and initialize Vertex AI SDK for Python".
| " client_options = (\n", | ||
| " ClientOptions(api_endpoint=f\"{location}-discoveryengine.googleapis.com\")\n", | ||
| " if location != \"global\"\n", | ||
| " else None\n", | ||
| " )\n", | ||
| "\n", |
There was a problem hiding this comment.
I'd recommend making a single ClientOptions object that all of these methods can use.
Also, move helper functions to a dedicated section at the top so that the rest of the notebook can just focus on the key steps, not the full code needed.
There was a problem hiding this comment.
client_option is defined once at the "Helper functions to facilitate the following steps" section in the earlier part of the notebook.
| "# Create a client\n", | ||
| "client = discoveryengine.DocumentServiceClient(client_options=client_options)" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": null, | ||
| "metadata": { | ||
| "id": "33e54f26212a" | ||
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "# The full resource name of the search engine branch.\n", | ||
| "# e.g. projects/{project}/locations/{location}/dataStores/{data_store_id}/branches/{branch}\n", | ||
| "parent = client.branch_path(\n", | ||
| " project=PROJECT_ID,\n", | ||
| " location=LOCATION,\n", | ||
| " data_store=SEARCH_DATASTORE_ID,\n", |
There was a problem hiding this comment.
Since you have the other VAIS calls in dedicated methods, can you make this one a dedicated method as well?
There was a problem hiding this comment.
The logic was implemented as the function "import_documents" as other helper functions in the "Helper Functions" section.
| "! mkdir $TUNING_DATA_PATH_LOCAL\n", | ||
| "! gcloud storage cp $TUNING_DATA_PATH_SOURCE/* $TUNING_DATA_PATH_LOCAL" |
There was a problem hiding this comment.
Why is this data being copied locally? Is that absolutely needed? Could the GCS path be given directly to VAIS?
There was a problem hiding this comment.
These data are used to extract the corpus and the query JSONL data, the training and the test TSV data locally. Given that, those files are downloaded to a local folder, preprocessed, and then uploaded to the data store again. This logic is a correct logic.
| "!gcloud storage cp \"{TUNING_DATA_PATH_LOCAL}/*.pdf\" \"{SEARCH_DATASTORE_PATH_REMOTE}\"\n", | ||
| "!gcloud storage ls \"{SEARCH_DATASTORE_PATH_REMOTE}\"" |
There was a problem hiding this comment.
Similar to above, do these files need to be copied locally?
There was a problem hiding this comment.
Same as in the above. This part is to upload the PDF files corresponding to the JSONL and the TSV format files to generate the index in addition to the base dataset.
| "def delete_engine(\n", | ||
| " project_id: str,\n", | ||
| " location: str,\n", | ||
| " engine_id: str,\n", | ||
| ") -> str:\n", |
There was a problem hiding this comment.
Same as above, move these helper methods to a dedicated section at the top
There was a problem hiding this comment.
This "delete_engine" helper function was also moved to the section "Helper Functions".
…#1944 1. Added descriptions on the helper function arguments, return values, and their functions. (generate_source_dataset, generate_training_test_dataset) 2. All of the imports were aggregated to a cell in the section "Set Google Cloud project information and initialize Vertex AI SDK for Python". 3. In the cell executing pandoc to transform .md text files to PDF files, a conditional branch statement with the value of the platform.system() function was added. 4. Parts which are downloading from a personal github repository were all removed and corrected to be downloaded from the GCS bucket, gs://github-repo/generative-ai/search/tuning. 5. All of the imports were aggregated to a cell in the section "Set Google Cloud project information and initialize Vertex AI SDK for Python". 6. client_option is defined once at the "Helper functions to facilitate the following steps" section in the earlier part of the notebook. 7. The logic in the section “Creating a data store for a search app with the cloud storage bucket with PDF documents” was implemented as the function "import_documents" as other helper functions in the "Helper Functions" section. 8. This "delete_engine" helper function was also moved to the section "Helper Functions".
…atform#1944 1. Added descriptions on the helper function arguments, return values, and their functions. (generate_source_dataset, generate_training_test_dataset) 2. All of the imports were aggregated to a cell in the section "Set Google Cloud project information and initialize Vertex AI SDK for Python". 3. In the cell executing pandoc to transform .md text files to PDF files, a conditional branch statement with the value of the platform.system() function was added. 4. Parts which are downloading from a personal github repository were all removed and corrected to be downloaded from the GCS bucket, gs://github-repo/generative-ai/search/tuning. 5. All of the imports were aggregated to a cell in the section "Set Google Cloud project information and initialize Vertex AI SDK for Python". 6. client_option is defined once at the "Helper functions to facilitate the following steps" section in the earlier part of the notebook. 7. The logic in the section “Creating a data store for a search app with the cloud storage bucket with PDF documents” was implemented as the function "import_documents" as other helper functions in the "Helper Functions" section. 8. This "delete_engine" helper function was also moved to the section "Helper Functions".
…atform#1944 1. Spelling errors corrected.
1. Indentation tabs are adjusted in function doc comments. 2. Lines are added before comments just after function signatures.
…com:JincheolKim/generative-ai into vertexai-search-tuning-sample_V_1_0_0_ALPHA
…e changed to avoid Lint errors.
|
All of the requested fix are corrected and revised. Your review and merge would be greatly appreciated.
|
Contributing an additional notebook for the "Vertex AI Search Tuning" feature to help users try it with a sample notebook.
CONTRIBUTINGGuide.CODEOWNERSfor the file(s).nox -s formatfrom the repository root to format).No issue fix for this PR.