Applied multinomial naive bayes algorithm to predict sentiment based on text data. In this project we built model to perform sentiment analysis for alexa reviews on amazon to predict if customers are happy with the product or not
Natural language processing (NLP) can be used to build predictive models to perform sentiment analysis on social media posts and reviews and predict if customers are happy or not. NLP work by converting words into numbers and training a machine learning models to make predictions. That way, we can automatically know if our customers are happy or not without manually going through massive number of tweets or reviews.
In this project, we are going to use nlp for our predictive model to predict if customers are happy or not based on alexa reviews on amazon.
We used customer reviews dataset from kaggle that contains 3150 customer reviews on alexa product. The following is the first two rows of the dataset :
| rating | date | variation | verified_reviews | feedback |
|---|---|---|---|---|
| 5 | 31-Jul-18 | Charcoal Fabric | Love my Echo! | 1 |
| 5 | 31-Jul-18 | Charcoal Fabric | Loved it! | 1 |
- rating: Rating of the products
- date : Date of the review
- variation : Variation of the products
- verified_reviews : Customers review
- feedback : boolean to say whether a customers is happy or not (1 = positive, 0 = negative)
Fortunately we don't have any missing values
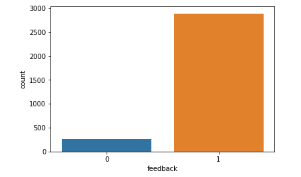
Majority of customers are happy with the products
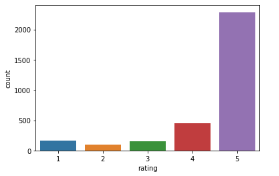
Majority of customers are giving 5 stars on product reviews
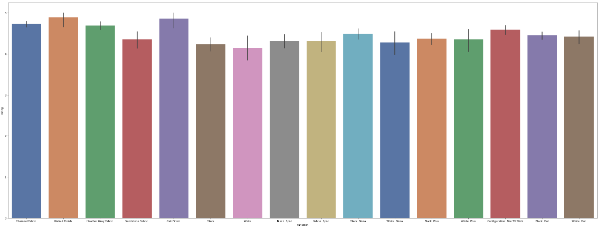
- Walnut Finish and Oak Finish is product variation with highest rating
- White is product variation with lowest rating
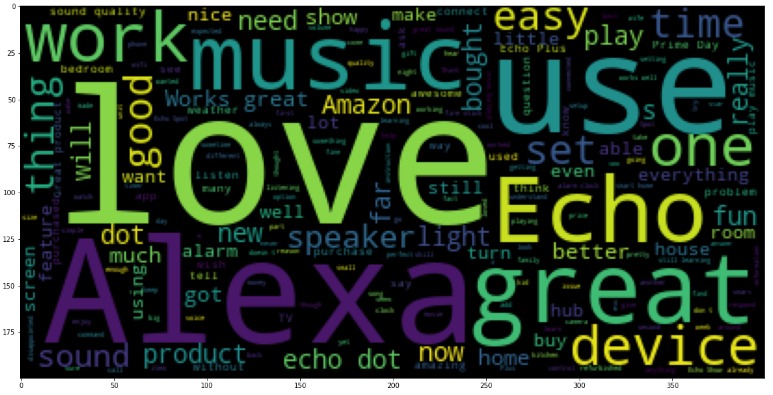
The wordcloud above tell us the words that appear the most on reviews of the products

The wordcloud above tell us the words that appear the most on negative reviews of the products
We drop rating and date columns because we don't need them for our predictive model.
We turn variation column into numerical data by creating dummies for variation column. The following is our variation dummies :

The next thing to do is drop variation column on reviews dataset and concatinate it with our variation dummies.
We use nltk library to define a pipeline to clean up all the messages. The pipeline will peforms the following :
- Remove punctuation (ex : , ! . ? / etc )
- Remove stopwords ( ex : i, you, them , we, etc)
The following is our customer reviews after we apply our pipeline :

Now we used count vectorizer to convert customer reviews into string data. The following is the result after we used count vectorizer to our data :

Finally we do the following before build the model :
- Concat review dataset with vectorized reviews column
- Drop verified_review and feedback columns
We split the dataset into X Train, X Test, Y Train, and Y Test. We used 80% of our data into training dataset and 20% of our data into testing dataset. After split the dataset, we train our data using a MultinomialNB algorithm.
The main evaluation metric that we are used are confusion matrix and F1 score. The F-score, also called the F1-score, is a measure of a model's accuracy on a dataset. We can say F1-score is model accuracy. Confusion matrix is performance measurement for machine learning classification problem where output can be two or more classes. It is a table with 4 different combinations of predicted and actual values.

Based on matrix above, we correctly classify around 5.700 positives feedback and 17 negatives feedback. We misclassify 31 negatives feedback and 10 positives feedback.

Table above shows that our logistic regression model have F1 Score of 0.93, it means accuracy of our Naive Bayes model is 93%
We split the dataset into X Train, X Test, Y Train, and Y Test. We used 80% of our data into training dataset and 20% of our data into testing dataset. After split the dataset, we train our data using a Logistic Regression Classifier algorithm.
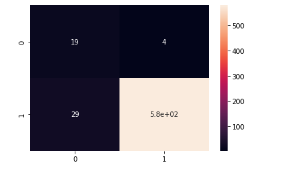
Based on matrix above, we correctly classify around 5.800 positives feedback and 19 negatives feedback. We misclassify 4 negatives feedback and 29 positives feedback.
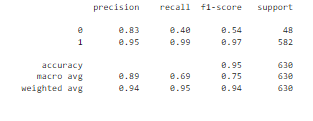
Table above shows that our logistic regression model have F1 Score of 0.94, it means accuracy of our Naive Bayes model is 94%
To predict if customers happy or not, we used two algorithms for our model. The following two algorithms are :
- Naive Bayes classifier with accuracy of 93%
- Logistic regression classifier with accuracy of 94%
We chose model with highest accuracy which is logistic regression with accuracy of 94%. Our model correctly predicted 5.800 positives feedback and 19 negatives feedback. Based on our model, we can tell that customers are quite happy with our products.