diff --git a/docs/data/transfer_queue.md b/docs/data/transfer_queue.md
new file mode 100644
index 00000000000..4532d42ed56
--- /dev/null
+++ b/docs/data/transfer_queue.md
@@ -0,0 +1,128 @@
+# TransferQueue Data System
+
+Last updated: 09/28/2025.
+
+This doc introduce [TransferQueue](https://github.com/TransferQueue/TransferQueue), an asynchronous streaming data management system for efficient post-training.
+
+
+ Overview
+
+TransferQueue is a high-performance data storage and transfer system with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows.
+
+
+  +
+
+
+
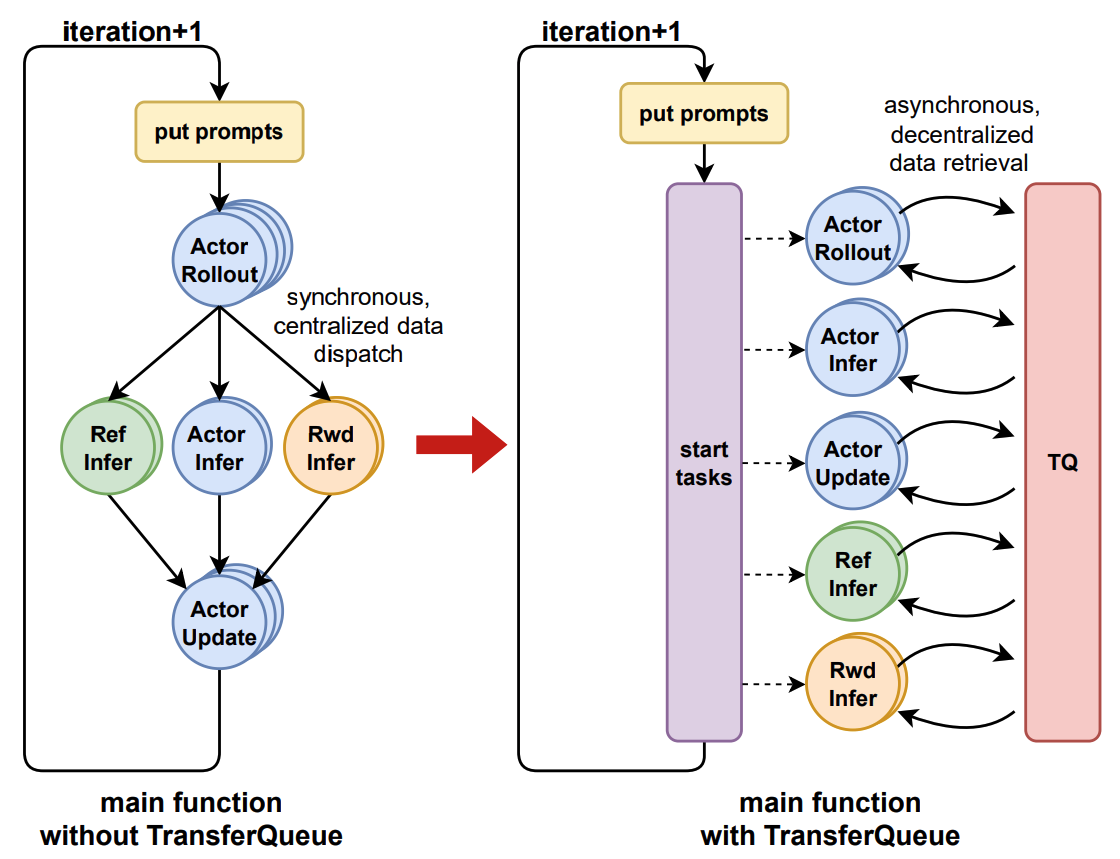
+TransferQueue offers **fine-grained, sample-level** data management capabilities, serving as a data gateway that decouples explicit data dependencies across computational tasks. This enables a divide-and-conquer approach, significantly simplifying the design of the algorithm controller.
+
+
+
+  +
+
+
+
+
+
+ Components
+
+
+
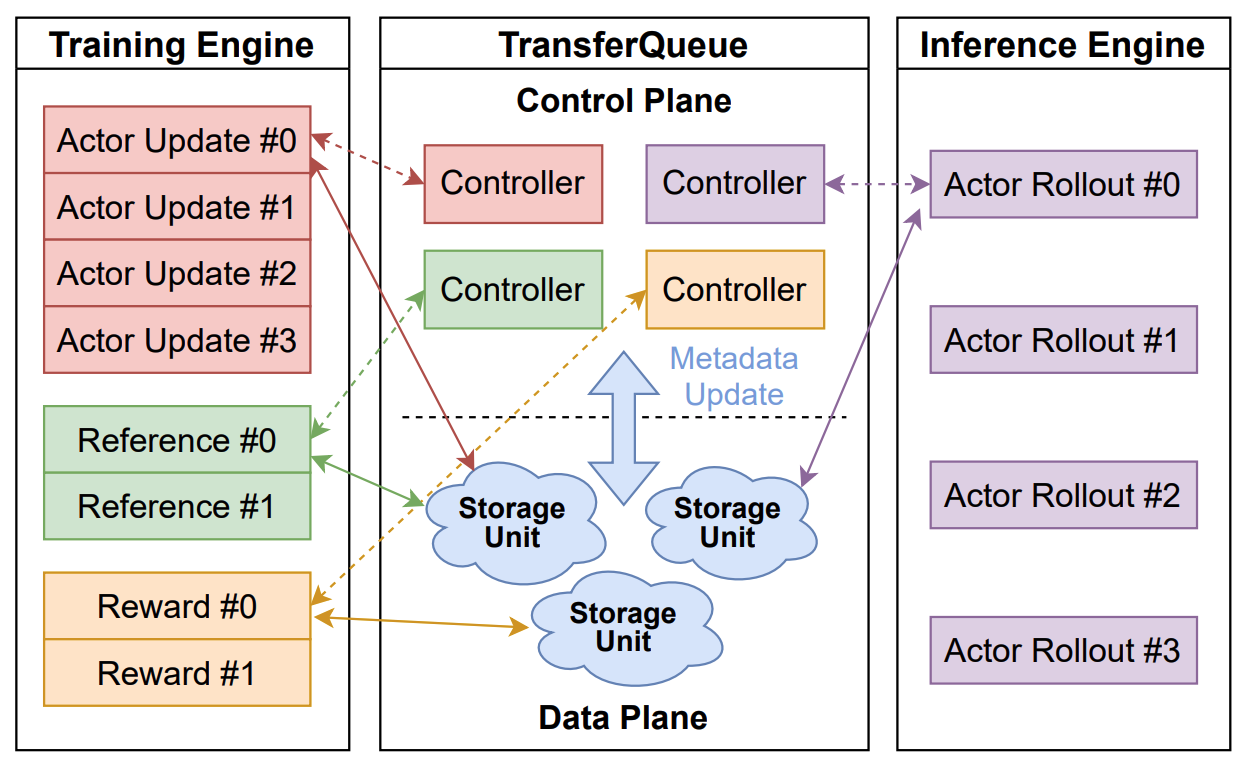
+### Control Plane: Panoramic Data Management
+
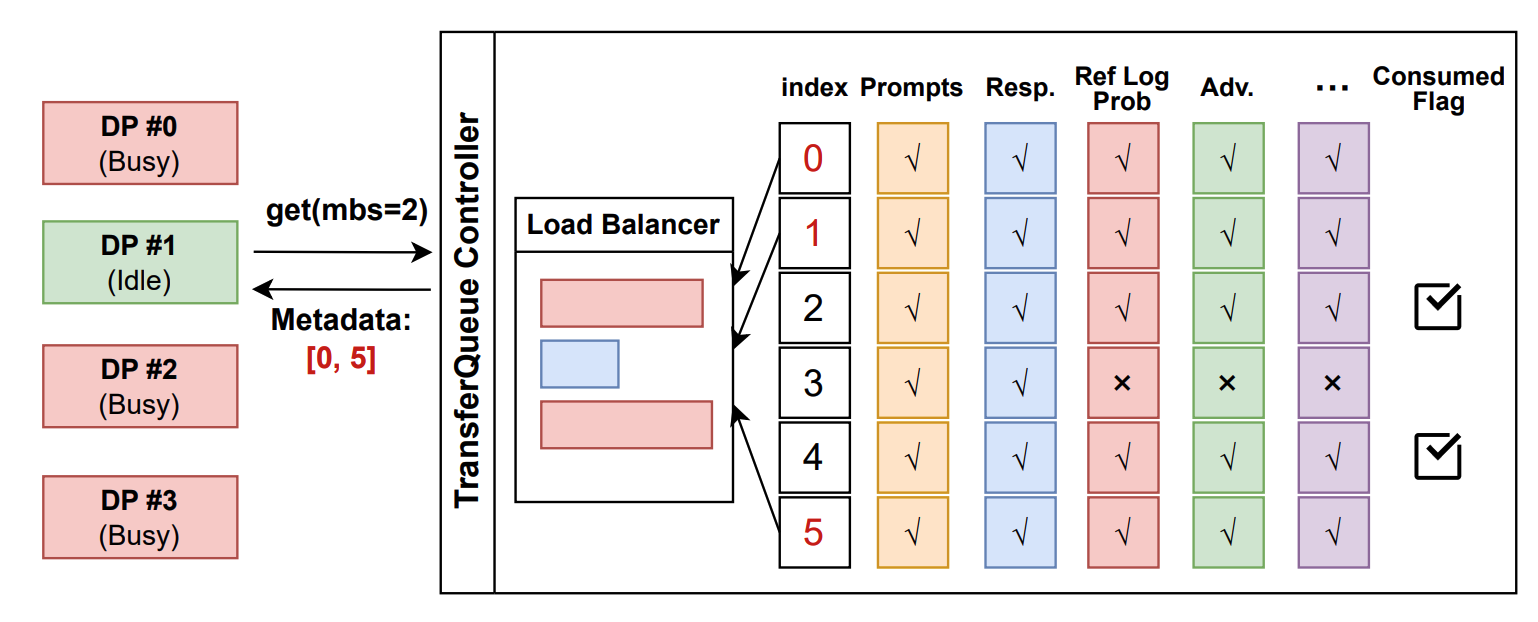
+In the control plane, `TransferQueueController` tracks the **production status** and **consumption status** of each training sample as metadata. When all the required data fields are ready (i.e., written to the `TransferQueueStorage`), we know that this data sample can be consumed by downstream tasks.
+
+For consumption status, we record the consumption records for each computational task (e.g., `generate_sequences`, `compute_log_prob`, etc.). Therefore, even different computation tasks require the same data field, they can consume the data independently without interfering with each other.
+
+
+
+  +
+
+
+
+> In the future, we plan to support **load-balancing** and **dynamic batching** capabilities in the control plane. Besides, we will support data management for disaggregated frameworks where each rank manages the data retrieval by itself, rather than coordinated by a single controller.
+
+### Data Plane: Distributed Data Storage
+
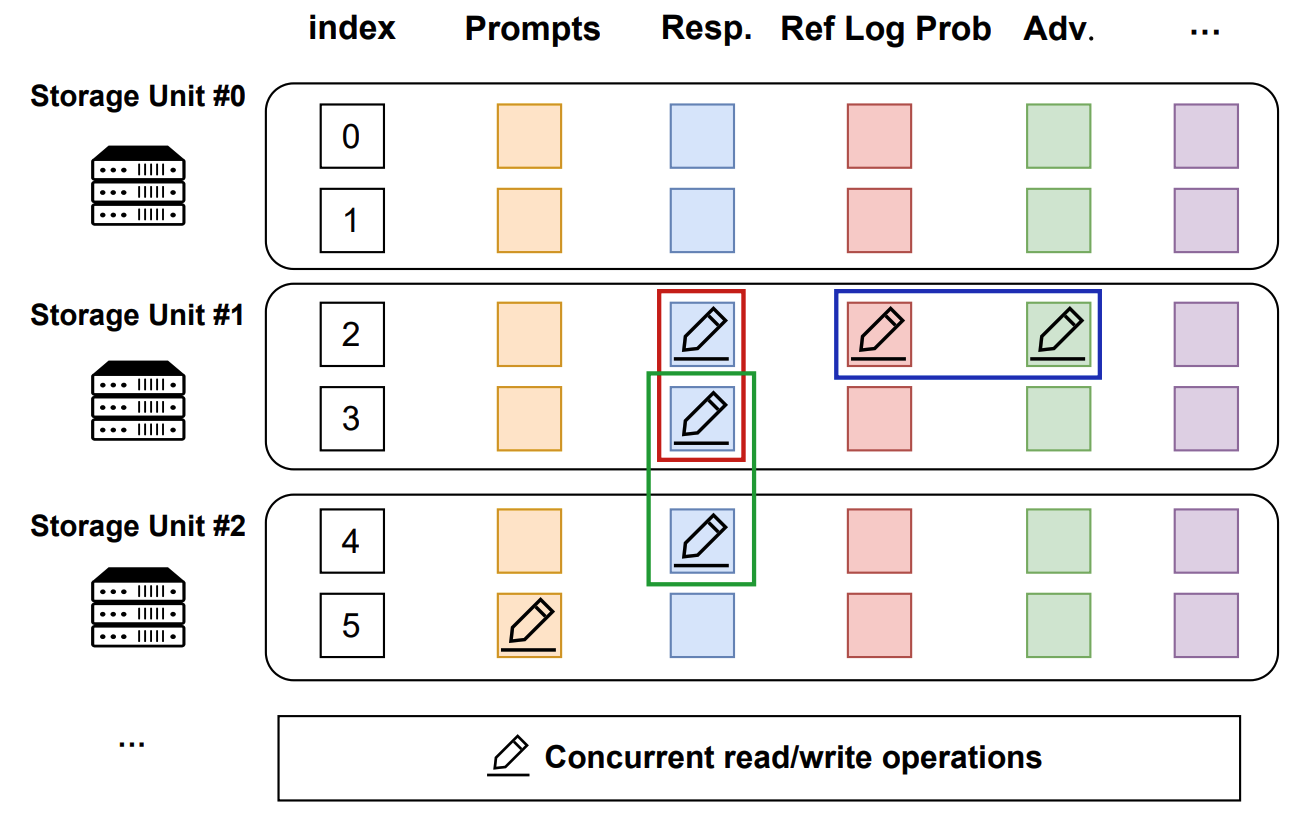
+In the data plane, `TransferQueueStorageSimpleUnit` serves as a naive storage unit based on CPU memory, responsible for the actual storage and retrieval of data. Each storage unit can be deployed on a separate node, allowing for distributed data management.
+
+`TransferQueueStorageSimpleUnit` employs a 2D data structure as follows:
+
+- Each row corresponds to a training sample, assigned a unique index within the corresponding global batch.
+- Each column represents the input/output data fields for computational tasks.
+
+This data structure design is motivated by the computational characteristics of the post-training process, where each training sample is generated in a relayed manner across task pipelines. It provides an accurate addressing capability, which allows fine-grained, concurrent data read/write operations in a streaming manner.
+
+
+  +
+
+
+
+> In the future, we plan to implement a **general storage abstraction layer** to support various storage backends. Through this abstraction, we hope to integrate high-performance storage solutions such as [MoonCakeStore](https://github.com/kvcache-ai/Mooncake) to support device-to-device data transfer through RDMA, further enhancing data transfer efficiency for large-scale data.
+
+
+### User Interface: Asynchronous & Synchronous Client
+
+
+The interaction workflow of TransferQueue system is as follows:
+
+1. A process sends a read request to the `TransferQueueController`.
+2. `TransferQueueController` scans the production and consumption metadata for each sample (row), and dynamically assembles a micro-batch metadata according to the load-balancing policy. This mechanism enables sample-level data scheduling.
+3. The process retrieves the actual data from distributed storage units using the metadata provided by the controller.
+
+To simplify the usage of TransferQueue, we have encapsulated this process into `AsyncTransferQueueClient` and `TransferQueueClient`. These clients provide both asynchronous and synchronous interfaces for data transfer, allowing users to easily integrate TransferQueue to their framework.
+
+
+> In the future, we will provide a `StreamingDataLoader` interface for disaggregated frameworks as discussed in [RFC#2662](https://github.com/volcengine/verl/discussions/2662). Leveraging this abstraction, each rank can automatically get its own data like `DataLoader` in PyTorch. The TransferQueue system will handle the underlying data scheduling and transfer logic caused by different parallelism strategies, significantly simplifying the design of disaggregated frameworks.
+
+
+ Show Cases
+
+### General Usage
+
+The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system.
+
+Core interfaces:
+
+- (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta
+- (async_)get_data(metadata:BatchMeta) -> TensorDict
+- (async_)put(data:TensorDict, metadata:BatchMeta, global_step)
+- (async_)clear(global_step: int)
+
+
+We will soon release a detailed tutorial and API documentation.
+
+
+### verl Example
+
+
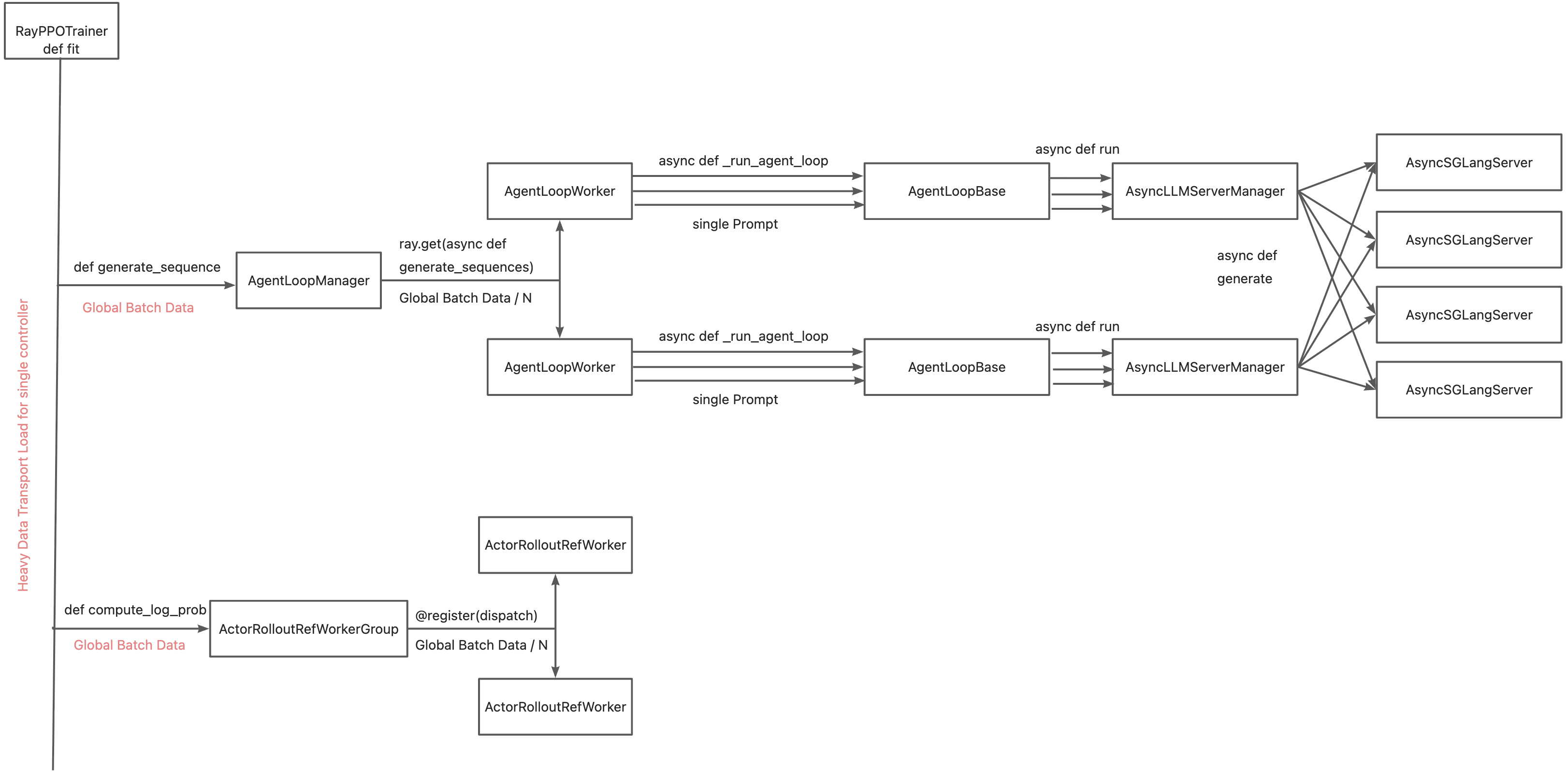
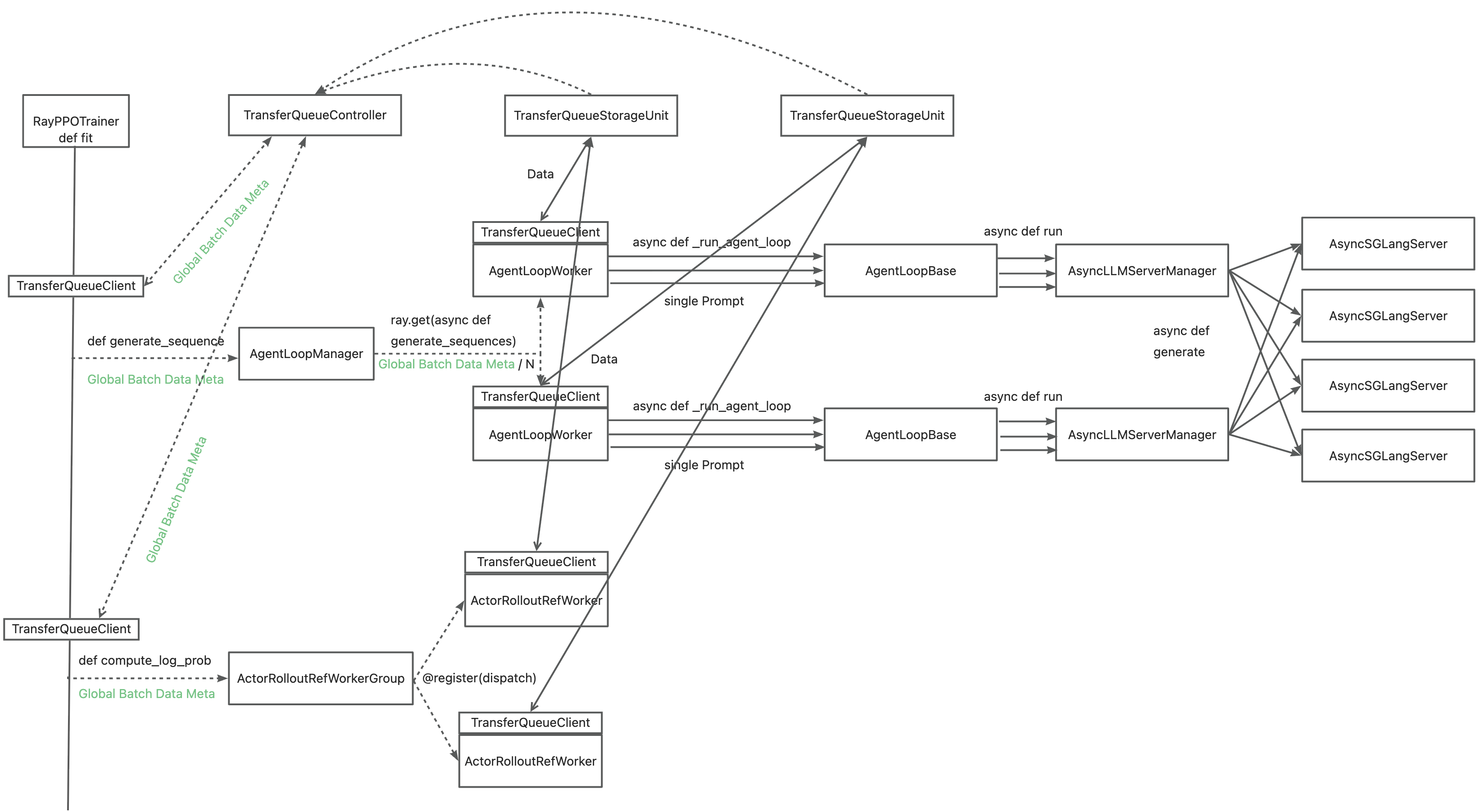
+The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.
+
+
+
+Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by
+
+- Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures
+- Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability)
+- Accelerating data transfer by TransferQueue's distributed storage units
+
+
+
+
+You may refer to the [recipe](https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case), where we mimic the verl usage in both async & sync scenarios.
+
+
+
+
+
+ Citation
+Please kindly cite our paper if you find this repo is useful:
+
+```bibtex
+@article{han2025asyncflow,
+ title={AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training},
+ author={Han, Zhenyu and You, Ansheng and Wang, Haibo and Luo, Kui and Yang, Guang and Shi, Wenqi and Chen, Menglong and Zhang, Sicheng and Lan, Zeshun and Deng, Chunshi and others},
+ journal={arXiv preprint arXiv:2507.01663},
+ year={2025}
+}
+```
\ No newline at end of file
diff --git a/docs/index.rst b/docs/index.rst
index e8467dc965a..06411b5cfcb 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -125,6 +125,7 @@ verl is fast with:
advance/one_step_off
advance/agent_loop
advance/fully_async
+ data/transfer_queue.md
.. toctree::
:maxdepth: 1
diff --git a/recipe/transfer_queue/agent_loop.py b/recipe/transfer_queue/agent_loop.py
new file mode 100644
index 00000000000..871ae8025c0
--- /dev/null
+++ b/recipe/transfer_queue/agent_loop.py
@@ -0,0 +1,76 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import ray
+from transfer_queue import BatchMeta
+
+import verl.experimental.agent_loop.agent_loop as agent_loop
+from verl import DataProto
+
+
+class AgentLoopManager(agent_loop.AgentLoopManager):
+ def generate_sequences(self, prompts: BatchMeta) -> BatchMeta:
+ """Split input batch and dispatch to agent loop workers.
+
+ Args:
+ prompts (BatchMeta): Input batch.
+
+ Returns:
+ BatchMeta: Output batch metadata.
+ """
+
+ if self.rm_micro_batch_size and len(prompts) % self.rm_micro_batch_size != 0:
+ raise ValueError(
+ f"The length of prompts {len(prompts)} cannot divide the world size of rm_wg {self.rm_micro_batch_size}"
+ )
+ if self.config.actor_rollout_ref.rollout.free_cache_engine:
+ self.wake_up()
+ chunkes = prompts.chunk(len(self.agent_loop_workers))
+ outputs = ray.get(
+ [
+ worker.generate_sequences.remote(chunk)
+ for worker, chunk in zip(self.agent_loop_workers, chunkes, strict=True)
+ ]
+ )
+ output = BatchMeta.concat(outputs)
+ if self.config.actor_rollout_ref.rollout.free_cache_engine:
+ self.sleep()
+
+ # calculate performance metrics
+ metrics = [output.extra_info.pop("metrics") for output in outputs] # List[List[Dict[str, str]]]
+ timing = self._performance_metrics(metrics, output)
+
+ output.set_extra_info("timing", timing)
+ return output
+
+ def _performance_metrics(self, metrics: list[list[dict[str, str]]], output: DataProto) -> dict[str, float]:
+ timing = {}
+ t_generate_sequences = np.array([metric["generate_sequences"] for chunk in metrics for metric in chunk])
+ t_tool_calls = np.array([metric["tool_calls"] for chunk in metrics for metric in chunk])
+ timing["agent_loop/generate_sequences/min"] = t_generate_sequences.min()
+ timing["agent_loop/generate_sequences/max"] = t_generate_sequences.max()
+ timing["agent_loop/generate_sequences/mean"] = t_generate_sequences.mean()
+ timing["agent_loop/tool_calls/min"] = t_tool_calls.min()
+ timing["agent_loop/tool_calls/max"] = t_tool_calls.max()
+ timing["agent_loop/tool_calls/mean"] = t_tool_calls.mean()
+
+ return timing
+
+ def create_transferqueue_client(self, controller_infos, storage_infos, role):
+ ray.get(
+ [
+ worker.create_transferqueue_client.remote(controller_infos, storage_infos, role)
+ for worker in self.agent_loop_workers
+ ]
+ )
diff --git a/recipe/transfer_queue/config/transfer_queue_ppo_trainer.yaml b/recipe/transfer_queue/config/transfer_queue_ppo_trainer.yaml
new file mode 100644
index 00000000000..4f9c574e8ee
--- /dev/null
+++ b/recipe/transfer_queue/config/transfer_queue_ppo_trainer.yaml
@@ -0,0 +1,11 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+# config for TransferQueue
+transfer_queue:
+ enable: True
diff --git a/recipe/transfer_queue/main_ppo.py b/recipe/transfer_queue/main_ppo.py
new file mode 100644
index 00000000000..ca4c0ae0915
--- /dev/null
+++ b/recipe/transfer_queue/main_ppo.py
@@ -0,0 +1,200 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Note that we don't combine the main with ray_trainer as ray_trainer is used by other main.
+"""
+
+import os
+import socket
+
+import hydra
+import ray
+from omegaconf import OmegaConf
+
+from verl.trainer.constants_ppo import get_ppo_ray_runtime_env
+from verl.trainer.main_ppo import (
+ TaskRunner as MainTaskRunner,
+)
+from verl.trainer.main_ppo import (
+ create_rl_dataset,
+ create_rl_sampler,
+)
+from verl.trainer.ppo.reward import load_reward_manager
+from verl.trainer.ppo.utils import need_critic, need_reference_policy
+from verl.utils.config import validate_config
+from verl.utils.device import is_cuda_available
+
+from .ray_trainer import RayPPOTrainer
+
+
+@hydra.main(config_path="config", config_name="ppo_trainer", version_base=None)
+def main(config):
+ """Main entry point for PPO training with Hydra configuration management.
+
+ Args:
+ config_dict: Hydra configuration dictionary containing training parameters.
+ """
+ run_ppo(config)
+
+
+# Define a function to run the PPO-like training process
+def run_ppo(config, task_runner_class=None) -> None:
+ """Initialize Ray cluster and run distributed PPO training process.
+
+ Args:
+ config: Training configuration object containing all necessary parameters
+ for distributed PPO training including Ray initialization settings,
+ model paths, and training hyperparameters.
+ task_runner_class: For recipe to change TaskRunner.
+ """
+ # Check if Ray is not initialized
+ if not ray.is_initialized():
+ # Initialize Ray with a local cluster configuration
+ # Set environment variables in the runtime environment to control tokenizer parallelism,
+ # NCCL debug level, VLLM logging level, and allow runtime LoRA updating
+ # `num_cpus` specifies the number of CPU cores Ray can use, obtained from the configuration
+ default_runtime_env = get_ppo_ray_runtime_env()
+ ray_init_kwargs = config.ray_kwargs.get("ray_init", {})
+ runtime_env_kwargs = ray_init_kwargs.get("runtime_env", {})
+ runtime_env = OmegaConf.merge(default_runtime_env, runtime_env_kwargs)
+ ray_init_kwargs = OmegaConf.create({**ray_init_kwargs, "runtime_env": runtime_env})
+ if config.transfer_queue.enable:
+ ray_init_kwargs["TRANSFER_QUEUE_ENABLE"] = "1"
+ print(f"ray init kwargs: {ray_init_kwargs}")
+ ray.init(**OmegaConf.to_container(ray_init_kwargs))
+
+ if task_runner_class is None:
+ task_runner_class = ray.remote(num_cpus=1)(TaskRunner) # please make sure main_task is not scheduled on head
+
+ # Create a remote instance of the TaskRunner class, and
+ # Execute the `run` method of the TaskRunner instance remotely and wait for it to complete
+ if (
+ is_cuda_available
+ and config.global_profiler.tool == "nsys"
+ and config.global_profiler.get("steps") is not None
+ and len(config.global_profiler.get("steps", [])) > 0
+ ):
+ from verl.utils.import_utils import is_nvtx_available
+
+ assert is_nvtx_available(), "nvtx is not available in CUDA platform. Please 'pip3 install nvtx'"
+ nsight_options = OmegaConf.to_container(
+ config.global_profiler.global_tool_config.nsys.controller_nsight_options
+ )
+ runner = task_runner_class.options(runtime_env={"nsight": nsight_options}).remote()
+ else:
+ runner = task_runner_class.remote()
+ ray.get(runner.run.remote(config))
+
+ # [Optional] get the path of the timeline trace file from the configuration, default to None
+ # This file is used for performance analysis
+ timeline_json_file = config.ray_kwargs.get("timeline_json_file", None)
+ if timeline_json_file:
+ ray.timeline(filename=timeline_json_file)
+
+
+class TaskRunner(MainTaskRunner):
+ def run(self, config):
+ """Execute the main PPO training workflow.
+
+ This method sets up the distributed training environment, initializes
+ workers, datasets, and reward functions, then starts the training process.
+
+ Args:
+ config: Training configuration object containing all parameters needed
+ for setting up and running the PPO training process.
+ """
+ # Print the initial configuration. `resolve=True` will evaluate symbolic values.
+ from pprint import pprint
+
+ from verl.utils.fs import copy_to_local
+
+ print(f"TaskRunner hostname: {socket.gethostname()}, PID: {os.getpid()}")
+ pprint(OmegaConf.to_container(config, resolve=True))
+ OmegaConf.resolve(config)
+
+ actor_rollout_cls, ray_worker_group_cls = self.add_actor_rollout_worker(config)
+ self.add_critic_worker(config)
+
+ # We should adopt a multi-source reward function here:
+ # - for rule-based rm, we directly call a reward score
+ # - for model-based rm, we call a model
+ # - for code related prompt, we send to a sandbox if there are test cases
+ # finally, we combine all the rewards together
+ # The reward type depends on the tag of the data
+ self.add_reward_model_worker(config)
+
+ # Add a reference policy worker if KL loss or KL reward is used.
+ self.add_ref_policy_worker(config, actor_rollout_cls)
+
+ # validate config
+ validate_config(
+ config=config,
+ use_reference_policy=need_reference_policy(self.role_worker_mapping),
+ use_critic=need_critic(config),
+ )
+
+ # Download the checkpoint from HDFS to the local machine.
+ # `use_shm` determines whether to use shared memory, which could lead to faster model loading if turned on
+ local_path = copy_to_local(
+ config.actor_rollout_ref.model.path, use_shm=config.actor_rollout_ref.model.get("use_shm", False)
+ )
+
+ # Instantiate the tokenizer and processor.
+ from verl.utils import hf_processor, hf_tokenizer
+
+ trust_remote_code = config.data.get("trust_remote_code", False)
+ tokenizer = hf_tokenizer(local_path, trust_remote_code=trust_remote_code)
+ # Used for multimodal LLM, could be None
+ processor = hf_processor(local_path, trust_remote_code=trust_remote_code, use_fast=True)
+
+ # Load the reward manager for training and validation.
+ reward_fn = load_reward_manager(
+ config, tokenizer, num_examine=0, **config.reward_model.get("reward_kwargs", {})
+ )
+ val_reward_fn = load_reward_manager(
+ config, tokenizer, num_examine=1, **config.reward_model.get("reward_kwargs", {})
+ )
+
+ resource_pool_manager = self.init_resource_pool_mgr(config)
+
+ from verl.utils.dataset.rl_dataset import collate_fn
+
+ # Create training and validation datasets.
+ train_dataset = create_rl_dataset(config.data.train_files, config.data, tokenizer, processor, is_train=True)
+ val_dataset = create_rl_dataset(config.data.val_files, config.data, tokenizer, processor, is_train=False)
+ train_sampler = create_rl_sampler(config.data, train_dataset)
+
+ # Initialize the PPO trainer.
+ trainer = RayPPOTrainer(
+ config=config,
+ tokenizer=tokenizer,
+ processor=processor,
+ role_worker_mapping=self.role_worker_mapping,
+ resource_pool_manager=resource_pool_manager,
+ ray_worker_group_cls=ray_worker_group_cls,
+ reward_fn=reward_fn,
+ val_reward_fn=val_reward_fn,
+ train_dataset=train_dataset,
+ val_dataset=val_dataset,
+ collate_fn=collate_fn,
+ train_sampler=train_sampler,
+ )
+ # Initialize the workers of the trainer.
+ trainer.init_workers()
+ # Start the training process.
+ trainer.fit()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/recipe/transfer_queue/ray_trainer.py b/recipe/transfer_queue/ray_trainer.py
new file mode 100644
index 00000000000..d6adbddb676
--- /dev/null
+++ b/recipe/transfer_queue/ray_trainer.py
@@ -0,0 +1,1885 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+# Copyright 2023-2024 SGLang Team
+# Copyright 2025 ModelBest Inc. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+PPO Trainer with Ray-based single controller.
+This trainer supports model-agonistic model initialization with huggingface
+"""
+
+import asyncio
+import json
+import logging
+import math
+import os
+import uuid
+from collections import defaultdict
+from dataclasses import dataclass, field
+from pprint import pprint
+from typing import Any, Optional
+
+import numpy as np
+import ray
+import tensordict
+import torch
+from omegaconf import OmegaConf, open_dict
+from packaging.version import parse as parse_version
+from tensordict import TensorDict
+from torch.utils.data import Dataset, Sampler
+from torchdata.stateful_dataloader import StatefulDataLoader
+from tqdm import tqdm
+from transfer_queue import (
+ BatchMeta,
+ TransferQueueController,
+ TransferQueueStorageSimpleUnit,
+ get_placement_group,
+ process_zmq_server_info,
+)
+
+from verl import DataProto
+from verl.experimental.dataset.sampler import AbstractCurriculumSampler
+from verl.single_controller.ray import (
+ RayClassWithInitArgs,
+ RayResourcePool,
+ RayWorkerGroup,
+)
+from verl.single_controller.ray.base import create_colocated_worker_cls
+from verl.trainer.config import AlgoConfig
+from verl.trainer.ppo import core_algos
+from verl.trainer.ppo.core_algos import AdvantageEstimator, agg_loss
+from verl.trainer.ppo.metric_utils import (
+ compute_data_metrics,
+ compute_throughout_metrics,
+ compute_timing_metrics,
+ process_validation_metrics,
+)
+from verl.trainer.ppo.reward import compute_reward, compute_reward_async
+from verl.trainer.ppo.utils import (
+ Role,
+ WorkerType,
+ need_critic,
+ need_reference_policy,
+ need_reward_model,
+)
+from verl.utils.checkpoint.checkpoint_manager import (
+ find_latest_ckpt_path,
+ should_save_ckpt_esi,
+)
+from verl.utils.config import omega_conf_to_dataclass
+from verl.utils.debug import marked_timer
+from verl.utils.metric import reduce_metrics
+from verl.utils.rollout_skip import RolloutSkip
+from verl.utils.seqlen_balancing import (
+ get_seqlen_balanced_partitions,
+ log_seqlen_unbalance,
+)
+from verl.utils.torch_functional import masked_mean
+from verl.utils.tracking import ValidationGenerationsLogger
+from verl.utils.transferqueue_utils import (
+ create_transferqueue_client,
+ get_transferqueue_client,
+ get_val_transferqueue_client,
+ tqbridge,
+)
+
+
+@dataclass
+class ResourcePoolManager:
+ """
+ Define a resource pool specification. Resource pool will be initialized first.
+ """
+
+ resource_pool_spec: dict[str, list[int]]
+ mapping: dict[Role, str]
+ resource_pool_dict: dict[str, RayResourcePool] = field(default_factory=dict)
+
+ def create_resource_pool(self):
+ """Create Ray resource pools for distributed training.
+
+ Initializes resource pools based on the resource pool specification,
+ with each pool managing GPU resources across multiple nodes.
+ For FSDP backend, uses max_colocate_count=1 to merge WorkerGroups.
+ For Megatron backend, uses max_colocate_count>1 for different models.
+ """
+ for resource_pool_name, process_on_nodes in self.resource_pool_spec.items():
+ # max_colocate_count means the number of WorkerGroups (i.e. processes) in each RayResourcePool
+ # For FSDP backend, we recommend using max_colocate_count=1 that merge all WorkerGroups into one.
+ # For Megatron backend, we recommend using max_colocate_count>1
+ # that can utilize different WorkerGroup for differnt models
+ resource_pool = RayResourcePool(
+ process_on_nodes=process_on_nodes, use_gpu=True, max_colocate_count=1, name_prefix=resource_pool_name
+ )
+ self.resource_pool_dict[resource_pool_name] = resource_pool
+
+ self._check_resource_available()
+
+ def get_resource_pool(self, role: Role) -> RayResourcePool:
+ """Get the resource pool of the worker_cls"""
+ return self.resource_pool_dict[self.mapping[role]]
+
+ def get_n_gpus(self) -> int:
+ """Get the number of gpus in this cluster."""
+ return sum([n_gpus for process_on_nodes in self.resource_pool_spec.values() for n_gpus in process_on_nodes])
+
+ def _check_resource_available(self):
+ """Check if the resource pool can be satisfied in this ray cluster."""
+ node_available_resources = ray._private.state.available_resources_per_node()
+ node_available_gpus = {
+ node: node_info.get("GPU", 0) if "GPU" in node_info else node_info.get("NPU", 0)
+ for node, node_info in node_available_resources.items()
+ }
+
+ # check total required gpus can be satisfied
+ total_available_gpus = sum(node_available_gpus.values())
+ total_required_gpus = sum(
+ [n_gpus for process_on_nodes in self.resource_pool_spec.values() for n_gpus in process_on_nodes]
+ )
+ if total_available_gpus < total_required_gpus:
+ raise ValueError(
+ f"Total available GPUs {total_available_gpus} is less than total desired GPUs {total_required_gpus}"
+ )
+
+
+@tqbridge(put_data=False)
+def compute_reward_decorated(data, reward_fn):
+ return compute_reward(data, reward_fn)
+
+
+@tqbridge(put_data=False)
+def compute_reward_async_decorated(data, reward_fn):
+ return compute_reward_async.remote(data, reward_fn)
+
+
+@tqbridge(put_data=False)
+def apply_kl_penalty(data: DataProto, kl_ctrl: core_algos.AdaptiveKLController, kl_penalty="kl"):
+ """Apply KL penalty to the token-level rewards.
+
+ This function computes the KL divergence between the reference policy and current policy,
+ then applies a penalty to the token-level rewards based on this divergence.
+
+ Args:
+ data (DataProto): The data containing batched model outputs and inputs.
+ kl_ctrl (core_algos.AdaptiveKLController): Controller for adaptive KL penalty.
+ kl_penalty (str, optional): Type of KL penalty to apply. Defaults to "kl".
+
+ Returns:
+ tuple: A tuple containing:
+ - The updated data with token-level rewards adjusted by KL penalty
+ - A dictionary of metrics related to the KL penalty
+ """
+ response_mask = data.batch["response_mask"]
+ token_level_scores = data.batch["token_level_scores"]
+ batch_size = data.batch.batch_size[0]
+
+ # compute kl between ref_policy and current policy
+ # When apply_kl_penalty, algorithm.use_kl_in_reward=True, so the reference model has been enabled.
+ kld = core_algos.kl_penalty(
+ data.batch["old_log_probs"], data.batch["ref_log_prob"], kl_penalty=kl_penalty
+ ) # (batch_size, response_length)
+ kld = kld * response_mask
+ beta = kl_ctrl.value
+
+ token_level_rewards = token_level_scores - beta * kld
+
+ current_kl = masked_mean(kld, mask=response_mask, axis=-1) # average over sequence
+ current_kl = torch.mean(current_kl, dim=0).item()
+
+ # according to https://github.com/huggingface/trl/blob/951ca1841f29114b969b57b26c7d3e80a39f75a0/trl/trainer/ppo_trainer.py#L837
+ kl_ctrl.update(current_kl=current_kl, n_steps=batch_size)
+
+ metrics = {"actor/reward_kl_penalty": current_kl, "actor/reward_kl_penalty_coeff": beta}
+
+ return token_level_rewards, metrics
+
+
+def compute_response_mask(batch_meta: BatchMeta, data_system_client):
+ """Compute the attention mask for the response part of the sequence.
+
+ This function extracts the portion of the attention mask that corresponds to the model's response,
+ which is used for masking computations that should only apply to response tokens.
+
+ Args:
+ batch_meta (BatchMeta): The data containing batched model outputs and inputs.
+
+ Returns:
+ BatchMeta: The BatchMeta of attention mask for the response tokens.
+ """
+ data = asyncio.run(data_system_client.async_get_data(batch_meta))
+
+ responses = data["responses"]
+ response_length = responses.size(1)
+ attention_mask = data["attention_mask"]
+ response_mask = attention_mask[:, -response_length:]
+ output = TensorDict({"response_mask": response_mask}, batch_size=response_mask.size(0))
+
+ asyncio.run(data_system_client.async_put(data=output, metadata=batch_meta))
+ batch_meta.add_fields(output)
+
+ return batch_meta
+
+
+@tqbridge(put_data=False)
+def compute_advantage(
+ data: DataProto,
+ adv_estimator: AdvantageEstimator,
+ gamma: float = 1.0,
+ lam: float = 1.0,
+ num_repeat: int = 1,
+ norm_adv_by_std_in_grpo: bool = True,
+ config: Optional[AlgoConfig] = None,
+) -> tuple[Any, Any]:
+ """Compute advantage estimates for policy optimization.
+
+ This function computes advantage estimates using various estimators like GAE, GRPO, REINFORCE++, etc.
+ The advantage estimates are used to guide policy optimization in RL algorithms.
+
+ Args:
+ data (DataProto): The data containing batched model outputs and inputs.
+ adv_estimator (AdvantageEstimator): The advantage estimator to use (e.g., GAE, GRPO, REINFORCE++).
+ gamma (float, optional): Discount factor for future rewards. Defaults to 1.0.
+ lam (float, optional): Lambda parameter for GAE. Defaults to 1.0.
+ num_repeat (int, optional): Number of times to repeat the computation. Defaults to 1.
+ norm_adv_by_std_in_grpo (bool, optional): Whether to normalize advantages by standard deviation in
+ GRPO. Defaults to True.
+ config (dict, optional): Configuration dictionary for algorithm settings. Defaults to None.
+
+ Returns:
+ tuple: A tuple containing:
+ - advantages: The computed advantage estimates.
+ - returns: The computed returns.
+ """
+ # prepare response group
+ if adv_estimator == AdvantageEstimator.GAE:
+ # Compute advantages and returns using Generalized Advantage Estimation (GAE)
+ advantages, returns = core_algos.compute_gae_advantage_return(
+ token_level_rewards=data.batch["token_level_rewards"],
+ values=data.batch["values"],
+ response_mask=data.batch["response_mask"],
+ gamma=gamma,
+ lam=lam,
+ )
+ # TODO: (TQ) adapt core_algos.compute_pf_ppo_reweight_data function to support transfer queue
+ if config.get("use_pf_ppo", False):
+ data = core_algos.compute_pf_ppo_reweight_data(
+ data,
+ config.pf_ppo.get("reweight_method"),
+ config.pf_ppo.get("weight_pow"),
+ )
+ elif adv_estimator == AdvantageEstimator.GRPO:
+ # Initialize the mask for GRPO calculation
+ grpo_calculation_mask = data.batch["response_mask"]
+ # Call compute_grpo_outcome_advantage with parameters matching its definition
+ advantages, returns = core_algos.compute_grpo_outcome_advantage(
+ token_level_rewards=data.batch["token_level_rewards"],
+ response_mask=grpo_calculation_mask,
+ index=data.non_tensor_batch["uid"],
+ norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,
+ )
+ else:
+ # handle all other adv estimator type other than GAE and GRPO
+ adv_estimator_fn = core_algos.get_adv_estimator_fn(adv_estimator)
+ adv_kwargs = {
+ "token_level_rewards": data.batch["token_level_rewards"],
+ "response_mask": data.batch["response_mask"],
+ "config": config,
+ }
+ if "uid" in data.non_tensor_batch: # optional
+ adv_kwargs["index"] = data.non_tensor_batch["uid"]
+ if "reward_baselines" in data.batch: # optional
+ adv_kwargs["reward_baselines"] = data.batch["reward_baselines"]
+
+ # calculate advantage estimator
+ advantages, returns = adv_estimator_fn(**adv_kwargs)
+ return advantages, returns
+
+
+@tqbridge(put_data=False)
+def compute_data_metrics_decorated(batch, use_critic: bool = True):
+ return compute_data_metrics(batch, use_critic)
+
+
+@tqbridge(put_data=False)
+def compute_timing_metrics_decorated(batch, timing_raw: dict[str, float]) -> dict[str, Any]:
+ return compute_timing_metrics(batch, timing_raw)
+
+
+@tqbridge(put_data=False)
+def compute_throughout_metrics_decorated(batch, timing_raw: dict[str, float], n_gpus: int) -> dict[str, Any]:
+ return compute_throughout_metrics(batch, timing_raw, n_gpus)
+
+
+@tqbridge(put_data=False)
+def calculate_debug_metrics_decorated(data):
+ from verl.utils.debug.metrics import calculate_debug_metrics
+
+ return calculate_debug_metrics(data)
+
+
+@tqbridge(put_data=False)
+def compute_val_reward_decorated(reward_fn, data, return_dict):
+ return reward_fn(data, return_dict)
+
+
+class RayPPOTrainer:
+ """Distributed PPO trainer using Ray for scalable reinforcement learning.
+
+ This trainer orchestrates distributed PPO training across multiple nodes and GPUs,
+ managing actor rollouts, critic training, and reward computation with Ray backend.
+ Supports various model architectures including FSDP, Megatron, vLLM, and SGLang integration.
+ """
+
+ # TODO: support each role have individual ray_worker_group_cls,
+ # i.e., support different backend of different role
+ def __init__(
+ self,
+ config,
+ tokenizer,
+ role_worker_mapping: dict[Role, WorkerType],
+ resource_pool_manager: ResourcePoolManager,
+ ray_worker_group_cls: type[RayWorkerGroup] = RayWorkerGroup,
+ processor=None,
+ reward_fn=None,
+ val_reward_fn=None,
+ train_dataset: Optional[Dataset] = None,
+ val_dataset: Optional[Dataset] = None,
+ collate_fn=None,
+ train_sampler: Optional[Sampler] = None,
+ device_name=None,
+ ):
+ """
+ Initialize distributed PPO trainer with Ray backend.
+ Note that this trainer runs on the driver process on a single CPU/GPU node.
+
+ Args:
+ config: Configuration object containing training parameters.
+ tokenizer: Tokenizer used for encoding and decoding text.
+ role_worker_mapping (dict[Role, WorkerType]): Mapping from roles to worker classes.
+ resource_pool_manager (ResourcePoolManager): Manager for Ray resource pools.
+ ray_worker_group_cls (RayWorkerGroup, optional): Class for Ray worker groups. Defaults to RayWorkerGroup.
+ processor: Optional data processor, used for multimodal data
+ reward_fn: Function for computing rewards during training.
+ val_reward_fn: Function for computing rewards during validation.
+ train_dataset (Optional[Dataset], optional): Training dataset. Defaults to None.
+ val_dataset (Optional[Dataset], optional): Validation dataset. Defaults to None.
+ collate_fn: Function to collate data samples into batches.
+ train_sampler (Optional[Sampler], optional): Sampler for the training dataset. Defaults to None.
+ device_name (str, optional): Device name for training (e.g., "cuda", "cpu"). Defaults to None.
+ """
+
+ # Store the tokenizer for text processing
+ self.tokenizer = tokenizer
+ self.processor = processor
+ self.config = config
+ self.reward_fn = reward_fn
+ self.val_reward_fn = val_reward_fn
+
+ self.hybrid_engine = config.actor_rollout_ref.hybrid_engine
+ assert self.hybrid_engine, "Currently, only support hybrid engine"
+
+ if self.hybrid_engine:
+ assert Role.ActorRollout in role_worker_mapping, f"{role_worker_mapping.keys()=}"
+
+ self.role_worker_mapping = role_worker_mapping
+ self.resource_pool_manager = resource_pool_manager
+ self.use_reference_policy = need_reference_policy(self.role_worker_mapping)
+ self.use_rm = need_reward_model(self.role_worker_mapping)
+ self.use_critic = need_critic(self.config)
+ self.ray_worker_group_cls = ray_worker_group_cls
+ self.device_name = device_name if device_name else self.config.trainer.device
+ self.validation_generations_logger = ValidationGenerationsLogger(
+ project_name=self.config.trainer.project_name,
+ experiment_name=self.config.trainer.experiment_name,
+ )
+
+ # if ref_in_actor is True, the reference policy will be actor without lora applied
+ self.ref_in_actor = config.actor_rollout_ref.model.get("lora_rank", 0) > 0
+
+ # define in-reward KL control
+ # kl loss control currently not suppoorted
+ if self.config.algorithm.use_kl_in_reward:
+ self.kl_ctrl_in_reward = core_algos.get_kl_controller(self.config.algorithm.kl_ctrl)
+
+ self._create_dataloader(train_dataset, val_dataset, collate_fn, train_sampler)
+
+ self.data_system_client = self._initialize_train_data_system(
+ self.config.data.train_batch_size, self.config.actor_rollout_ref.rollout.n
+ )
+ self.val_data_system_client = self._initialize_val_data_system(
+ self.val_batch_size, self.config.actor_rollout_ref.rollout.val_kwargs.n
+ )
+
+ def _initialize_train_data_system(self, global_batch_size, num_n_samples, role="train"):
+ # 1. initialize TransferQueueStorage
+ total_storage_size = global_batch_size * self.config.trainer.num_global_batch * num_n_samples
+ self.data_system_storage_units = {}
+ storage_placement_group = get_placement_group(self.config.trainer.num_data_storage_units, num_cpus_per_actor=1)
+ for storage_unit_rank in range(self.config.trainer.num_data_storage_units):
+ storage_node = TransferQueueStorageSimpleUnit.options(
+ placement_group=storage_placement_group, placement_group_bundle_index=storage_unit_rank
+ ).remote(storage_size=math.ceil(total_storage_size / self.config.trainer.num_data_storage_units))
+ self.data_system_storage_units[storage_unit_rank] = storage_node
+ logging.info(f"TransferQueueStorageSimpleUnit #{storage_unit_rank} has been created.")
+
+ # 2. initialize TransferQueueController
+ # we support inilialize multiple controller instances for large-scale scenario. Please allocate exactly
+ # one controller for a single WorkerGroup.
+ self.data_system_controllers = {}
+ controller_placement_group = get_placement_group(self.config.trainer.num_data_controllers, num_cpus_per_actor=1)
+ for controller_rank in range(self.config.trainer.num_data_controllers):
+ self.data_system_controllers[controller_rank] = TransferQueueController.options(
+ placement_group=controller_placement_group, placement_group_bundle_index=controller_rank
+ ).remote(
+ num_storage_units=self.config.trainer.num_data_storage_units,
+ global_batch_size=global_batch_size,
+ num_global_batch=self.config.trainer.num_global_batch,
+ num_n_samples=num_n_samples,
+ )
+ logging.info(f"TransferQueueController #{controller_rank} has been created.")
+
+ # 3. register controller & storage
+ self.data_system_controller_infos = process_zmq_server_info(self.data_system_controllers)
+ self.data_system_storage_unit_infos = process_zmq_server_info(self.data_system_storage_units)
+
+ ray.get(
+ [
+ storage_unit.register_controller_info.remote(self.data_system_controller_infos)
+ for storage_unit in self.data_system_storage_units.values()
+ ]
+ )
+
+ # 4. create client
+ # each client should be allocated to exactly one controller
+ create_transferqueue_client(
+ client_id="Trainer-" + role,
+ controller_infos=self.data_system_controller_infos,
+ storage_infos=self.data_system_storage_unit_infos,
+ )
+ data_system_client = get_transferqueue_client()
+ return data_system_client
+
+ def _initialize_val_data_system(self, global_batch_size, num_n_samples, role="val"):
+ # 1. initialize TransferQueueStorage
+ total_storage_size = global_batch_size * self.config.trainer.num_global_batch * num_n_samples
+ self.val_data_system_storage_units = {}
+ storage_placement_group = get_placement_group(self.config.trainer.num_data_storage_units, num_cpus_per_actor=1)
+ for storage_unit_rank in range(self.config.trainer.num_data_storage_units):
+ storage_node = TransferQueueStorageSimpleUnit.options(
+ placement_group=storage_placement_group, placement_group_bundle_index=storage_unit_rank
+ ).remote(storage_size=math.ceil(total_storage_size / self.config.trainer.num_data_storage_units))
+ self.val_data_system_storage_units[storage_unit_rank] = storage_node
+ logging.info(f"TransferQueueStorageSimpleUnit #{storage_unit_rank} has been created.")
+
+ # 2. initialize TransferQueueController
+ # we support inilialize multiple controller instances for large-scale scenario. Please allocate exactly
+ # one controller for a single WorkerGroup.
+ self.val_data_system_controllers = {}
+ controller_placement_group = get_placement_group(self.config.trainer.num_data_controllers, num_cpus_per_actor=1)
+ for controller_rank in range(self.config.trainer.num_data_controllers):
+ self.val_data_system_controllers[controller_rank] = TransferQueueController.options(
+ placement_group=controller_placement_group, placement_group_bundle_index=controller_rank
+ ).remote(
+ num_storage_units=self.config.trainer.num_data_storage_units,
+ global_batch_size=global_batch_size,
+ num_global_batch=self.config.trainer.num_global_batch,
+ num_n_samples=num_n_samples,
+ )
+ logging.info(f"TransferQueueController #{controller_rank} has been created.")
+
+ # 3. register controller & storage
+ self.val_data_system_controller_infos = process_zmq_server_info(self.val_data_system_controllers)
+ self.val_data_system_storage_unit_infos = process_zmq_server_info(self.val_data_system_storage_units)
+
+ ray.get(
+ [
+ storage_unit.register_controller_info.remote(self.val_data_system_controller_infos)
+ for storage_unit in self.val_data_system_storage_units.values()
+ ]
+ )
+
+ # 4. create client
+ # each client should be allocated to exactly one controller
+ create_transferqueue_client(
+ client_id="Trainer-" + role,
+ controller_infos=self.val_data_system_controller_infos,
+ storage_infos=self.val_data_system_storage_unit_infos,
+ )
+ data_system_client = get_val_transferqueue_client()
+ return data_system_client
+
+ def _create_dataloader(self, train_dataset, val_dataset, collate_fn, train_sampler: Optional[Sampler]):
+ """
+ Creates the train and validation dataloaders.
+ """
+ # TODO: we have to make sure the batch size is divisible by the dp size
+ from verl.trainer.main_ppo import create_rl_dataset, create_rl_sampler
+
+ if train_dataset is None:
+ train_dataset = create_rl_dataset(
+ self.config.data.train_files, self.config.data, self.tokenizer, self.processor
+ )
+ if val_dataset is None:
+ val_dataset = create_rl_dataset(
+ self.config.data.val_files, self.config.data, self.tokenizer, self.processor
+ )
+ self.train_dataset, self.val_dataset = train_dataset, val_dataset
+
+ if train_sampler is None:
+ train_sampler = create_rl_sampler(self.config.data, self.train_dataset)
+ if collate_fn is None:
+ from verl.utils.dataset.rl_dataset import collate_fn as default_collate_fn
+
+ collate_fn = default_collate_fn
+
+ num_workers = self.config.data["dataloader_num_workers"]
+
+ self.train_dataloader = StatefulDataLoader(
+ dataset=self.train_dataset,
+ batch_size=self.config.data.get("gen_batch_size", self.config.data.train_batch_size),
+ num_workers=num_workers,
+ drop_last=True,
+ collate_fn=collate_fn,
+ sampler=train_sampler,
+ )
+
+ val_batch_size = self.config.data.val_batch_size # Prefer config value if set
+ if val_batch_size is None:
+ val_batch_size = len(self.val_dataset)
+ self.val_batch_size = val_batch_size
+
+ self.val_dataloader = StatefulDataLoader(
+ dataset=self.val_dataset,
+ batch_size=val_batch_size,
+ num_workers=num_workers,
+ shuffle=self.config.data.get("validation_shuffle", True),
+ drop_last=False,
+ collate_fn=collate_fn,
+ )
+
+ assert len(self.train_dataloader) >= 1, "Train dataloader is empty!"
+ assert len(self.val_dataloader) >= 1, "Validation dataloader is empty!"
+
+ print(
+ f"Size of train dataloader: {len(self.train_dataloader)}, Size of val dataloader: "
+ f"{len(self.val_dataloader)}"
+ )
+
+ total_training_steps = len(self.train_dataloader) * self.config.trainer.total_epochs
+
+ if self.config.trainer.total_training_steps is not None:
+ total_training_steps = self.config.trainer.total_training_steps
+
+ self.total_training_steps = total_training_steps
+ print(f"Total training steps: {self.total_training_steps}")
+
+ try:
+ OmegaConf.set_struct(self.config, True)
+ with open_dict(self.config):
+ if OmegaConf.select(self.config, "actor_rollout_ref.actor.optim"):
+ self.config.actor_rollout_ref.actor.optim.total_training_steps = total_training_steps
+ if OmegaConf.select(self.config, "critic.optim"):
+ self.config.critic.optim.total_training_steps = total_training_steps
+ except Exception as e:
+ print(f"Warning: Could not set total_training_steps in config. Structure missing? Error: {e}")
+
+ def _dump_generations(self, inputs, outputs, gts, scores, reward_extra_infos_dict, dump_path):
+ """Dump rollout/validation samples as JSONL."""
+ os.makedirs(dump_path, exist_ok=True)
+ filename = os.path.join(dump_path, f"{self.global_steps}.jsonl")
+
+ n = len(inputs)
+ base_data = {
+ "input": inputs,
+ "output": outputs,
+ "gts": gts,
+ "score": scores,
+ "step": [self.global_steps] * n,
+ }
+
+ for k, v in reward_extra_infos_dict.items():
+ if len(v) == n:
+ base_data[k] = v
+
+ lines = []
+ for i in range(n):
+ entry = {k: v[i] for k, v in base_data.items()}
+ lines.append(json.dumps(entry, ensure_ascii=False))
+
+ with open(filename, "w") as f:
+ f.write("\n".join(lines) + "\n")
+
+ print(f"Dumped generations to {filename}")
+
+ def _log_rollout_data(
+ self, log_rollout_meta: BatchMeta, reward_extra_infos_dict: dict, timing_raw: dict, rollout_data_dir: str
+ ):
+ """
+ Log rollout data to disk.
+
+ Args:
+ log_rollout_meta (BatchMeta): The batch_meta of rollout data
+ reward_extra_infos_dict (dict): Additional reward information to log
+ timing_raw (dict): Timing information for profiling
+ rollout_data_dir (str): Directory path to save the rollout data
+ """
+ with marked_timer("dump_rollout_generations", timing_raw, color="green"):
+ data = asyncio.run(self.data_system_client.async_get_data(log_rollout_meta))
+
+ inputs = self.tokenizer.batch_decode(data["prompts"], skip_special_tokens=True)
+ outputs = self.tokenizer.batch_decode(data["responses"], skip_special_tokens=True)
+ scores = data["token_level_scores"].sum(-1).cpu().tolist()
+ sample_gts = [item.get("ground_truth", None) for item in data.get("reward_model", {})]
+
+ reward_extra_infos_to_dump = reward_extra_infos_dict.copy()
+ if "request_id" in log_rollout_meta.field_names:
+ reward_extra_infos_dict.setdefault(
+ "request_id",
+ data["request_id"].tolist(),
+ )
+
+ self._dump_generations(
+ inputs=inputs,
+ outputs=outputs,
+ gts=sample_gts,
+ scores=scores,
+ reward_extra_infos_dict=reward_extra_infos_to_dump,
+ dump_path=rollout_data_dir,
+ )
+
+ def _maybe_log_val_generations(self, inputs, outputs, scores):
+ """Log a table of validation samples to the configured logger (wandb or swanlab)"""
+
+ generations_to_log = self.config.trainer.log_val_generations
+
+ if generations_to_log == 0:
+ return
+
+ import numpy as np
+
+ # Create tuples of (input, output, score) and sort by input text
+ samples = list(zip(inputs, outputs, scores, strict=True))
+ samples.sort(key=lambda x: x[0]) # Sort by input text
+
+ # Use fixed random seed for deterministic shuffling
+ rng = np.random.RandomState(42)
+ rng.shuffle(samples)
+
+ # Take first N samples after shuffling
+ samples = samples[:generations_to_log]
+
+ # Log to each configured logger
+ self.validation_generations_logger.log(self.config.trainer.logger, samples, self.global_steps)
+
+ def _get_gen_batch(self, batch: DataProto) -> DataProto:
+ reward_model_keys = set({"data_source", "reward_model", "extra_info", "uid"}) & batch.non_tensor_batch.keys()
+
+ # pop those keys for generation
+ batch_keys_to_pop = ["input_ids", "attention_mask", "position_ids"]
+ non_tensor_batch_keys_to_pop = set(batch.non_tensor_batch.keys()) - reward_model_keys
+ gen_batch = batch.pop(
+ batch_keys=batch_keys_to_pop,
+ non_tensor_batch_keys=list(non_tensor_batch_keys_to_pop),
+ )
+
+ # For agent loop, we need reward model keys to compute score.
+ if self.async_rollout_mode:
+ gen_batch.non_tensor_batch.update(batch.non_tensor_batch)
+
+ return gen_batch
+
+ def _validate(self):
+ data_source_lst = []
+ reward_extra_infos_dict: dict[str, list] = defaultdict(list)
+
+ # Lists to collect samples for the table
+ sample_inputs = []
+ sample_outputs = []
+ sample_gts = []
+ sample_scores = []
+ sample_turns = []
+ sample_uids = []
+
+ for test_data in self.val_dataloader:
+ if "uid" not in test_data.keys():
+ test_data["uid"] = np.array(
+ [str(uuid.uuid4()) for _ in range(len(test_data["input_ids"]))], dtype=object
+ )
+
+ # repeat test data
+ repeated_test_data = self.repeat_dict(
+ test_data, repeat_times=self.config.actor_rollout_ref.rollout.val_kwargs.n, interleave=True
+ )
+
+ test_batch: TensorDict = self.dict_to_tensordict(repeated_test_data)
+
+ # we only do validation on rule-based rm
+ if self.config.reward_model.enable and test_batch[0]["reward_model"]["style"] == "model":
+ return {}
+
+ asyncio.run(self.val_data_system_client.async_put(data=test_batch, global_step=self.global_steps - 1))
+
+ # Store original inputs
+ batch_meta = asyncio.run(
+ self.val_data_system_client.async_get_meta(
+ data_fields=["input_ids", "uid", "reward_model"],
+ batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
+ global_step=self.global_steps - 1,
+ get_n_samples=False,
+ task_name="get_data",
+ )
+ )
+ data = asyncio.run(self.val_data_system_client.async_get_data(batch_meta))
+ input_ids = data["input_ids"]
+ # TODO: Can we keep special tokens except for padding tokens?
+ input_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in input_ids]
+ sample_inputs.extend(input_texts)
+ sample_uids.extend(data["uid"])
+
+ ground_truths = [item.get("ground_truth", None) for item in data.get("reward_model", {})]
+ sample_gts.extend(ground_truths)
+
+ test_gen_meta = asyncio.run(
+ self.val_data_system_client.async_get_meta(
+ data_fields=list(test_batch.keys()), # TODO: (TQ) Get metadata by specified fields
+ batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
+ global_step=self.global_steps - 1, # self.global_steps start from 1
+ get_n_samples=False,
+ task_name="generate_sequences",
+ )
+ )
+ test_gen_meta.extra_info = {
+ "eos_token_id": self.tokenizer.eos_token_id,
+ "pad_token_id": self.tokenizer.pad_token_id,
+ "recompute_log_prob": False,
+ "do_sample": self.config.actor_rollout_ref.rollout.val_kwargs.do_sample,
+ "validate": True,
+ "global_steps": self.global_steps,
+ }
+ print(f"test_gen_batch meta info: {test_gen_meta.extra_info}")
+
+ # TODO: (TQ) Support padding and unpadding to make DataProto divisible by dp_size with TransferQueue
+ if not self.async_rollout_mode:
+ test_output_gen_meta = self.actor_rollout_wg.generate_sequences(test_gen_meta)
+ else:
+ test_output_gen_meta = self.async_rollout_manager.generate_sequences(test_gen_meta)
+
+ test_batch_meta = test_gen_meta.union(test_output_gen_meta)
+
+ print("validation generation end")
+
+ # Store generated outputs
+ test_response_meta = asyncio.run(
+ self.val_data_system_client.async_get_meta(
+ data_fields=["responses"],
+ batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
+ global_step=self.global_steps - 1, # self.global_steps start from 1
+ get_n_samples=False,
+ task_name="get_response",
+ )
+ )
+ data = asyncio.run(self.val_data_system_client.async_get_data(test_response_meta))
+ output_ids = data["responses"]
+ output_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in output_ids]
+ sample_outputs.extend(output_texts)
+
+ test_batch_meta.set_extra_info("validate", True)
+
+ # evaluate using reward_function
+ if self.val_reward_fn is None:
+ raise ValueError("val_reward_fn must be provided for validation.")
+
+ compute_reward_fields = [
+ "responses",
+ "prompts",
+ "attention_mask",
+ "reward_model",
+ "data_source",
+ ]
+ if "rm_scores" in batch_meta.field_names:
+ compute_reward_fields = ["rm_scores"]
+ val_reward_meta = asyncio.run(
+ self.val_data_system_client.async_get_meta(
+ data_fields=compute_reward_fields,
+ batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
+ global_step=self.global_steps - 1,
+ get_n_samples=False,
+ task_name="compute_reward",
+ )
+ )
+ val_reward_meta.update_extra_info(test_batch_meta.extra_info)
+ result = compute_val_reward_decorated(self.val_reward_fn, val_reward_meta, return_dict=True)
+ reward_tensor = result["reward_tensor"]
+ scores = reward_tensor.sum(-1).cpu().tolist()
+ sample_scores.extend(scores)
+
+ reward_extra_infos_dict["reward"].extend(scores)
+ print(f"len reward_extra_infos_dict['reward']: {len(reward_extra_infos_dict['reward'])}")
+ if "reward_extra_info" in result:
+ for key, lst in result["reward_extra_info"].items():
+ reward_extra_infos_dict[key].extend(lst)
+ print(f"len reward_extra_infos_dict['{key}']: {len(reward_extra_infos_dict[key])}")
+
+ # collect num_turns of each prompt
+ if "__num_turns__" in test_batch_meta.field_names:
+ num_turns_meta = asyncio.run(
+ self.val_data_system_client.async_get_meta(
+ data_fields=["__num_turns__"],
+ batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
+ global_step=self.global_steps - 1, # self.global_steps start from 1
+ get_n_samples=False,
+ task_name="get_num_turns",
+ )
+ )
+ data = asyncio.run(self.val_data_system_client.async_get_data(num_turns_meta))
+ sample_turns.append(data["__num_turns__"])
+
+ data_source = ["unknown"] * reward_tensor.shape[0]
+ if "data_source" in test_batch_meta.field_names:
+ data_source_meta = asyncio.run(
+ self.val_data_system_client.async_get_meta(
+ data_fields=["data_source"],
+ batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
+ global_step=self.global_steps - 1, # self.global_steps start from 1
+ get_n_samples=False,
+ task_name="get_data_source",
+ )
+ )
+ data = asyncio.run(self.val_data_system_client.async_get_data(data_source_meta))
+ data_source = data["data_source"]
+
+ data_source_lst.append(data_source)
+
+ self._maybe_log_val_generations(inputs=sample_inputs, outputs=sample_outputs, scores=sample_scores)
+
+ # dump generations
+ val_data_dir = self.config.trainer.get("validation_data_dir", None)
+ if val_data_dir:
+ self._dump_generations(
+ inputs=sample_inputs,
+ outputs=sample_outputs,
+ gts=sample_gts,
+ scores=sample_scores,
+ reward_extra_infos_dict=reward_extra_infos_dict,
+ dump_path=val_data_dir,
+ )
+
+ for key_info, lst in reward_extra_infos_dict.items():
+ assert len(lst) == 0 or len(lst) == len(sample_scores), f"{key_info}: {len(lst)=}, {len(sample_scores)=}"
+
+ data_sources = np.concatenate(data_source_lst, axis=0)
+
+ data_src2var2metric2val = process_validation_metrics(data_sources, sample_uids, reward_extra_infos_dict)
+ metric_dict = {}
+ for data_source, var2metric2val in data_src2var2metric2val.items():
+ core_var = "acc" if "acc" in var2metric2val else "reward"
+ for var_name, metric2val in var2metric2val.items():
+ n_max = max([int(name.split("@")[-1].split("/")[0]) for name in metric2val.keys()])
+ for metric_name, metric_val in metric2val.items():
+ if (
+ (var_name == core_var)
+ and any(metric_name.startswith(pfx) for pfx in ["mean", "maj", "best"])
+ and (f"@{n_max}" in metric_name)
+ ):
+ metric_sec = "val-core"
+ else:
+ metric_sec = "val-aux"
+ pfx = f"{metric_sec}/{data_source}/{var_name}/{metric_name}"
+ metric_dict[pfx] = metric_val
+
+ if len(sample_turns) > 0:
+ sample_turns = np.concatenate(sample_turns)
+ metric_dict["val-aux/num_turns/min"] = sample_turns.min()
+ metric_dict["val-aux/num_turns/max"] = sample_turns.max()
+ metric_dict["val-aux/num_turns/mean"] = sample_turns.mean()
+
+ asyncio.run(self.val_data_system_client.async_clear(self.global_steps - 1))
+ return metric_dict
+
+ def init_workers(self):
+ """Initialize distributed training workers using Ray backend.
+
+ Creates:
+ 1. Ray resource pools from configuration
+ 2. Worker groups for each role (actor, critic, etc.)
+ """
+ self.resource_pool_manager.create_resource_pool()
+
+ self.resource_pool_to_cls = {pool: {} for pool in self.resource_pool_manager.resource_pool_dict.values()}
+
+ # create actor and rollout
+ if self.hybrid_engine:
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.ActorRollout)
+ actor_rollout_cls = RayClassWithInitArgs(
+ cls=self.role_worker_mapping[Role.ActorRollout],
+ config=self.config.actor_rollout_ref,
+ role="actor_rollout",
+ )
+ self.resource_pool_to_cls[resource_pool]["actor_rollout"] = actor_rollout_cls
+ else:
+ raise NotImplementedError
+
+ # create critic
+ if self.use_critic:
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.Critic)
+ critic_cfg = omega_conf_to_dataclass(self.config.critic)
+ critic_cls = RayClassWithInitArgs(cls=self.role_worker_mapping[Role.Critic], config=critic_cfg)
+ self.resource_pool_to_cls[resource_pool]["critic"] = critic_cls
+
+ # create reference policy if needed
+ if self.use_reference_policy:
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.RefPolicy)
+ ref_policy_cls = RayClassWithInitArgs(
+ self.role_worker_mapping[Role.RefPolicy],
+ config=self.config.actor_rollout_ref,
+ role="ref",
+ )
+ self.resource_pool_to_cls[resource_pool]["ref"] = ref_policy_cls
+
+ # create a reward model if reward_fn is None
+ if self.use_rm:
+ # we create a RM here
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.RewardModel)
+ rm_cls = RayClassWithInitArgs(self.role_worker_mapping[Role.RewardModel], config=self.config.reward_model)
+ self.resource_pool_to_cls[resource_pool]["rm"] = rm_cls
+
+ # initialize WorkerGroup
+ # NOTE: if you want to use a different resource pool for each role, which can support different parallel size,
+ # you should not use `create_colocated_worker_cls`.
+ # Instead, directly pass different resource pool to different worker groups.
+ # See https://github.com/volcengine/verl/blob/master/examples/ray/tutorial.ipynb for more information.
+ all_wg = {}
+ wg_kwargs = {} # Setting up kwargs for RayWorkerGroup
+ if OmegaConf.select(self.config.trainer, "ray_wait_register_center_timeout") is not None:
+ wg_kwargs["ray_wait_register_center_timeout"] = self.config.trainer.ray_wait_register_center_timeout
+ if OmegaConf.select(self.config.global_profiler, "steps") is not None:
+ wg_kwargs["profile_steps"] = OmegaConf.select(self.config.global_profiler, "steps")
+ # Only require nsight worker options when tool is nsys
+ if OmegaConf.select(self.config.global_profiler, "tool") == "nsys":
+ assert (
+ OmegaConf.select(self.config.global_profiler.global_tool_config.nsys, "worker_nsight_options")
+ is not None
+ ), "worker_nsight_options must be set when using nsys with profile_steps"
+ wg_kwargs["worker_nsight_options"] = OmegaConf.to_container(
+ OmegaConf.select(self.config.global_profiler.global_tool_config.nsys, "worker_nsight_options")
+ )
+ wg_kwargs["device_name"] = self.device_name
+
+ for resource_pool, class_dict in self.resource_pool_to_cls.items():
+ worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
+ wg_dict = self.ray_worker_group_cls(
+ resource_pool=resource_pool,
+ ray_cls_with_init=worker_dict_cls,
+ **wg_kwargs,
+ )
+ spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
+ all_wg.update(spawn_wg)
+
+ if self.use_critic:
+ self.critic_wg = all_wg["critic"]
+ self.critic_wg.init_model()
+
+ if self.use_reference_policy and not self.ref_in_actor:
+ self.ref_policy_wg = all_wg["ref"]
+ self.ref_policy_wg.init_model()
+
+ self.rm_wg = None
+ if self.use_rm:
+ self.rm_wg = all_wg["rm"]
+ self.rm_wg.init_model()
+
+ # we should create rollout at the end so that vllm can have a better estimation of kv cache memory
+ self.actor_rollout_wg = all_wg["actor_rollout"]
+ self.actor_rollout_wg.init_model()
+
+ # set transferqueue server info for each worker
+ for _, wg in all_wg.items():
+ wg.create_transferqueue_client(
+ self.data_system_controller_infos, self.data_system_storage_unit_infos, role="train"
+ )
+ wg.create_transferqueue_client(
+ self.val_data_system_controller_infos, self.val_data_system_storage_unit_infos, role="val"
+ )
+
+ # create async rollout manager and request scheduler
+ self.async_rollout_mode = False
+ if self.config.actor_rollout_ref.rollout.mode == "async":
+ from .agent_loop import AgentLoopManager
+
+ self.async_rollout_mode = True
+ self.async_rollout_manager = AgentLoopManager(
+ config=self.config, worker_group=self.actor_rollout_wg, rm_wg=self.rm_wg
+ )
+
+ self.async_rollout_manager.create_transferqueue_client(
+ self.data_system_controller_infos, self.data_system_storage_unit_infos, role="train"
+ )
+ self.async_rollout_manager.create_transferqueue_client(
+ self.val_data_system_controller_infos, self.val_data_system_storage_unit_infos, role="val"
+ )
+
+ def _save_checkpoint(self):
+ from verl.utils.fs import local_mkdir_safe
+
+ # path: given_path + `/global_step_{global_steps}` + `/actor`
+ local_global_step_folder = os.path.join(
+ self.config.trainer.default_local_dir, f"global_step_{self.global_steps}"
+ )
+
+ print(f"local_global_step_folder: {local_global_step_folder}")
+ actor_local_path = os.path.join(local_global_step_folder, "actor")
+
+ actor_remote_path = (
+ None
+ if self.config.trainer.default_hdfs_dir is None
+ else os.path.join(self.config.trainer.default_hdfs_dir, f"global_step_{self.global_steps}", "actor")
+ )
+
+ remove_previous_ckpt_in_save = self.config.trainer.get("remove_previous_ckpt_in_save", False)
+ if remove_previous_ckpt_in_save:
+ print(
+ "Warning: remove_previous_ckpt_in_save is deprecated,"
+ + " set max_actor_ckpt_to_keep=1 and max_critic_ckpt_to_keep=1 instead"
+ )
+ max_actor_ckpt_to_keep = (
+ self.config.trainer.get("max_actor_ckpt_to_keep", None) if not remove_previous_ckpt_in_save else 1
+ )
+ max_critic_ckpt_to_keep = (
+ self.config.trainer.get("max_critic_ckpt_to_keep", None) if not remove_previous_ckpt_in_save else 1
+ )
+
+ self.actor_rollout_wg.save_checkpoint(
+ actor_local_path, actor_remote_path, self.global_steps, max_ckpt_to_keep=max_actor_ckpt_to_keep
+ )
+
+ if self.use_critic:
+ critic_local_path = os.path.join(local_global_step_folder, "critic")
+ critic_remote_path = (
+ None
+ if self.config.trainer.default_hdfs_dir is None
+ else os.path.join(self.config.trainer.default_hdfs_dir, f"global_step_{self.global_steps}", "critic")
+ )
+ self.critic_wg.save_checkpoint(
+ critic_local_path, critic_remote_path, self.global_steps, max_ckpt_to_keep=max_critic_ckpt_to_keep
+ )
+
+ # save dataloader
+ local_mkdir_safe(local_global_step_folder)
+ dataloader_local_path = os.path.join(local_global_step_folder, "data.pt")
+ dataloader_state_dict = self.train_dataloader.state_dict()
+ torch.save(dataloader_state_dict, dataloader_local_path)
+
+ # latest checkpointed iteration tracker (for atomic usage)
+ local_latest_checkpointed_iteration = os.path.join(
+ self.config.trainer.default_local_dir, "latest_checkpointed_iteration.txt"
+ )
+ with open(local_latest_checkpointed_iteration, "w") as f:
+ f.write(str(self.global_steps))
+
+ def _load_checkpoint(self):
+ if self.config.trainer.resume_mode == "disable":
+ return 0
+
+ # load from hdfs
+ if self.config.trainer.default_hdfs_dir is not None:
+ raise NotImplementedError("load from hdfs is not implemented yet")
+ else:
+ checkpoint_folder = self.config.trainer.default_local_dir # TODO: check path
+ if not os.path.isabs(checkpoint_folder):
+ working_dir = os.getcwd()
+ checkpoint_folder = os.path.join(working_dir, checkpoint_folder)
+ global_step_folder = find_latest_ckpt_path(checkpoint_folder) # None if no latest
+
+ # find global_step_folder
+ if self.config.trainer.resume_mode == "auto":
+ if global_step_folder is None:
+ print("Training from scratch")
+ return 0
+ else:
+ if self.config.trainer.resume_mode == "resume_path":
+ assert isinstance(self.config.trainer.resume_from_path, str), "resume ckpt must be str type"
+ assert "global_step_" in self.config.trainer.resume_from_path, (
+ "resume ckpt must specify the global_steps"
+ )
+ global_step_folder = self.config.trainer.resume_from_path
+ if not os.path.isabs(global_step_folder):
+ working_dir = os.getcwd()
+ global_step_folder = os.path.join(working_dir, global_step_folder)
+ print(f"Load from checkpoint folder: {global_step_folder}")
+ # set global step
+ self.global_steps = int(global_step_folder.split("global_step_")[-1])
+
+ print(f"Setting global step to {self.global_steps}")
+ print(f"Resuming from {global_step_folder}")
+
+ actor_path = os.path.join(global_step_folder, "actor")
+ critic_path = os.path.join(global_step_folder, "critic")
+ # load actor
+ self.actor_rollout_wg.load_checkpoint(
+ actor_path, del_local_after_load=self.config.trainer.del_local_ckpt_after_load
+ )
+ # load critic
+ if self.use_critic:
+ self.critic_wg.load_checkpoint(
+ critic_path, del_local_after_load=self.config.trainer.del_local_ckpt_after_load
+ )
+
+ # load dataloader,
+ # TODO: from remote not implemented yet
+ dataloader_local_path = os.path.join(global_step_folder, "data.pt")
+ if os.path.exists(dataloader_local_path):
+ dataloader_state_dict = torch.load(dataloader_local_path, weights_only=False)
+ self.train_dataloader.load_state_dict(dataloader_state_dict)
+ else:
+ print(f"Warning: No dataloader state found at {dataloader_local_path}, will start from scratch")
+
+ def _start_profiling(self, do_profile: bool) -> None:
+ """Start profiling for all worker groups if profiling is enabled."""
+ if do_profile:
+ self.actor_rollout_wg.start_profile(role="e2e", profile_step=self.global_steps)
+ if self.use_reference_policy:
+ self.ref_policy_wg.start_profile(profile_step=self.global_steps)
+ if self.use_critic:
+ self.critic_wg.start_profile(profile_step=self.global_steps)
+ if self.use_rm:
+ self.rm_wg.start_profile(profile_step=self.global_steps)
+
+ def _stop_profiling(self, do_profile: bool) -> None:
+ """Stop profiling for all worker groups if profiling is enabled."""
+ if do_profile:
+ self.actor_rollout_wg.stop_profile()
+ if self.use_reference_policy:
+ self.ref_policy_wg.stop_profile()
+ if self.use_critic:
+ self.critic_wg.stop_profile()
+ if self.use_rm:
+ self.rm_wg.stop_profile()
+
+ def _balance_batch(self, batch: BatchMeta, data_system_client, metrics, logging_prefix="global_seqlen"):
+ """Reorder the batchmeta on single controller such that each dp rank gets similar total tokens"""
+ data = asyncio.run(data_system_client.async_get_data(batch))
+
+ attention_mask = data["attention_mask"]
+ batch_size = attention_mask.shape[0]
+ global_seqlen_lst = data["attention_mask"].view(batch_size, -1).sum(-1).tolist() # (train_batch_size,)
+ world_size = self.actor_rollout_wg.world_size
+ global_partition_lst = get_seqlen_balanced_partitions(
+ global_seqlen_lst, k_partitions=world_size, equal_size=True
+ )
+ # reorder based on index. The data will be automatically equally partitioned by dispatch function
+ global_idx = [j for partition in global_partition_lst for j in partition]
+ global_balance_stats = log_seqlen_unbalance(
+ seqlen_list=global_seqlen_lst, partitions=global_partition_lst, prefix=logging_prefix
+ )
+ metrics.update(global_balance_stats)
+ return global_idx
+
+ @classmethod
+ def repeat_dict(
+ cls, batch_dict: dict[str, torch.Tensor | np.ndarray], repeat_times=2, interleave=True
+ ) -> dict[str, torch.Tensor | np.ndarray]:
+ """
+ Repeat the batch dict a specified number of times.
+
+ Args:
+ repeat_times (int): Number of times to repeat the data.
+ interleave (bool): Whether to interleave the repeated data.
+
+ Returns:
+ dict: A new dict with repeated data.
+ """
+ if repeat_times == 1:
+ return batch_dict
+
+ repeated_batch_dict = {}
+ if batch_dict:
+ if interleave:
+ # Interleave the data
+ for key, val in batch_dict.items():
+ if isinstance(val, torch.Tensor):
+ repeated_batch_dict[key] = val.repeat_interleave(repeat_times, dim=0)
+ elif isinstance(val, np.ndarray):
+ repeated_batch_dict[key] = np.repeat(val, repeat_times, axis=0)
+ else:
+ raise ValueError(f"Unsupported type in data {type(val)}")
+ else:
+ # Stack the data
+ for key, val in batch_dict.items():
+ if isinstance(val, torch.Tensor):
+ repeated_batch_dict[key] = (
+ val.unsqueeze(0).expand(repeat_times, *val.shape).reshape(-1, *val.shape[1:])
+ )
+ elif isinstance(val, np.ndarray):
+ repeated_batch_dict[key] = np.tile(val, (repeat_times,) + (1,) * (val.ndim - 1))
+ else:
+ raise ValueError(f"Unsupported type in data {type(val)}")
+ return repeated_batch_dict
+
+ @classmethod
+ def dict_to_tensordict(cls, data: dict[str, torch.Tensor | np.ndarray]) -> TensorDict:
+ """
+ Create a TensorDict from a dict of tensors and non_tensors.
+ Note that this requires tensordict version at least 0.10
+ """
+ assert parse_version(tensordict.__version__) >= parse_version("0.10"), (
+ "Storing non-tensor data in TensorDict at least requires tensordict version 0.10"
+ )
+ tensors_batch = {}
+ batch_size = None
+
+ for key, val in data.items():
+ if isinstance(val, torch.Tensor | np.ndarray):
+ tensors_batch[key] = val
+ else:
+ raise ValueError(f"Unsupported type in data {type(val)}")
+
+ if batch_size is None:
+ batch_size = len(val)
+ else:
+ assert len(val) == batch_size
+
+ if batch_size is None:
+ batch_size = []
+ else:
+ batch_size = [batch_size]
+
+ return TensorDict(tensors_batch, batch_size=batch_size)
+
+ def fit(self):
+ """
+ The training loop of PPO.
+ The driver process only need to call the compute functions of the worker group through RPC
+ to construct the PPO dataflow.
+ The light-weight advantage computation is done on the driver process.
+ """
+ from omegaconf import OmegaConf
+
+ from verl.utils.tracking import Tracking
+
+ logger = Tracking(
+ project_name=self.config.trainer.project_name,
+ experiment_name=self.config.trainer.experiment_name,
+ default_backend=self.config.trainer.logger,
+ config=OmegaConf.to_container(self.config, resolve=True),
+ )
+
+ self.global_steps = 0
+
+ # load checkpoint before doing anything
+ self._load_checkpoint()
+
+ # perform validation before training
+ # currently, we only support validation using the reward_function.
+ if self.val_reward_fn is not None and self.config.trainer.get("val_before_train", True):
+ val_metrics = self._validate()
+ assert val_metrics, f"{val_metrics=}"
+ pprint(f"Initial validation metrics: {val_metrics}")
+ logger.log(data=val_metrics, step=self.global_steps)
+ if self.config.trainer.get("val_only", False):
+ return
+
+ if self.config.actor_rollout_ref.rollout.get("skip_rollout", False):
+ rollout_skip = RolloutSkip(self.config, self.actor_rollout_wg)
+ rollout_skip.wrap_generate_sequences()
+
+ # add tqdm
+ progress_bar = tqdm(total=self.total_training_steps, initial=self.global_steps, desc="Training Progress")
+
+ # we start from step 1
+ self.global_steps += 1
+ last_val_metrics = None
+ self.max_steps_duration = 0
+
+ prev_step_profile = False
+ curr_step_profile = (
+ self.global_steps in self.config.global_profiler.steps
+ if self.config.global_profiler.steps is not None
+ else False
+ )
+ next_step_profile = False
+
+ for epoch in range(self.config.trainer.total_epochs):
+ for batch_dict in self.train_dataloader:
+ metrics = {}
+ timing_raw = {}
+ base_get_meta_kwargs = dict(
+ batch_size=self.config.data.train_batch_size * self.config.actor_rollout_ref.rollout.n,
+ global_step=self.global_steps - 1, # self.global_steps starts from 1
+ get_n_samples=False,
+ )
+
+ with marked_timer("start_profile", timing_raw):
+ self._start_profiling(
+ not prev_step_profile and curr_step_profile
+ if self.config.global_profiler.profile_continuous_steps
+ else curr_step_profile
+ )
+
+ # add uid to batch
+ batch_dict["uid"] = np.array(
+ [str(uuid.uuid4()) for _ in range(len(batch_dict["input_ids"]))], dtype=object
+ )
+ # When n > 1, repeat input data before putting to data system, simulating DataProto repeat.
+ repeated_batch_dict = self.repeat_dict(
+ batch_dict, repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True
+ )
+ batch: TensorDict = self.dict_to_tensordict(repeated_batch_dict)
+ asyncio.run(self.data_system_client.async_put(data=batch, global_step=self.global_steps - 1))
+
+ gen_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=list(batch.keys()), # TODO: (TQ) Get metadata by specified fields
+ task_name="generate_sequences",
+ **base_get_meta_kwargs,
+ )
+ )
+ # pass global_steps to trace
+ gen_meta.set_extra_info("global_steps", self.global_steps)
+
+ is_last_step = self.global_steps >= self.total_training_steps
+
+ with marked_timer("step", timing_raw):
+ # generate a batch
+ with marked_timer("gen", timing_raw, color="red"):
+ if not self.async_rollout_mode:
+ gen_output_meta = self.actor_rollout_wg.generate_sequences(gen_meta)
+ else:
+ gen_output_meta = self.async_rollout_manager.generate_sequences(gen_meta)
+ timing_raw.update(gen_output_meta.extra_info["timing"])
+ gen_output_meta.extra_info.pop("timing", None)
+
+ # TODO: (TQ) support transfer queue
+ # if self.config.algorithm.adv_estimator == AdvantageEstimator.REMAX:
+ # if self.reward_fn is None:
+ # raise ValueError("A reward_fn is required for REMAX advantage estimation.")
+ #
+ # with marked_timer("gen_max", timing_raw, color="purple"):
+ # gen_baseline_meta = deepcopy(gen_meta)
+ # gen_baseline_meta.extra_info["do_sample"] = False
+ # if not self.async_rollout_mode:
+ # gen_baseline_output = self.actor_rollout_wg.generate_sequences(gen_baseline_meta)
+ # else:
+ # gen_baseline_output = self.async_rollout_manager.generate_sequences(gen_baseline_meta)
+ # batch = batch.union(gen_baseline_output)
+ # reward_baseline_tensor = self.reward_fn(batch)
+ # reward_baseline_tensor = reward_baseline_tensor.sum(dim=-1)
+ #
+ # batch.pop(batch_keys=list(gen_baseline_output.batch.keys()))
+ #
+ # batch.batch["reward_baselines"] = reward_baseline_tensor
+ #
+ # del gen_baseline_batch, gen_baseline_output
+
+ batch_meta: BatchMeta = gen_meta.union(gen_output_meta)
+
+ if "response_mask" not in batch_meta.field_names:
+ response_mask_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=["responses", "attention_mask"],
+ task_name="compute_response_mask",
+ **base_get_meta_kwargs,
+ )
+ )
+ response_mask_output_meta = compute_response_mask(response_mask_meta, self.data_system_client)
+ batch_meta = batch_meta.union(response_mask_output_meta)
+
+ # Balance the number of valid tokens across DP ranks.
+ # NOTE: This usually changes the order of data in the `batch`,
+ # which won't affect the advantage calculation (since it's based on uid),
+ # but might affect the loss calculation (due to the change of mini-batching).
+ # TODO: Decouple the DP balancing and mini-batching.
+ balanced_idx = None
+ if self.config.trainer.balance_batch:
+ attention_mask_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=["attention_mask"],
+ task_name="balance_batch",
+ **base_get_meta_kwargs,
+ )
+ )
+
+ balanced_idx = self._balance_batch(
+ attention_mask_meta, self.data_system_client, metrics=metrics
+ )
+ batch_meta.reorder(balanced_idx)
+
+ # compute global_valid tokens
+ data = asyncio.run(self.data_system_client.async_get_data(attention_mask_meta))
+ batch_meta.extra_info["global_token_num"] = torch.sum(data["attention_mask"], dim=-1).tolist()
+
+ with marked_timer("reward", timing_raw, color="yellow"):
+ # compute reward model score
+ if self.use_rm and "rm_scores" not in batch_meta.field_names:
+ reward_meta = self.rm_wg.compute_rm_score(batch_meta)
+ batch_meta = batch_meta.union(reward_meta)
+
+ compute_reward_fields = [
+ "responses",
+ "prompts",
+ "attention_mask",
+ "reward_model",
+ "data_source",
+ ]
+ if "rm_scores" in batch_meta.field_names:
+ compute_reward_fields.append("rm_scores")
+ compute_reward_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=compute_reward_fields,
+ task_name="compute_reward",
+ **base_get_meta_kwargs,
+ )
+ )
+ compute_reward_meta.reorder(balanced_idx)
+ if self.config.reward_model.launch_reward_fn_async:
+ future_reward = compute_reward_async_decorated(
+ data=compute_reward_meta,
+ reward_fn=self.reward_fn,
+ )
+ else:
+ reward_tensor, reward_extra_infos_dict = compute_reward_decorated(
+ compute_reward_meta, self.reward_fn
+ )
+ batch_meta = batch_meta.union(compute_reward_meta)
+
+ # recompute old_log_probs
+ with marked_timer("old_log_prob", timing_raw, color="blue"):
+ old_log_prob_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=[
+ "input_ids",
+ "attention_mask",
+ "position_ids",
+ "prompts",
+ "responses",
+ "response_mask",
+ "data_source",
+ "reward_model",
+ "extra_info",
+ "uid",
+ "index",
+ "tools_kwargs",
+ "interaction_kwargs",
+ "ability",
+ ],
+ task_name="compute_log_prob",
+ **base_get_meta_kwargs,
+ )
+ )
+ old_log_prob_meta.reorder(balanced_idx)
+
+ old_log_prob_output_meta = self.actor_rollout_wg.compute_log_prob(old_log_prob_meta)
+ data = asyncio.run(self.data_system_client.async_get_data(old_log_prob_output_meta))
+ entropys = data["entropys"]
+ response_masks = data["response_mask"]
+ loss_agg_mode = self.config.actor_rollout_ref.actor.loss_agg_mode
+ entropy_agg = agg_loss(loss_mat=entropys, loss_mask=response_masks, loss_agg_mode=loss_agg_mode)
+ old_log_prob_metrics = {"actor/entropy": entropy_agg.detach().item()}
+ metrics.update(old_log_prob_metrics)
+
+ batch_meta = batch_meta.union(old_log_prob_output_meta)
+
+ if "rollout_log_probs" in batch_meta.field_names:
+ # TODO: we may want to add diff of probs too.
+ data_fields = ["rollout_log_probs", "old_log_probs", "responses"]
+ if "response_mask" in batch_meta.field_names:
+ data_fields.append("response_mask")
+ if "attention_mask" in batch_meta.field_names:
+ data_fields.append("attention_mask")
+ calculate_debug_metrics_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=data_fields,
+ task_name="calculate_debug_metrics",
+ **base_get_meta_kwargs,
+ )
+ )
+ calculate_debug_metrics_meta.reorder(balanced_idx)
+
+ metrics.update(calculate_debug_metrics_decorated(calculate_debug_metrics_meta))
+
+ if self.use_reference_policy:
+ # compute reference log_prob
+ ref_log_prob_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=[
+ "input_ids",
+ "attention_mask",
+ "position_ids",
+ "prompts",
+ "responses",
+ "response_mask",
+ "old_log_probs",
+ "data_source",
+ "reward_model",
+ "extra_info",
+ "uid",
+ "index",
+ "tools_kwargs",
+ "interaction_kwargs",
+ "ability",
+ ],
+ task_name="compute_ref_log_prob",
+ **base_get_meta_kwargs,
+ )
+ )
+ ref_log_prob_meta.reorder(balanced_idx)
+ with marked_timer("ref", timing_raw, color="olive"):
+ if not self.ref_in_actor:
+ ref_log_prob_output_meta = self.ref_policy_wg.compute_ref_log_prob(ref_log_prob_meta)
+ else:
+ ref_log_prob_output_meta = self.actor_rollout_wg.compute_ref_log_prob(ref_log_prob_meta)
+ batch_meta = batch_meta.union(ref_log_prob_output_meta)
+
+ # compute values
+ if self.use_critic:
+ with marked_timer("values", timing_raw, color="cyan"):
+ values_meta = self.critic_wg.compute_values(batch_meta)
+ batch_meta = batch_meta.union(values_meta)
+
+ with marked_timer("adv", timing_raw, color="brown"):
+ # we combine with rule-based rm
+ reward_extra_infos_dict: dict[str, list]
+ if self.config.reward_model.launch_reward_fn_async:
+ reward_tensor, reward_extra_infos_dict = ray.get(future_reward)
+ reward_td = TensorDict({"token_level_scores": reward_tensor}, batch_size=reward_tensor.size(0))
+ asyncio.run(self.data_system_client.async_put(data=reward_td, metadata=batch_meta))
+ batch_meta.add_fields(reward_td)
+
+ if reward_extra_infos_dict:
+ reward_extra_infos_dict_new = {k: np.array(v) for k, v in reward_extra_infos_dict.items()}
+ reward_extra_infos_td = self.dict_to_tensordict(reward_extra_infos_dict_new)
+ asyncio.run(
+ self.data_system_client.async_put(data=reward_extra_infos_td, metadata=batch_meta)
+ )
+ batch_meta.add_fields(reward_extra_infos_td)
+
+ # compute rewards. apply_kl_penalty if available
+ if self.config.algorithm.use_kl_in_reward:
+ apply_kl_penalty_fields = [
+ "response_mask",
+ "token_level_scores",
+ "old_log_probs",
+ "ref_log_prob",
+ ]
+ apply_kl_penalty_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=apply_kl_penalty_fields,
+ task_name="apply_kl_penalty",
+ **base_get_meta_kwargs,
+ )
+ )
+ apply_kl_penalty_meta.reorder(balanced_idx)
+ token_level_rewards, kl_metrics = apply_kl_penalty(
+ apply_kl_penalty_meta,
+ kl_ctrl=self.kl_ctrl_in_reward,
+ kl_penalty=self.config.algorithm.kl_penalty,
+ )
+ token_level_rewards_td = TensorDict(
+ {"token_level_rewards": token_level_rewards}, batch_size=token_level_rewards.size(0)
+ )
+ asyncio.run(
+ self.data_system_client.async_put(
+ data=token_level_rewards_td, metadata=apply_kl_penalty_meta
+ )
+ )
+ apply_kl_penalty_meta.add_fields(token_level_rewards_td)
+
+ metrics.update(kl_metrics)
+ batch_meta = batch_meta.union(apply_kl_penalty_meta)
+ else:
+ token_level_scores_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=["token_level_scores"],
+ task_name="token_level_scores",
+ **base_get_meta_kwargs,
+ )
+ )
+ token_level_scores_meta.reorder(balanced_idx)
+ data = asyncio.run(self.data_system_client.async_get_data(token_level_scores_meta))
+ token_level_rewards_td = TensorDict(
+ {"token_level_rewards": data["token_level_scores"]},
+ batch_size=data["token_level_scores"].size(0),
+ )
+ asyncio.run(
+ self.data_system_client.async_put(
+ data=token_level_rewards_td, metadata=token_level_scores_meta
+ )
+ )
+ batch_meta.add_fields(token_level_rewards_td)
+
+ # compute advantages, executed on the driver process
+
+ norm_adv_by_std_in_grpo = self.config.algorithm.get(
+ "norm_adv_by_std_in_grpo", True
+ ) # GRPO adv normalization factor
+
+ assert "response_mask" in batch_meta.field_names, (
+ f"`response_mask` must be in batch_meta {batch_meta.field_names} for advantage computation"
+ )
+ compute_advantage_fields = [
+ "response_mask",
+ "token_level_rewards",
+ ]
+ if self.config.algorithm.adv_estimator == AdvantageEstimator.GAE:
+ compute_advantage_fields.append("values")
+ elif self.config.algorithm.adv_estimator == AdvantageEstimator.GRPO:
+ compute_advantage_fields.append("uid")
+ else:
+ if "uid" in batch_meta.field_names:
+ compute_advantage_fields.append("uid")
+ if "reward_baselines" in batch_meta.field_names:
+ compute_advantage_fields.append("reward_baselines")
+
+ compute_advantage_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=compute_advantage_fields,
+ task_name="compute_advantage",
+ **base_get_meta_kwargs,
+ )
+ )
+ compute_advantage_meta.reorder(balanced_idx)
+
+ advantages, returns = compute_advantage(
+ compute_advantage_meta,
+ adv_estimator=self.config.algorithm.adv_estimator,
+ gamma=self.config.algorithm.gamma,
+ lam=self.config.algorithm.lam,
+ num_repeat=self.config.actor_rollout_ref.rollout.n,
+ norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,
+ config=self.config.algorithm,
+ )
+
+ advantages_td = TensorDict(
+ {"advantages": advantages, "returns": returns}, batch_size=advantages.size(0)
+ )
+ asyncio.run(
+ self.data_system_client.async_put(data=advantages_td, metadata=compute_advantage_meta)
+ )
+ compute_advantage_meta.add_fields(advantages_td)
+
+ batch_meta = batch_meta.union(compute_advantage_meta)
+
+ # update critic
+ if self.use_critic:
+ with marked_timer("update_critic", timing_raw, color="pink"):
+ critic_output_meta = self.critic_wg.update_critic(batch_meta)
+ batch_meta = batch_meta.union(critic_output_meta)
+ critic_output_metrics = reduce_metrics(critic_output_meta.extra_info["metrics"])
+ metrics.update(critic_output_metrics)
+
+ # implement critic warmup
+ if self.config.trainer.critic_warmup <= self.global_steps:
+ # update actor
+ with marked_timer("update_actor", timing_raw, color="red"):
+ batch_meta.extra_info["multi_turn"] = (
+ self.config.actor_rollout_ref.rollout.multi_turn.enable
+ )
+
+ update_actor_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=[
+ "input_ids",
+ "attention_mask",
+ "position_ids",
+ "prompts",
+ "responses",
+ "response_mask",
+ "old_log_probs",
+ "ref_log_prob",
+ "advantages",
+ "returns",
+ "token_level_rewards",
+ "token_level_scores",
+ "data_source",
+ "reward_model",
+ "extra_info",
+ "uid",
+ "index",
+ "tools_kwargs",
+ "interaction_kwargs",
+ "ability",
+ ],
+ batch_size=self.config.data.train_batch_size
+ * self.config.actor_rollout_ref.rollout.n,
+ global_step=self.global_steps - 1,
+ get_n_samples=False,
+ task_name="update_actor",
+ )
+ )
+ update_actor_meta.reorder(balanced_idx)
+ update_actor_meta.set_extra_info(
+ "global_token_num", batch_meta.get_extra_info("global_token_num")
+ )
+ update_actor_meta.set_extra_info("temperature", batch_meta.get_extra_info("temperature"))
+
+ actor_output_meta = self.actor_rollout_wg.update_actor(update_actor_meta)
+ batch_meta = batch_meta.union(actor_output_meta)
+ actor_output_metrics = reduce_metrics(actor_output_meta.extra_info["metrics"])
+ metrics.update(actor_output_metrics)
+
+ # Log rollout generations if enabled
+ rollout_data_dir = self.config.trainer.get("rollout_data_dir", None)
+ if rollout_data_dir:
+ data_fields = ["prompts", "responses", "token_level_scores", "reward_model"]
+ if "request_id" in batch_meta.field_names:
+ data_fields.append("request_id")
+ log_rollout_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=data_fields,
+ batch_size=self.config.data.train_batch_size * self.config.actor_rollout_ref.rollout.n,
+ global_step=self.global_steps - 1,
+ get_n_samples=False,
+ task_name="log_rollout",
+ )
+ )
+ log_rollout_meta.reorder(balanced_idx)
+ self._log_rollout_data(log_rollout_meta, reward_extra_infos_dict, timing_raw, rollout_data_dir)
+
+ # TODO: clear meta after iteration
+
+ # TODO: validate
+ if (
+ self.val_reward_fn is not None
+ and self.config.trainer.test_freq > 0
+ and (is_last_step or self.global_steps % self.config.trainer.test_freq == 0)
+ ):
+ with marked_timer("testing", timing_raw, color="green"):
+ val_metrics: dict = self._validate()
+ if is_last_step:
+ last_val_metrics = val_metrics
+ metrics.update(val_metrics)
+
+ # Check if the ESI (Elastic Server Instance)/training plan is close to expiration.
+ esi_close_to_expiration = should_save_ckpt_esi(
+ max_steps_duration=self.max_steps_duration,
+ redundant_time=self.config.trainer.esi_redundant_time,
+ )
+ # Check if the conditions for saving a checkpoint are met.
+ # The conditions include a mandatory condition (1) and
+ # one of the following optional conditions (2/3/4):
+ # 1. The save frequency is set to a positive value.
+ # 2. It's the last training step.
+ # 3. The current step number is a multiple of the save frequency.
+ # 4. The ESI(Elastic Server Instance)/training plan is close to expiration.
+ if self.config.trainer.save_freq > 0 and (
+ is_last_step or self.global_steps % self.config.trainer.save_freq == 0 or esi_close_to_expiration
+ ):
+ if esi_close_to_expiration:
+ print("Force saving checkpoint: ESI instance expiration approaching.")
+ with marked_timer("save_checkpoint", timing_raw, color="green"):
+ self._save_checkpoint()
+
+ with marked_timer("stop_profile", timing_raw):
+ next_step_profile = (
+ self.global_steps + 1 in self.config.global_profiler.steps
+ if self.config.global_profiler.steps is not None
+ else False
+ )
+ self._stop_profiling(
+ curr_step_profile and not next_step_profile
+ if self.config.global_profiler.profile_continuous_steps
+ else curr_step_profile
+ )
+ prev_step_profile = curr_step_profile
+ curr_step_profile = next_step_profile
+
+ steps_duration = timing_raw["step"]
+ self.max_steps_duration = max(self.max_steps_duration, steps_duration)
+
+ # training metrics
+ metrics.update(
+ {
+ "training/global_step": self.global_steps,
+ "training/epoch": epoch,
+ }
+ )
+ # collect metrics
+ compute_data_metrics_fields = [
+ "token_level_rewards",
+ "token_level_scores",
+ "advantages",
+ "returns",
+ "responses",
+ "attention_mask",
+ "response_mask",
+ ]
+ if "__num_turns__" in batch_meta.field_names:
+ compute_data_metrics_fields.append("__num_turns__")
+ if "tool_call_counts" in batch_meta.field_names:
+ compute_data_metrics_fields.append("tool_call_counts")
+ compute_data_metrics_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=compute_data_metrics_fields,
+ task_name="compute_data_metrics",
+ **base_get_meta_kwargs,
+ )
+ )
+ compute_data_metrics_meta.reorder(balanced_idx)
+ metrics.update(
+ compute_data_metrics_decorated(batch=compute_data_metrics_meta, use_critic=self.use_critic)
+ )
+
+ compute_timing_metrics_fields = ["responses", "attention_mask"]
+ compute_timing_metrics_meta = asyncio.run(
+ self.data_system_client.async_get_meta(
+ data_fields=compute_timing_metrics_fields,
+ task_name="compute_timing_metrics",
+ **base_get_meta_kwargs,
+ )
+ )
+ compute_timing_metrics_meta.reorder(balanced_idx)
+ metrics.update(
+ compute_timing_metrics_decorated(batch=compute_timing_metrics_meta, timing_raw=timing_raw)
+ )
+
+ compute_throughout_metrics_meta = BatchMeta(
+ samples=[],
+ extra_info={"global_token_num": batch_meta.get_extra_info("global_token_num")},
+ )
+ # TODO: implement actual tflpo and theoretical tflpo
+ n_gpus = self.resource_pool_manager.get_n_gpus()
+ metrics.update(
+ compute_throughout_metrics_decorated(
+ batch=compute_throughout_metrics_meta, timing_raw=timing_raw, n_gpus=n_gpus
+ )
+ )
+
+ # this is experimental and may be changed/removed in the future in favor of a general-purpose one
+ if isinstance(self.train_dataloader.sampler, AbstractCurriculumSampler):
+ # TODO: (TQ) support transfer queue
+ self.train_dataloader.sampler.update(batch=batch)
+
+ asyncio.run(self.data_system_client.async_clear(self.global_steps - 1))
+ # TODO: make a canonical logger that supports various backend
+ logger.log(data=metrics, step=self.global_steps)
+
+ progress_bar.update(1)
+ self.global_steps += 1
+
+ if (
+ hasattr(self.config.actor_rollout_ref.actor, "profiler")
+ and self.config.actor_rollout_ref.actor.profiler.tool == "torch_memory"
+ ):
+ self.actor_rollout_wg.dump_memory_snapshot(
+ tag=f"post_update_step{self.global_steps}", sub_dir=f"step{self.global_steps}"
+ )
+
+ if is_last_step:
+ pprint(f"Final validation metrics: {last_val_metrics}")
+ progress_bar.close()
+ return
+
+ # this is experimental and may be changed/removed in the future
+ # in favor of a general-purpose data buffer pool
+ if hasattr(self.train_dataset, "on_batch_end"):
+ # The dataset may be changed after each training batch
+ # TODO: (TQ) support transfer queue
+ self.train_dataset.on_batch_end(batch=batch)
diff --git a/recipe/transfer_queue/run_qwen3-8b_transferqueue_npu.sh b/recipe/transfer_queue/run_qwen3-8b_transferqueue_npu.sh
new file mode 100644
index 00000000000..70b7e23976d
--- /dev/null
+++ b/recipe/transfer_queue/run_qwen3-8b_transferqueue_npu.sh
@@ -0,0 +1,63 @@
+set -x
+
+project_name='GRPO-Qwen3'
+exp_name='GRPO-Qwen3-8B-npu'
+gen_tp=2
+RAY_DATA_HOME=${RAY_DATA_HOME:-"${HOME}/verl"}
+MODEL_PATH=${MODEL_PATH:-"${RAY_DATA_HOME}/models/Qwen3-8B"}
+CKPTS_DIR=${CKPTS_DIR:-"${RAY_DATA_HOME}/ckpts/${project_name}/${exp_name}"}
+TRAIN_FILE=${TRAIN_FILE:-"${RAY_DATA_HOME}/data/dapo-math-17k.parquet"}
+TEST_FILE=${TEST_FILE:-"${RAY_DATA_HOME}/data/aime-2024.parquet"}
+
+python3 -m recipe.transfer_queue.main_ppo \
+ --config-name='transfer_queue_ppo_trainer' \
+ algorithm.adv_estimator=grpo \
+ data.train_files="${TRAIN_FILE}" \
+ data.val_files="${TEST_FILE}" \
+ data.train_batch_size=256 \
+ data.max_prompt_length=512 \
+ data.max_response_length=1024 \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ actor_rollout_ref.model.path=${MODEL_PATH} \
+ actor_rollout_ref.actor.optim.lr=1e-6 \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.actor.ppo_mini_batch_size=64 \
+ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=10 \
+ actor_rollout_ref.actor.use_kl_loss=True \
+ actor_rollout_ref.actor.kl_loss_coef=0.001 \
+ actor_rollout_ref.actor.kl_loss_type=low_var_kl \
+ actor_rollout_ref.actor.entropy_coeff=0 \
+ actor_rollout_ref.actor.use_torch_compile=False \
+ actor_rollout_ref.ref.use_torch_compile=False \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.fsdp_config.param_offload=False \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
+ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \
+ actor_rollout_ref.rollout.name=vllm \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
+ actor_rollout_ref.rollout.n=5 \
+ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.ref.fsdp_config.param_offload=True \
+ algorithm.use_kl_in_reward=False \
+ trainer.critic_warmup=0 \
+ trainer.logger='["console","wandb"]' \
+ trainer.project_name="${project_name}" \
+ trainer.experiment_name="${exp_name}" \
+ trainer.n_gpus_per_node=8 \
+ trainer.nnodes=1 \
+ trainer.default_local_dir=${CKPTS_DIR} \
+ trainer.device=npu \
+ trainer.resume_mode=auto \
+ actor_rollout_ref.actor.fsdp_config.forward_prefetch=True \
+ actor_rollout_ref.ref.fsdp_config.forward_prefetch=True \
+ ++actor_rollout_ref.actor.entropy_from_logits_with_chunking=True \
+ ++actor_rollout_ref.ref.entropy_from_logits_with_chunking=True \
+ trainer.val_before_train=False \
+ trainer.save_freq=5 \
+ trainer.test_freq=5 \
+ trainer.total_epochs=15 \
+ +trainer.num_global_batch=1 \
+ +trainer.num_data_storage_units=2 \
+ +trainer.num_data_controllers=1
\ No newline at end of file
diff --git a/requirements_transferqueue.txt b/requirements_transferqueue.txt
new file mode 100644
index 00000000000..8479d27bb21
--- /dev/null
+++ b/requirements_transferqueue.txt
@@ -0,0 +1,2 @@
+# requirements.txt records the full set of dependencies for development
+git+https://github.com/TransferQueue/TransferQueue.git@68c04e7
diff --git a/setup.py b/setup.py
index 4a86f035d09..b419f7f1af0 100644
--- a/setup.py
+++ b/setup.py
@@ -57,6 +57,7 @@
]
TRL_REQUIRES = ["trl<=0.9.6"]
MCORE_REQUIRES = ["mbridge"]
+TRANSFERQUEUE_REQUIRES = ["TransferQueue @ git+https://github.com/TransferQueue/TransferQueue.git@68c04e7"]
extras_require = {
"test": TEST_REQUIRES,
@@ -68,6 +69,7 @@
"sglang": SGLANG_REQUIRES,
"trl": TRL_REQUIRES,
"mcore": MCORE_REQUIRES,
+ "transferqueue": TRANSFERQUEUE_REQUIRES,
}
diff --git a/tests/special_sanity/check_device_api_usage.py b/tests/special_sanity/check_device_api_usage.py
index 8d3cfda27c8..f33bf704900 100644
--- a/tests/special_sanity/check_device_api_usage.py
+++ b/tests/special_sanity/check_device_api_usage.py
@@ -29,6 +29,7 @@
"recipe/spin/spin_trainer.py", # appear in default device_name
"recipe/sppo/sppo_ray_trainer.py", # appear in default device_name
"recipe/one_step_off_policy/ray_trainer.py", # appear in default device_name
+ "recipe/transfer_queue/ray_trainer.py", # appear in default device_name
"verl/utils/profiler/nvtx_profile.py", # appear in NsightSystemsProfiler
"verl/utils/kernel/linear_cross_entropy.py", # appear in nvidia nvtx
"verl/utils/rendezvous/ray_backend.py", # appear in cupy importance
diff --git a/verl/experimental/agent_loop/agent_loop.py b/verl/experimental/agent_loop/agent_loop.py
index fe54edd51a0..5f452e8ec52 100644
--- a/verl/experimental/agent_loop/agent_loop.py
+++ b/verl/experimental/agent_loop/agent_loop.py
@@ -38,7 +38,12 @@
from verl.utils import hf_processor, hf_tokenizer
from verl.utils.fs import copy_to_local
from verl.utils.model import compute_position_id_with_mask
-from verl.utils.rollout_trace import RolloutTraceConfig, rollout_trace_attr, rollout_trace_op
+from verl.utils.rollout_trace import (
+ RolloutTraceConfig,
+ rollout_trace_attr,
+ rollout_trace_op,
+)
+from verl.utils.transferqueue_utils import tqbridge
from verl.workers.rollout.replica import TokenOutput, get_rollout_replica_class
logger = logging.getLogger(__file__)
@@ -421,6 +426,7 @@ def __init__(
trace_config.get("token2text", False),
)
+ @tqbridge()
async def generate_sequences(self, batch: DataProto) -> DataProto:
"""Generate sequences from agent loop.
@@ -722,6 +728,18 @@ def _postprocess(self, inputs: list[_InternalAgentLoopOutput]) -> DataProto:
meta_info={"metrics": metrics, "reward_extra_keys": reward_extra_keys},
)
+ def create_transferqueue_client(self, controller_infos, storage_infos, role):
+ """Create a client for data system(transfer queue)."""
+ from verl.single_controller.ray.base import get_random_string
+ from verl.utils.transferqueue_utils import create_transferqueue_client
+
+ client_name = get_random_string(length=6)
+ create_transferqueue_client(
+ client_id=f"{role}_worker_{client_name}",
+ controller_infos=controller_infos,
+ storage_infos=storage_infos,
+ )
+
@ray.remote
class AgentLoopWorker(AgentLoopWorkerBase):
diff --git a/verl/single_controller/base/decorator.py b/verl/single_controller/base/decorator.py
index b246aaf7eec..9cab8f3ccdf 100644
--- a/verl/single_controller/base/decorator.py
+++ b/verl/single_controller/base/decorator.py
@@ -18,6 +18,7 @@
from verl.protocol import DataProtoFuture, _padding_size_key
from verl.utils.py_functional import DynamicEnum
+from verl.utils.transferqueue_utils import BatchMeta
# here we add a magic number of avoid user-defined function already have this attribute
MAGIC_ATTR = "attrs_3141562937"
@@ -73,12 +74,12 @@ def _split_args_kwargs_data_proto(chunks, *args, **kwargs):
splitted_args = []
for arg in args:
- assert isinstance(arg, DataProto | DataProtoFuture)
+ assert isinstance(arg, DataProto | DataProtoFuture | BatchMeta)
splitted_args.append(arg.chunk(chunks=chunks))
splitted_kwargs = {}
for key, val in kwargs.items():
- assert isinstance(val, DataProto | DataProtoFuture)
+ assert isinstance(val, DataProto | DataProtoFuture | BatchMeta)
splitted_kwargs[key] = val.chunk(chunks=chunks)
return splitted_args, splitted_kwargs
@@ -146,6 +147,8 @@ def _concat_data_proto_or_future(output: list):
return DataProto.concat(output)
elif isinstance(o, ray.ObjectRef):
return DataProtoFuture.concat(output)
+ elif isinstance(o, BatchMeta):
+ return BatchMeta.concat(output)
else:
raise NotImplementedError
@@ -265,7 +268,9 @@ def collect_nd_compute_dataproto(collect_mask: list[bool], worker_group, output)
from verl.protocol import DataProto
for o in output:
- assert isinstance(o, DataProto | ray.ObjectRef), f"expecting {o} to be DataProto, but got {type(o)}"
+ assert isinstance(o, DataProto | ray.ObjectRef | BatchMeta), (
+ f"expecting {o} to be DataProto or BatchMeta, but got {type(o)}"
+ )
return _concat_data_proto_or_future(output)
@@ -422,10 +427,14 @@ def register(dispatch_mode=Dispatch.ALL_TO_ALL, execute_mode=Execute.ALL, blocki
A decorator that wraps the original function with distributed execution
configuration.
"""
+ from verl.utils.transferqueue_utils import tqbridge
+
_check_dispatch_mode(dispatch_mode=dispatch_mode)
_check_execute_mode(execute_mode=execute_mode)
def decorator(func):
+ func = tqbridge()(func)
+
@wraps(func)
def inner(*args, **kwargs):
if materialize_futures:
diff --git a/verl/single_controller/base/worker.py b/verl/single_controller/base/worker.py
index 59ab27a9c39..2513c57f99c 100644
--- a/verl/single_controller/base/worker.py
+++ b/verl/single_controller/base/worker.py
@@ -130,6 +130,16 @@ def _query_collect_info(self, mesh_name: str):
assert mesh_name in self.__collect_dp_rank, f"{mesh_name} is not registered in {self.__class__.__name__}"
return self.__collect_dp_rank[mesh_name]
+ @register(dispatch_mode=Dispatch.ONE_TO_ALL, blocking=True)
+ def create_transferqueue_client(self, controller_infos, storage_infos, role="train"):
+ from verl.utils.transferqueue_utils import create_transferqueue_client
+
+ create_transferqueue_client(
+ client_id=f"{role}_worker_{self.rank}",
+ controller_infos=controller_infos,
+ storage_infos=storage_infos,
+ )
+
@classmethod
def env_keys(cls):
"""The keys of the environment variables that are used to configure the Worker."""
diff --git a/verl/trainer/config/_generated_ppo_megatron_trainer.yaml b/verl/trainer/config/_generated_ppo_megatron_trainer.yaml
index fc98da09fa4..82ba944f1a8 100644
--- a/verl/trainer/config/_generated_ppo_megatron_trainer.yaml
+++ b/verl/trainer/config/_generated_ppo_megatron_trainer.yaml
@@ -542,6 +542,8 @@ global_profiler:
context: all
stacks: all
kw_args: {}
+transfer_queue:
+ enable: false
ray_kwargs:
ray_init:
num_cpus: null
diff --git a/verl/trainer/config/_generated_ppo_trainer.yaml b/verl/trainer/config/_generated_ppo_trainer.yaml
index f366b0d4579..9cd652d3099 100644
--- a/verl/trainer/config/_generated_ppo_trainer.yaml
+++ b/verl/trainer/config/_generated_ppo_trainer.yaml
@@ -526,6 +526,8 @@ global_profiler:
context: all
stacks: all
kw_args: {}
+transfer_queue:
+ enable: false
ray_kwargs:
ray_init:
num_cpus: null
diff --git a/verl/trainer/config/ppo_megatron_trainer.yaml b/verl/trainer/config/ppo_megatron_trainer.yaml
index 6bdaffe838c..8a23a3b72d4 100644
--- a/verl/trainer/config/ppo_megatron_trainer.yaml
+++ b/verl/trainer/config/ppo_megatron_trainer.yaml
@@ -189,6 +189,12 @@ global_profiler:
# devices, record_context etc.
kw_args: {}
+# configs for TransferQueue
+transfer_queue:
+
+ # Whether to enable transfer queue
+ enable: False
+
ray_kwargs:
ray_init:
num_cpus: null # `None` means using all CPUs, which might cause hang if limited in systems like SLURM. Please set to a number allowed then.
diff --git a/verl/trainer/config/ppo_trainer.yaml b/verl/trainer/config/ppo_trainer.yaml
index b1724e4de48..72c97e4a7cd 100644
--- a/verl/trainer/config/ppo_trainer.yaml
+++ b/verl/trainer/config/ppo_trainer.yaml
@@ -317,6 +317,12 @@ global_profiler:
# devices, record_context etc.
kw_args: {}
+# configs for TransferQueue
+transfer_queue:
+
+ # Whether to enable transfer queue
+ enable: False
+
# configs related to ray
ray_kwargs:
diff --git a/verl/trainer/main_ppo.py b/verl/trainer/main_ppo.py
index b9a357dcfc2..83666084467 100644
--- a/verl/trainer/main_ppo.py
+++ b/verl/trainer/main_ppo.py
@@ -63,11 +63,13 @@ def run_ppo(config, task_runner_class=None) -> None:
runtime_env_kwargs = ray_init_kwargs.get("runtime_env", {})
runtime_env = OmegaConf.merge(default_runtime_env, runtime_env_kwargs)
ray_init_kwargs = OmegaConf.create({**ray_init_kwargs, "runtime_env": runtime_env})
+ if config.transfer_queue.enable:
+ ray_init_kwargs["TRANSFER_QUEUE_ENABLE"] = "1"
print(f"ray init kwargs: {ray_init_kwargs}")
ray.init(**OmegaConf.to_container(ray_init_kwargs))
if task_runner_class is None:
- task_runner_class = TaskRunner
+ task_runner_class = ray.remote(num_cpus=1)(TaskRunner) # please make sure main_task is not scheduled on head
# Create a remote instance of the TaskRunner class, and
# Execute the `run` method of the TaskRunner instance remotely and wait for it to complete
@@ -95,7 +97,6 @@ def run_ppo(config, task_runner_class=None) -> None:
ray.timeline(filename=timeline_json_file)
-@ray.remote(num_cpus=1) # please make sure main_task is not scheduled on head
class TaskRunner:
"""Ray remote class for executing distributed PPO training tasks.
diff --git a/verl/trainer/ppo/reward.py b/verl/trainer/ppo/reward.py
index 5be7a68a330..828206affdd 100644
--- a/verl/trainer/ppo/reward.py
+++ b/verl/trainer/ppo/reward.py
@@ -26,6 +26,7 @@
from verl import DataProto
from verl.utils.reward_score import default_compute_score
+from verl.utils.transferqueue_utils import tqbridge
from verl.workers.reward_manager import get_reward_manager_cls
from verl.workers.reward_manager.abstract import AbstractRewardManager, RawRewardFn
@@ -152,6 +153,7 @@ def load_reward_manager(
)
+@tqbridge(put_data=False)
def compute_reward(data: DataProto, reward_fn: AbstractRewardManager) -> tuple[torch.Tensor, dict[str, Any]]:
"""
Compute reward for a batch of data.
diff --git a/verl/utils/transferqueue_utils.py b/verl/utils/transferqueue_utils.py
new file mode 100644
index 00000000000..27160571ef3
--- /dev/null
+++ b/verl/utils/transferqueue_utils.py
@@ -0,0 +1,211 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import asyncio
+import inspect
+import os
+import threading
+from functools import wraps
+from typing import Any, Callable
+
+from tensordict import TensorDict
+
+try:
+ from transfer_queue import (
+ AsyncTransferQueueClient,
+ BatchMeta,
+ ZMQServerInfo,
+ )
+
+except ImportError:
+ # TODO: Use a hacky workaround for ImportError since
+ # transfer_queue isn't a default verl dependency.
+ class BatchMeta:
+ pass
+
+
+from verl.protocol import DataProto
+
+_TRANSFER_QUEUE_CLIENT = None
+_VAL_TRANSFER_QUEUE_CLIENT = None
+
+is_transferqueue_enabled = os.environ.get("TRANSFER_QUEUE_ENABLE", False)
+
+
+def create_transferqueue_client(
+ client_id: str,
+ controller_infos: dict[Any, "ZMQServerInfo"],
+ storage_infos: dict[Any, "ZMQServerInfo"],
+) -> None:
+ global _TRANSFER_QUEUE_CLIENT
+ global _VAL_TRANSFER_QUEUE_CLIENT
+ if "val" in client_id:
+ _VAL_TRANSFER_QUEUE_CLIENT = AsyncTransferQueueClient(client_id, controller_infos, storage_infos)
+ else:
+ _TRANSFER_QUEUE_CLIENT = AsyncTransferQueueClient(client_id, controller_infos, storage_infos)
+
+
+def get_transferqueue_client() -> "AsyncTransferQueueClient":
+ return _TRANSFER_QUEUE_CLIENT
+
+
+def get_val_transferqueue_client() -> "AsyncTransferQueueClient":
+ return _VAL_TRANSFER_QUEUE_CLIENT
+
+
+def _run_async_in_temp_loop(async_func: Callable[..., Any], *args, **kwargs) -> Any:
+ # Use a temporary event loop in a new thread because event
+ # loop may already exist in server mode
+ tmp_event_loop = asyncio.new_event_loop()
+ thread = threading.Thread(
+ target=tmp_event_loop.run_forever,
+ name="batchmeta dataproto converter",
+ daemon=True,
+ )
+
+ def run_coroutine(coroutine):
+ if not thread.is_alive():
+ thread.start()
+ future = asyncio.run_coroutine_threadsafe(coroutine, tmp_event_loop)
+ return future.result()
+
+ async def stop_loop():
+ tmp_event_loop.stop()
+
+ try:
+ return run_coroutine(async_func(*args, **kwargs))
+ finally:
+ if thread.is_alive():
+ asyncio.run_coroutine_threadsafe(stop_loop(), tmp_event_loop)
+ thread.join()
+
+
+def _find_batchmeta(*args, **kwargs):
+ for arg in args:
+ if isinstance(arg, BatchMeta):
+ return arg
+ for v in kwargs.values():
+ if isinstance(v, BatchMeta):
+ return v
+ return None
+
+
+async def _async_batchmeta_to_dataproto(batchmeta: "BatchMeta") -> DataProto:
+ if batchmeta.samples == [] or batchmeta.samples is None:
+ return DataProto(
+ batch=TensorDict({}, batch_size=(0,)),
+ non_tensor_batch={},
+ meta_info=batchmeta.extra_info.copy(),
+ )
+
+ if batchmeta.extra_info.get("validate", False):
+ tensordict = await _VAL_TRANSFER_QUEUE_CLIENT.async_get_data(batchmeta)
+ else:
+ tensordict = await _TRANSFER_QUEUE_CLIENT.async_get_data(batchmeta)
+ return DataProto.from_tensordict(tensordict, meta_info=batchmeta.extra_info.copy())
+
+
+def _batchmeta_to_dataproto(batchmeta: "BatchMeta") -> DataProto:
+ return _run_async_in_temp_loop(_async_batchmeta_to_dataproto, batchmeta)
+
+
+async def _async_update_batchmeta_with_output(output: DataProto, batchmeta: "BatchMeta") -> None:
+ for k, v in output.meta_info.items():
+ batchmeta.set_extra_info(k, v)
+
+ if len(output) > 0:
+ tensordict = output.to_tensordict()
+ # pop meta_info
+ for key in output.meta_info.keys():
+ tensordict.pop(key)
+ batchmeta.add_fields(tensordict)
+ if batchmeta.extra_info.get("validate", False):
+ await _VAL_TRANSFER_QUEUE_CLIENT.async_put(data=tensordict, metadata=batchmeta)
+ else:
+ await _TRANSFER_QUEUE_CLIENT.async_put(data=tensordict, metadata=batchmeta)
+
+
+def _update_batchmeta_with_output(output: DataProto, batchmeta: "BatchMeta") -> None:
+ _run_async_in_temp_loop(_async_update_batchmeta_with_output, output, batchmeta)
+
+
+def tqbridge(put_data: bool = True):
+ """ "Creates a decorator for bridging BatchMeta and DataProto.
+
+ This decorator automatically handles conversions between `BatchMeta` and
+ `DataProto` in function parameters, and decides whether to sync function
+ output back to `BatchMeta` based on configuration(`put_data`). It supports
+ both synchronous and asynchronous functions (async def), and can control
+ whether to enable enhanced logic via the global `HAS_TQ` variable (when disabled,
+ simply calls the original function as-is).
+
+ Args:
+ put_data: Whether put the DataProto into Storage after func return.
+ If True, after function execution, the output result will be
+ updated to `BatchMeta` and `BatchMeta` will be returned;
+ If False, the function output result will be returned directly.
+ Defaults to True.
+
+ Returns:
+ A decorator function used to decorate target functions (synchronous or asynchronous).
+ """
+
+ def decorator(func):
+ @wraps(func)
+ def inner(*args, **kwargs):
+ batchmeta = _find_batchmeta(*args, **kwargs)
+ if batchmeta is None:
+ return func(*args, **kwargs)
+ else:
+ args = [_batchmeta_to_dataproto(arg) if isinstance(arg, BatchMeta) else arg for arg in args]
+ kwargs = {k: _batchmeta_to_dataproto(v) if isinstance(v, BatchMeta) else v for k, v in kwargs.items()}
+ output = func(*args, **kwargs)
+ if put_data:
+ _update_batchmeta_with_output(output, batchmeta)
+ return batchmeta
+ else:
+ return output
+
+ @wraps(func)
+ async def async_inner(*args, **kwargs):
+ batchmeta = _find_batchmeta(*args, **kwargs)
+ if batchmeta is None:
+ return await func(*args, **kwargs)
+ else:
+ args = [await _async_batchmeta_to_dataproto(arg) if isinstance(arg, BatchMeta) else arg for arg in args]
+ kwargs = {
+ k: await _async_batchmeta_to_dataproto(v) if isinstance(v, BatchMeta) else v
+ for k, v in kwargs.items()
+ }
+ output = await func(*args, **kwargs)
+ if put_data:
+ await _async_update_batchmeta_with_output(output, batchmeta)
+ return batchmeta
+ return output
+
+ @wraps(func)
+ def dummy_inner(*args, **kwargs):
+ return func(*args, **kwargs)
+
+ @wraps(func)
+ async def dummy_async_inner(*args, **kwargs):
+ return await func(*args, **kwargs)
+
+ wrapper_inner = inner if is_transferqueue_enabled else dummy_inner
+ wrapper_async_inner = async_inner if is_transferqueue_enabled else dummy_async_inner
+
+ wrapper = wrapper_async_inner if inspect.iscoroutinefunction(func) else wrapper_inner
+ return wrapper
+
+ return decorator