Real-time ASL (American Sign Language) recognition from Meta AI glasses, streamed via WhatsApp Desktop (or macOS continuity camera) to a web app. Uses MediaPipe Tasks (browser) to extract landmarks and a TFLite model (Python FastAPI) to translate landmarks to text.
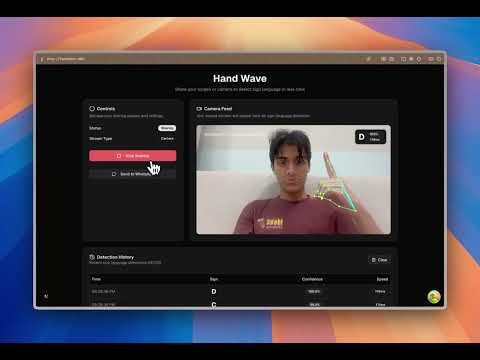
Real-time stream from glasses with hand landmark detection and ASL translation.
- Prototype; not production-ready
- WhatsApp transport (lower latency than Instagram Live)
- Hand landmark detection and translation working end-to-end
- Audio readout to glasses in progress
- We are actively training a better ASL model tailored to our pipeline and dataset.
- For demo purposes, we temporarily use models inspired by and structured after CMU ETC Questure’s open-source work. Please see their repository for details and credit: Questure Tracker (Apache-2.0).
- If you use our demo configuration, attribute Questure appropriately and respect their license.
Prerequisites:
- Meta AI glasses
- iPhone (Sender) with WhatsApp (Account A)
- Laptop (Receiver) with WhatsApp Desktop (Account B)
- Two WhatsApp accounts
- Bun (monorepo uses Bun workspaces)
Install and run:
bun install
bun run devThis starts:
- Web app:
https://localhost:3001 - tRPC server:
https://localhost:3000 - Inference service:
http://localhost:8000
- On the phone (Account A), pair the glasses and open WhatsApp
- On the laptop (Account B), open WhatsApp Desktop
- Start a WhatsApp video call between Account A and Account B
- On the glasses, double-tap the picture button to switch the call's camera to the glasses
- Open
https://localhost:3001and click "Share Screen"; select the WhatsApp call window - The browser runs on-device hand detection and sends landmarks to the inference service for translation
- Audio readback to the glasses is WIP
Video & Detection Path:
- Video: Glasses → Phone → WhatsApp → Laptop → Browser screen share
- Detection: Browser MediaPipe Tasks: Face, Pose, Hand landmarkers (WASM) combined in-app
- Translation: Landmarks (not raw frames) → FastAPI Inference Service → TFLite models (static and movement)
- Output: Text in browser; TTS back to glasses (WIP)
Privacy:
- No raw video frames are uploaded
- Only hand landmark coordinates are sent to the inference service
Meta AI Glasses
↓ video stream
WhatsApp Call
↓ screen share
Browser (MediaPipe Face/Pose/Hand)
↓ landmarks [frames, keypoints, (x,y,z)]
FastAPI Inference (port 8000)
↓ TFLite Models (static_model.tflite, movement_model.tflite)
↓ prediction
Browser UI (tRPC optional)
↓ (future) TTS
Meta Glasses audio
Web (apps/web):
- Next.js 15, React 19, TypeScript
- Tailwind CSS 4, shadcn/ui
- MediaPipe Tasks Vision (Face, Pose, Hand landmarkers; combined holistically)
- Zustand, TanStack Query 5
Backend (apps/server):
- tRPC 11 over Hono (Bun runtime)
- Optional in this flow; browser can call FastAPI directly
Inference (apps/inference):
- FastAPI (Python)
- TensorFlow Lite
- Static and movement models (TFLite). While we train our own, demo may use models aligned with Questure’s structure. See Attribution above.
Monorepo:
- Turbo + Bun workspaces
apps/
web/ # Next.js app (UI, screen share, hand detection)
server/ # Bun + Hono + tRPC API
inference/ # FastAPI + TFLite inference service
Run from repository root:
bun run dev # Start all services (web HTTPS:3001, server, inference)
bun run build # Build all apps
bun run check-types # Typecheck all apps
bun run dev:web # Web only
bun run dev:server # Server onlyFor inference service only:
cd apps/inference
uv run uvicorn src.main:app --reload --port 8000Create a .env file at the repository root:
NEXT_PUBLIC_SERVER_URL=https://localhost:3000
PORT=3000
CORS_ORIGIN=https://localhost:3001Web (apps/web):
NEXT_PUBLIC_SERVER_URL– tRPC server URL
Server (apps/server):
PORT– Server port (default: 3000)CORS_ORIGIN– Allowed CORS origin
Place the following in apps/inference/models/:
static_model.tflite– single-frame classifiermovement_model.tflite– sequence classifierlabel.csv– label mapping
We are training new models. For demos, you may mirror the file layout informed by Questure’s repo. Credit: Questure Tracker (Apache-2.0).
"Share Screen" doesn't list WhatsApp window:
- Ensure the call is active and the window is visible
- macOS: Grant Screen Recording permission to your browser (System Settings → Privacy & Security → Screen Recording)
- Browser must use HTTPS;
getDisplayMediarequires a secure context
Model not found:
Warning: No model found at .../models/static_model.tflite
Place static_model.tflite, movement_model.tflite, and label.csv in apps/inference/models/
TensorFlow errors:
cd apps/inference
uv add tensorflowWrong input shape: The model expects exactly 130 landmarks per frame (21 left hand + 21 right hand + face + pose landmarks). Check MediaPipe configuration.
Inference Service:
- Swagger UI: http://localhost:8000/docs
- ReDoc: http://localhost:8000/redoc
Endpoints:
GET /health- Health checkPOST /predict- Predict ASL text from landmarks
- Hackathon-grade prototype, not production-ready
- In-glasses audio readout not yet implemented
- No authentication or multi-user coordination
- No recording controls or session management
- Complete text-to-speech back to the glasses
- Improve model accuracy and add gesture classification
- Add authentication and session management
- Recording controls and replay functionality
- Multi-user support
See LICENSE file for details.