Low Resource Black-Box End-to-End Attack Against State of the Art API Call Based Malware Classifiers #2
Description
公開日
2018-04-23
1. 概要
adversarial examplesによってAPIコールを追加し、必要な情報量が少なくて強い攻撃を作成するフレームワークを作成した。
2. 新規性・差分
adversarial attacksを3種類紹介
1)Gradient based attacks
- 効果的だが、分類機の情報が必要
- 無理に動的な情報に対応するのは諦めた→より実現可能なものになった
2)Score based attacks
- ブラックボックスだと勾配やconfidence score情報が得られないため難しい
3)Decision based attacks
- ラベル情報のみを使う。入力にノイズを徐々に加えて行く
以下のところが先行研究との違い - 先行研究はCNNモデルのみに対して、本研究はRNNを用いた最先端モデルにも対応
- 先行研究は画像ベースでピクセル変えたらAPIコールが壊れるとかいろいろあったけど本研究はない
- 先行研究はend-to-endなフレームワークを提示しなかった
3. 手法
2つの攻撃を用意
1)Random Perturbation and Benign Perturbation Linear Iteration Attack
- Adversarialなマルウェアを作る際は、APIコールの修正・削除は禁止(挙動が変わったりするため)
- 基本的に挙動の変わらないAPIコール追加のみを行う

2)Logarithmic Backtracking Attack
- ブラックボックステストの試行回数を減らせる
- Linear Iteration Attackの奴の改良版っぽいアルゴリズム3の奴を使ってアルゴリズム2に示す方法で行う


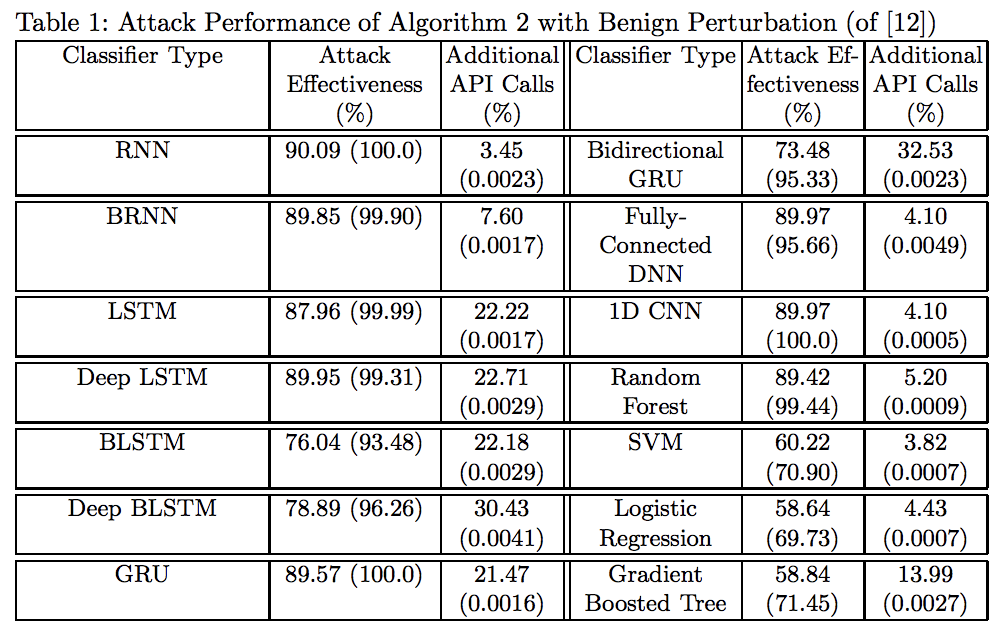
4. 結果
追加するAPIコールの割合と精度を使って有効性を検証した。
5. 議論
機能を変更しないAPIコールの追加方法や多種類特徴を用いたものや多クラス分類のハンドリングなど様々なことが結果の後で説明されている。
6. コメント
興味深いので、もうちょい色々なモデルで試した結果が知りたい。