diff --git a/README_ja.md b/README_ja.md
new file mode 100644
index 0000000..caa0303
--- /dev/null
+++ b/README_ja.md
@@ -0,0 +1,57 @@
+# Model Context Protocol (MCP) コース
+
+
+
+
+
+このコースが気に入ったら、**ぜひ⭐このリポジトリにスターをつけてください**。これにより**コースの可視性を高める🤗**ことができます。
+
+ +
+## 内容
+
+このコースは4つのユニットに分かれています。**Model Context Protocolの基礎からAIアプリケーションでMCPを実装する最終プロジェクト**まで学習できます。
+
+こちらから登録してください(無料です)👉 [近日公開]
+
+コースはこちらからアクセスできます 👉 [近日公開]
+
+| ユニット | トピック | 説明 |
+| ------- | --------------------------------------------------- | ------------------------------------------------------------------------------------------------------- |
+| 0 | コースへようこそ | ウェルカム、ガイドライン、必要なツール、コース概要 |
+| 1 | Model Context Protocolの紹介 | MCPの定義、主要概念、AIモデルと外部データ・ツールを接続する役割 |
+| 2 | MCPを使った構築:実践的開発 | 利用可能なSDKとフレームワークを使用してMCPクライアントとサーバーの実装を学習 |
+| 3 | MCPプロトコル詳細解説 | 高度なMCP機能、アーキテクチャ、実世界での統合パターンを探索 |
+| 4 | ボーナスユニット & コラボレーション | 特別なトピック、パートナーライブラリ、コミュニティ主導のプロジェクト |
+
+## 前提条件
+
+* AIとLLM概念の基本的理解
+* ソフトウェア開発原則とAPI概念に精通していること
+* 少なくとも1つのプログラミング言語の経験(PythonまたはTypeScriptの例を重視します)
+
+## 貢献ガイドライン
+
+このコースに貢献したい場合は、歓迎いたします。お気軽にissueを作成するか、プルリクエストを提出してください。具体的な貢献については、以下のガイドラインをご参照ください:
+
+### 小さなタイポや文法の修正
+
+小さなタイポや文法の間違いを見つけた場合は、ご自身で修正してプルリクエストを提出してください。これは学習者にとって非常に有用です。
+
+### 新しいユニット
+
+新しいユニットを追加したい場合は、**リポジトリにissueを作成し、そのユニットについて説明し、なぜ追加すべきかを記述してください**。議論を行い、良い追加であれば協力して作業することができます。
+
+## プロジェクトの引用
+
+出版物でこのリポジトリを引用する場合:
+
+```
+@misc{mcp-course,
+ author = {Burtenshaw, Ben and Notov, Alex},
+ title = {The Model Context Protocol Course},
+ year = {2025},
+ howpublished = {\url{https://github.com/huggingface/mcp-course}},
+ note = {GitHub repository},
+}
+```
\ No newline at end of file
diff --git a/units/ja/_toctree.yml b/units/ja/_toctree.yml
new file mode 100644
index 0000000..a863654
--- /dev/null
+++ b/units/ja/_toctree.yml
@@ -0,0 +1,82 @@
+- title: "0. MCPコースへようこそ"
+ sections:
+ - local: unit0/introduction
+ title: MCPコースへようこそ
+
+- title: "1. Model Context Protocolの紹介"
+ sections:
+ - local: unit1/introduction
+ title: Model Context Protocol (MCP)の紹介
+ - local: unit1/key-concepts
+ title: 主要概念と用語
+ - local: unit1/architectural-components
+ title: アーキテクチャコンポーネント
+ - local: unit1/quiz1
+ title: クイズ1 - MCP基礎
+ - local: unit1/communication-protocol
+ title: 通信プロトコル
+ - local: unit1/capabilities
+ title: MCP機能の理解
+ - local: unit1/sdk
+ title: MCP SDK
+ - local: unit1/quiz2
+ title: クイズ2 - MCP SDK
+ - local: unit1/mcp-clients
+ title: MCPクライアント
+ - local: unit1/gradio-mcp
+ title: Gradio MCP統合
+ - local: unit1/unit1-recap
+ title: ユニット1まとめ
+ - local: unit1/certificate
+ title: 証明書を取得しよう!
+
+- title: "2. ユースケース: エンドツーエンドMCPアプリケーション"
+ sections:
+ - local: unit2/introduction
+ title: MCPアプリケーション構築の紹介
+ - local: unit2/gradio-server
+ title: Gradio MCPサーバーの構築
+ - local: unit2/clients
+ title: アプリケーションでのMCPクライアントの使用
+ - local: unit2/continue-client
+ title: AIコーディングアシスタントでのMCPの使用
+ - local: unit2/gradio-client
+ title: GradioでのMCPクライアント構築
+ - local: unit2/tiny-agents
+ title: MCPとHugging Face Hubを使ったTiny Agentsの構築
+
+- title: "3. 高度なMCP開発: カスタムワークフローサーバー"
+ sections:
+ - local: unit3/introduction
+ title: Claude Code用カスタムワークフローサーバーの構築
+ - local: unit3/build-mcp-server
+ title: "モジュール1: MCPサーバーの構築"
+ - local: unit3/github-actions-integration
+ title: "モジュール2: GitHub Actions統合"
+ - local: unit3/slack-notification
+ title: "モジュール3: Slack通知"
+ - local: unit3/build-mcp-server-solution-walkthrough
+ title: "ユニット3解答例: MCPを使ったプルリクエストエージェントの構築"
+ - local: unit3/certificate
+ title: "証明書を取得しよう!"
+ - local: unit3/conclusion
+ title: "ユニット3まとめ"
+
+- title: "3.1. ユースケース: Hub上でのプルリクエストエージェントの構築"
+ sections:
+ - local: unit3_1/introduction
+ title: Hugging Face Hub上でのプルリクエストエージェントの構築
+ - local: unit3_1/setting-up-the-project
+ title: プロジェクトのセットアップ
+ - local: unit3_1/creating-the-mcp-server
+ title: MCPサーバーの作成
+ - local: unit3_1/quiz1
+ title: クイズ1 - MCPサーバー実装
+ - local: unit3_1/mcp-client
+ title: MCPクライアント
+ - local: unit3_1/webhook-listener
+ title: Webhookリスナー
+ - local: unit3_1/quiz2
+ title: クイズ2 - プルリクエストエージェント統合
+ - local: unit3_1/conclusion
+ title: まとめ
diff --git a/units/ja/unit0/introduction.mdx b/units/ja/unit0/introduction.mdx
new file mode 100644
index 0000000..a2cbc19
--- /dev/null
+++ b/units/ja/unit0/introduction.mdx
@@ -0,0 +1,144 @@
+# 🤗 Model Context Protocol (MCP) コースへようこそ
+
+
+
+今日のAIにおいて最も注目すべきトピック、**Model Context Protocol (MCP)**へようこそ!
+
+この無料コースは[Anthropic](https://www.anthropic.com)とのパートナーシップで構築され、MCPの理解、使用、アプリケーション構築について、**初心者から熟練者まで**の旅路にお連れします。
+
+この最初のユニットでは、オンボーディングをお手伝いします:
+
+* **コースのシラバス**を発見する。
+* **認定プロセスとスケジュールに関する詳細情報**を取得する。
+* コース制作チームを知る。
+* **アカウント**を作成する。
+* **Discordサーバーにサインアップ**し、クラスメートや私たちと出会う。
+
+始めましょう!
+
+## このコースに何を期待できますか?
+
+このコースでは、以下のことを行います:
+
+* 📖 Model Context Protocolを**理論、設計、実践**で学習する。
+* 🧑💻 **確立されたMCP SDKとフレームワークの使用方法**を学ぶ。
+* 💾 **プロジェクトを共有**し、コミュニティが作成したアプリケーションを探索する。
+* 🏆 **他の学生のMCP実装と自分の実装を評価**するチャレンジに参加する。
+* 🎓 課題を完了することで**修了証書を取得**する。
+
+その他にも多くのことがあります!
+
+このコースの最後には、**MCPがどのように動作し、最新のMCP標準を使用して外部データやツールを活用する独自のAIアプリケーションを構築する方法**を理解できるようになります。
+
+[**コースにサインアップ**](https://huggingface.co/mcp-course)することをお忘れなく!
+
+## コースはどのような構成ですか?
+
+コースは以下で構成されています:
+
+* _基礎ユニット_: MCPの**概念を理論で**学ぶ部分。
+* _ハンズオン_: **確立されたMCP SDK**を使用してアプリケーションを構築することを学ぶ部分。これらのハンズオンセクションには事前設定された環境があります。
+* _ユースケース課題_: 学習した概念を適用して、あなたが選択する実世界の問題を解決する部分。
+* _コラボレーション_: Hugging Faceのパートナーと協力して、最新のMCP実装とツールを提供します。
+
+この**コースは生きているプロジェクトであり、あなたのフィードバックと貢献によって進化しています!** GitHubでのissueやPRの開設、Discordサーバーでの議論への参加をお気軽にどうぞ。
+
+## シラバスは何ですか?
+
+以下が**コースの一般的なシラバス**です。各ユニットのリリース時により詳細なトピックリストが公開されます。
+
+| チャプター | トピック | 説明 |
+| ------- | ------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------- |
+| 0 | オンボーディング | 使用するツールとプラットフォームをセットアップする。 |
+| 1 | MCP基礎、アーキテクチャ、コア概念 | Model Context Protocolのコア概念、アーキテクチャ、コンポーネントを説明する。MCPを使用したシンプルなユースケースを示す。 |
+| 2 | エンドツーエンドユースケース: MCP in Action | コミュニティと共有できるシンプルなエンドツーエンドMCPアプリケーションを構築する。 |
+| 3 | デプロイされたユースケース: MCP in Action | Hugging Faceエコシステムとパートナーのサービスを使用してデプロイされたMCPアプリケーションを構築する。 |
+| 4 | ボーナスユニット | パートナーのライブラリとサービスを使用して、コースからより多くを得るためのボーナスユニット。 |
+
+## 前提条件は何ですか?
+
+このコースを受講するためには、以下が必要です:
+
+* AIとLLM概念の基本的な理解
+* ソフトウェア開発原則とAPI概念の熟知
+* 少なくとも一つのプログラミング言語の経験(PythonまたはTypeScriptの例が表示されます)
+
+これらのいずれかを持っていなくても心配しないでください!以下のリソースが役立ちます:
+
+* [LLMコース](https://huggingface.co/learn/llm-course/)では、LLMの使用と構築の基礎をガイドします。
+* [エージェントコース](https://huggingface.co/learn/agents-course/)では、LLMを使用したAIエージェントの構築をガイドします。
+
+
+
+上記のコースは前提条件ではありませんので、LLMとエージェントの概念を理解していれば、今すぐコースを開始できます!
+
+
+
+## どのようなツールが必要ですか?
+
+必要なものは2つだけです:
+
+* インターネット接続のある_コンピューター_。
+* _アカウント_: コースリソースにアクセスし、プロジェクトを作成するため。まだアカウントをお持ちでない場合は、[こちら](https://huggingface.co/join)で作成できます(無料です)。
+
+## 認定プロセス
+
+このコースを_聴講モード_で受講することも、活動を行って_私たちが発行する2つの証明書のいずれかを取得_することもできます。コースを聴講する場合、すべてのチャレンジに参加し、希望すれば課題を行うことができ、**私たちに通知する必要はありません**。
+
+認定プロセスは**完全に無料**です:
+
+* _基礎の認定を取得する_: コースのユニット1を完了する必要があります。これは、完全なアプリケーションを構築する必要なく、MCPの最新トレンドを把握したい学生を対象としています。
+* _修了証書を取得する_: ユースケースユニット(2と3)を完了する必要があります。これは、完全なアプリケーションを構築してコミュニティと共有したい学生を対象としています。
+
+## 推奨ペースは何ですか?
+
+このコースの各チャプターは**1週間で完了するように設計されており、週に約3-4時間の作業時間**です。
+
+期限があるため、推奨ペースを提供します:
+
+
+
+## コースを最大限活用するには?
+
+コースを最大限活用するために、以下のアドバイスがあります:
+
+1. [Discordで学習グループに参加](https://discord.gg/UrrTSsSyjb): グループで学習することは常により簡単です。そのためには、私たちのdiscordサーバーに参加し、アカウントを認証する必要があります。
+2. **クイズと課題を行う**: 学習の最良の方法は実践的な練習と自己評価です。
+3. **同期を保つためのスケジュールを定義**: 以下の推奨ペーススケジュールを使用するか、独自のものを作成できます。
+
+
+
+## 私たちについて
+
+著者について:
+
+### Ben Burtenshaw
+
+BenはHugging FaceのMachine Learning Engineerで、ポストトレーニングとエージェンティックアプローチを使用したLLMアプリケーションの構築に焦点を当てています。[HubでBenをフォロー](https://huggingface.co/burtenshaw)して、彼の最新プロジェクトを見てください。
+
+### Alex Notov
+
+Alexは[Anthropic](https://www.anthropic.com)のTechnical Partner Enablement Leadで、このコースのユニット3に取り組みました。AlexはAnthropicのパートナーに対して、それぞれのユースケースでのClaudeのベストプラクティスをトレーニングしています。Alexを[LinkedIn](https://linkedin.com/in/zealoushacker)と[GitHub](https://github.com/zealoushacker)でフォローしてください。
+
+## 謝辞
+
+貴重な貢献とサポートをいただいた以下の個人とパートナーに感謝いたします:
+
+- [Gradio](https://www.gradio.app/)
+- [Continue](https://continue.dev)
+- [Llama.cpp](https://github.com/ggerganov/llama.cpp)
+- [Anthropic](https://www.anthropic.com)
+
+## バグを見つけた、またはコースを改善したい
+
+貢献は**歓迎**です 🤗
+
+* _ノートブックでバグ🐛を見つけた_場合は、[issueを開いて](https://github.com/huggingface/mcp-course/issues/new)**問題を説明**してください。
+* _コースを改善したい_場合は、[Pull Requestを開く](https://github.com/huggingface/mcp-course/pulls)ことができます。
+* _完全なセクションや新しいユニットを追加したい_場合は、[issueを開いて](https://github.com/huggingface/mcp-course/issues/new)**書き始める前に追加したいコンテンツを説明**し、私たちがガイドできるようにすることが最善です。
+
+## まだ質問があります
+
+discordサーバーの#mcp-course-questionsで質問してください。
+
+すべての情報を得たので、さあ始めましょう ⛵
diff --git a/units/ja/unit1/architectural-components.mdx b/units/ja/unit1/architectural-components.mdx
new file mode 100644
index 0000000..4b084c2
--- /dev/null
+++ b/units/ja/unit1/architectural-components.mdx
@@ -0,0 +1,85 @@
+# MCPのアーキテクチャコンポーネント
+
+前のセクションでは、MCPの主要概念と用語について説明しました。今度は、MCPエコシステムを構成するアーキテクチャコンポーネントについてより深く掘り下げてみましょう。
+
+## ホスト、クライアント、サーバー
+
+Model Context Protocol(MCP)は、AIモデルと外部システム間の構造化された通信を可能にするクライアント・サーバー・アーキテクチャ上に構築されています。
+
+
+
+MCPアーキテクチャは、それぞれ明確に定義された役割と責任を持つ3つの主要コンポーネントで構成されています:ホスト、クライアント、サーバー。前のセクションでこれらについて触れましたが、各コンポーネントとその責任についてより深く掘り下げてみましょう。
+
+### ホスト
+
+**ホスト**は、エンドユーザーが直接インタラクトするユーザー向けAIアプリケーションです。
+
+例として以下があります:
+- OpenAI ChatGPTやAnthropicのClaude DesktopのようなAIチャットアプリ
+- CursorのようなAI強化IDE、またはContinue.devのようなツールとの統合
+- LangChainやsmolagentsのようなライブラリで構築されたカスタムAIエージェントやアプリケーション
+
+ホストの責任には以下が含まれます:
+- ユーザーインタラクションと許可の管理
+- MCPクライアントを介したMCPサーバーへの接続開始
+- ユーザーリクエスト、LLM処理、外部ツール間の全体的なフローの統率
+- 結果を一貫した形式でユーザーに渡すレンダリング
+
+ほとんどの場合、ユーザーはニーズと好みに基づいてホストアプリケーションを選択します。たとえば、開発者は強力なコード編集機能を求めてCursorを選択するかもしれませんし、ドメインエキスパートはsmolagentsで構築されたカスタムアプリケーションを使用するかもしれません。
+
+### クライアント
+
+**クライアント**は、特定のMCPサーバーとのコミュニケーションを管理するホストアプリケーション内のコンポーネントです。主要な特徴には以下が含まれます:
+
+- 各クライアントは単一のサーバーとの1:1接続を維持します
+- MCPコミュニケーションのプロトコルレベルの詳細を処理します
+- ホストのロジックと外部サーバー間の中介役として機能します
+
+### サーバー
+
+**サーバー**は、MCPプロトコルを介してAIモデルに機能を公開する外部プログラムまたはサービスです。サーバーは:
+
+- 特定の外部ツール、データソース、またはサービスへのアクセスを提供します
+- 既存の機能の周りの軽量なラッパーとして機能します
+- ローカル(ホストと同じマシン上)またはリモート(ネットワーク経由)で実行できます
+- クライアントが発見し、使用できる標準化された形式で機能を公開します
+
+## コミュニケーションフロー
+
+一般的なMCPワークフローでこれらのコンポーネントがどのようにインタラクトするかを検討してみましょう:
+
+
+
+次のセクションでは、これらのコンポーネントを実用的な例で可能にするコミュニケーションプロトコルについてより深く掘り下げていきます。
+
+
+
+1. **ユーザーインタラクション**: ユーザーが**ホスト**アプリケーションとインタラクトし、意図やクエリを表現します。
+
+2. **ホスト処理**: **ホスト**がユーザーの入力を処理し、リクエストを理解し、どの外部機能が必要になる可能性があるかを決定するためにLLMを使用する可能性があります。
+
+3. **クライアント接続**: **ホスト**がその**クライアント**コンポーネントに適切なサーバーに接続するよう指示します。
+
+4. **機能発見**: **クライアント**が**サーバー**にクエリを送って、どのような機能(ツール、リソース、プロンプト)を提供しているかを発見します。
+
+5. **機能呼び出し**: ユーザーのニーズやLLMの判断に基づいて、ホストが**クライアント**に**サーバー**から特定の機能を呼び出すよう指示します。
+
+6. **サーバー実行**: **サーバー**がリクエストされた機能を実行し、結果を**クライアント**に返します。
+
+7. **結果統合**: **クライアント**がこれらの結果を**ホスト**に中継し、ホストはそれらをLLMのコンテキストに組み込むか、直接ユーザーに提示します。
+
+このアーキテクチャの主要な利点は、そのモジュラー性です。単一の**ホスト**が異なる**クライアント**を介して複数の**サーバー**に同時に接続できます。新しい**サーバー**を既存の**ホスト**の変更を必要とせずにエコシステムに追加できます。機能を異なる**サーバー**間で簡単に組み合わせることができます。
+
+
+
+前のセクションで議論したように、このモジュラー性は、伝統的なM×N統合問題(M個のAIアプリケーションがN個のツール/サービスに接続)を、各ホストとサーバーがMCP標準を一度だけ実装するより管理しやすいM+N問題に変換します。
+
+
+
+アーキテクチャはシンプルに見えるかもしれませんが、その力はコミュニケーションプロトコルの標準化とコンポーネント間の責任の明確な分離にあります。この設計により、AIモデルが常に成長し続ける外部ツールやデータソースの配列とシームレスに接続できる結束力のあるエコシステムが可能になります。
+
+## 結論
+
+これらのインタラクションパターンは、MCPの設計と進化を形作るいくつかの主要原則によってガイドされています。プロトコルはAI接続のための普遍的プロトコルを提供することで**標準化**を強調し、コアプロトコルを直接的に保ちながら高度な機能を可能にすることで**シンプルさ**を維持します。機密な操作に対して明示的なユーザー承認を要求することで**安全性**が優先され、発見性は機能の動的発見を可能にします。プロトコルは**拡張性**を念頭に置いて構築され、バージョニングと機能交渉を通じて進化をサポートし、異なる実装と環境間での**相互運用性**を保証します。
+
+次のセクションでは、これらのコンポーネントが効果的に連携できるようにするコミュニケーションプロトコルを探求していきます。
\ No newline at end of file
diff --git a/units/ja/unit1/capabilities.mdx b/units/ja/unit1/capabilities.mdx
new file mode 100644
index 0000000..29f8cb4
--- /dev/null
+++ b/units/ja/unit1/capabilities.mdx
@@ -0,0 +1,243 @@
+# MCP機能の理解
+
+MCPサーバーは、通信プロトコルを通じてクライアントに様々な機能を公開します。これらの機能は4つの主要カテゴリーに分類され、それぞれが異なる特性とユースケースを持ちます。MCPの機能の基盤を形成するこれらのコアプリミティブを探求してみましょう。
+
+
+
+このセクションでは、各言語でフレームワーク非依存の関数として例を示します。これは、フレームワークの複雑さではなく、概念とそれらがどのように連携するかに焦点を当てるためです。
+
+今後のユニットでは、これらの概念がMCP固有のコードでどのように実装されるかを示します。
+
+
+
+## ツール
+
+ツールは、AIモデルがMCPプロトコルを通じて呼び出すことができる実行可能な関数またはアクションです。
+
+- **制御**: ツールは通常**モデル制御**であり、AIモデル(LLM)がユーザーのリクエストとコンテキストに基づいていつ呼び出すかを決定します。
+- **安全性**: 副作用を伴うアクションを実行する能力があるため、ツールの実行は危険な場合があります。そのため、通常、明示的なユーザー承認が必要です。
+- **ユースケース**: メッセージの送信、チケットの作成、APIのクエリ、計算の実行。
+
+**例**: 指定した場所の現在の天気データを取得する天気ツール:
+
+
+
+
+```python
+def get_weather(location: str) -> dict:
+ """Get the current weather for a specified location."""
+ # Connect to weather API and fetch data
+ return {
+ "temperature": 72,
+ "conditions": "Sunny",
+ "humidity": 45
+ }
+```
+
+
+
+
+```javascript
+function getWeather(location) {
+ // Connect to weather API and fetch data
+ return {
+ temperature: 72,
+ conditions: 'Sunny',
+ humidity: 45
+ };
+}
+```
+
+
+
+
+## リソース
+
+リソースはデータソースへの読み取り専用アクセスを提供し、AIモデルが複雑なロジックを実行することなくコンテキストを取得できるようにします。
+
+- **制御**: リソースは**アプリケーション制御**であり、ホストアプリケーションが通常、いつアクセスするかを決定します。
+- **性質**: REST APIのGETエンドポイントと同様に、最小限の計算でデータ取得用に設計されています。
+- **安全性**: 読み取り専用であるため、通常ツールよりもセキュリティリスクが低くなります。
+- **ユースケース**: ファイルコンテンツのアクセス、データベースレコードの取得、設定情報の読み取り。
+
+**例**: ファイルコンテンツへのアクセスを提供するリソース:
+
+
+
+
+```python
+def read_file(file_path: str) -> str:
+ """Read the contents of a file at the specified path."""
+ with open(file_path, 'r') as f:
+ return f.read()
+```
+
+
+
+
+```javascript
+function readFile(filePath) {
+ // Using fs.readFile to read file contents
+ const fs = require('fs');
+ return new Promise((resolve, reject) => {
+ fs.readFile(filePath, 'utf8', (err, data) => {
+ if (err) {
+ reject(err);
+ return;
+ }
+ resolve(data);
+ });
+ });
+}
+```
+
+
+
+
+## プロンプト
+
+プロンプトは、ユーザー、AIモデル、サーバーの機能間のインタラクションをガイドする事前定義されたテンプレートまたはワークフローです。
+
+- **制御**: プロンプトは**ユーザー制御**であり、しばしばホストアプリケーションのUIでオプションとして提示されます。
+- **目的**: 利用可能なツールとリソースの最適な使用のためにインタラクションを構造化します。
+- **選択**: ユーザーは通常、AIモデルが処理を開始する前にプロンプトを選択し、インタラクションのコンテキストを設定します。
+- **ユースケース**: 一般的なワークフロー、特化タスクテンプレート、ガイド付きインタラクション。
+
+**例**: コードレビューを生成するためのプロンプトテンプレート:
+
+
+
+
+```python
+def code_review(code: str, language: str) -> list:
+ """Generate a code review for the provided code snippet."""
+ return [
+ {
+ "role": "system",
+ "content": f"You are a code reviewer examining {language} code. Provide a detailed review highlighting best practices, potential issues, and suggestions for improvement."
+ },
+ {
+ "role": "user",
+ "content": f"Please review this {language} code:\n\n```{language}\n{code}\n```"
+ }
+ ]
+```
+
+
+
+
+```javascript
+function codeReview(code, language) {
+ return [
+ {
+ role: 'system',
+ content: `You are a code reviewer examining ${language} code. Provide a detailed review highlighting best practices, potential issues, and suggestions for improvement.`
+ },
+ {
+ role: 'user',
+ content: `Please review this ${language} code:\n\n\`\`\`${language}\n${code}\n\`\`\``
+ }
+ ];
+}
+```
+
+
+
+
+## サンプリング
+
+サンプリングは、サーバーがクライアント(具体的にはホストアプリケーション)にLLMインタラクションの実行をリクエストすることを可能にします。
+
+- **制御**: サンプリングは**サーバー主導**ですが、クライアント/ホストの促進が必要です。
+- **目的**: サーバー主導のエージェンティックな行動と、潜在的な再帰的またはマルチステップインタラクションを可能にします。
+- **安全性**: ツールと同様に、サンプリング操作は通常ユーザー承認が必要です。
+- **ユースケース**: 複雑なマルチステップタスク、自律エージェントワークフロー、インタラクティブプロセス。
+
+**例**: サーバーがクライアントに処理したデータの分析をリクエストする場合:
+
+
+
+
+```python
+def request_sampling(messages, system_prompt=None, include_context="none"):
+ """Request LLM sampling from the client."""
+ # In a real implementation, this would send a request to the client
+ return {
+ "role": "assistant",
+ "content": "Analysis of the provided data..."
+ }
+```
+
+
+
+
+```javascript
+function requestSampling(messages, systemPrompt = null, includeContext = 'none') {
+ // In a real implementation, this would send a request to the client
+ return {
+ role: 'assistant',
+ content: 'Analysis of the provided data...'
+ };
+}
+
+function handleSamplingRequest(request) {
+ const { messages, systemPrompt, includeContext } = request;
+ // In a real implementation, this would process the request and return a response
+ return {
+ role: 'assistant',
+ content: 'Response to the sampling request...'
+ };
+}
+```
+
+
+
+
+サンプリングフローは以下のステップで進行します:
+1. サーバーがクライアントに`sampling/createMessage`リクエストを送信
+2. クライアントがリクエストをレビューし、変更することができる
+3. クライアントがLLMからサンプリングする
+4. クライアントが完了結果をレビューする
+5. クライアントが結果をサーバーに返す
+
+
+
+このヒューマン・イン・ザ・ループ設計により、ユーザーはLLMが何を見て何を生成するかを制御できます。サンプリングを実装する際は、明確で構造化されたプロンプトを提供し、関連するコンテキストを含めることが重要です。
+
+
+
+## 機能の連携
+
+これらの機能がどのように連携して複雑なインタラクションを可能にするかを見てみましょう。以下の表では、機能、それらを制御する者、制御の方向、その他の詳細を概説しています。
+
+| 機能 | 制御者 | 方向 | 副作用 | 承認が必要 | 一般的なユースケース |
+|------------|---------------|-----------|--------------|-----------------|-------------------|
+| ツール | モデル (LLM) | クライアント → サーバー | あり(潜在的に) | はい | アクション、API呼び出し、データ操作 |
+| リソース | アプリケーション | クライアント → サーバー | なし(読み取り専用) | 通常はいいえ | データ取得、コンテキスト収集 |
+| プロンプト | ユーザー | サーバー → クライアント | なし | いいえ(ユーザーが選択) | ガイド付きワークフロー、特化テンプレート |
+| サンプリング | サーバー | サーバー → クライアント → サーバー | 間接的に | はい | マルチステップタスク、エージェンティック行動 |
+
+これらの機能は相補的な方法で連携するように設計されています:
+
+1. ユーザーが**プロンプト**を選択して特化ワークフローを開始するかもしれません
+2. プロンプトに**リソース**からのコンテキストが含まれるかもしれません
+3. 処理中、AIモデルが**ツール**を呼び出して特定のアクションを実行するかもしれません
+4. 複雑な操作の場合、サーバーが**サンプリング**を使用して追加のLLM処理をリクエストするかもしれません
+
+これらのプリミティブ間の区別は、MCPインタラクションに明確な構造を提供し、適切な制御境界を維持しながらAIモデルが情報にアクセスし、アクションを実行し、複雑なワークフローに参加できるようにします。
+
+## 発見プロセス
+
+MCPの主要機能の一つは、動的機能発見です。クライアントがサーバーに接続すると、特定のリストメソッドを通じて利用可能なツール、リソース、プロンプトをクエリできます:
+
+- `tools/list`: 利用可能なツールを発見
+- `resources/list`: 利用可能なリソースを発見
+- `prompts/list`: 利用可能なプロンプトを発見
+
+この動的発見メカニズムにより、クライアントはサーバーの機能に関するハードコードされた知識を必要とせずに、各サーバーが提供する特定の機能に適応できます。
+
+## 結論
+
+これらのコアプリミティブを理解することは、MCPを効果的に使用するために不可欠です。明確な制御境界を持つ異なるタイプの機能を提供することで、MCPは適切な安全性と制御メカニズムを維持しながら、AIモデルと外部システム間の強力なインタラクションを可能にします。
+
+次のセクションでは、Gradioがこれらの機能に使いやすいインターフェースを提供するためにMCPとどのように統合されるかを探求していきます。
\ No newline at end of file
diff --git a/units/ja/unit1/certificate.mdx b/units/ja/unit1/certificate.mdx
new file mode 100644
index 0000000..f116595
--- /dev/null
+++ b/units/ja/unit1/certificate.mdx
@@ -0,0 +1,19 @@
+# 認定証を取得しましょう!
+
+よくできました!MCPコースの最初のユニットを完了しました。今度は認定証を取得するために試験を受ける時です。
+
+以下はユニットの理解を確認するためのクイズです。
+
+
+
+
+
+上記のクイズの使用に問題がある場合は、[Hugging Face Hub](https://huggingface.co/spaces/mcp-course/unit_1_quiz)でスペースに直接アクセスしてください。エラーを見つけた場合は、スペースの[Communityタブ](https://huggingface.co/spaces/mcp-course/unit_1_quiz/discussions)で報告できます。
+
+
+
diff --git a/units/ja/unit1/communication-protocol.mdx b/units/ja/unit1/communication-protocol.mdx
new file mode 100644
index 0000000..fe36d2e
--- /dev/null
+++ b/units/ja/unit1/communication-protocol.mdx
@@ -0,0 +1,223 @@
+# 通信プロトコル
+
+MCPは、クライアントとサーバーが一貫性があり予測可能な方法でメッセージを交換できるようにする標準化された通信プロトコルを定義しています。この標準化は、コミュニティ全体での相互運用性にとって重要です。このセクションでは、MCPで使用されるプロトコル構造と転送メカニズムを探求します。
+
+
+
+MCPプロトコルの詳細について説明していきます。MCPを使って構築するためにすべてを知る必要はありませんが、それが存在し、どのように機能するかを知っておくことは良いことです。
+
+
+
+## JSON-RPC: 基盤
+
+コアにおいて、MCPはクライアントとサーバー間のすべてのコミュニケーションのメッセージ形式として**JSON-RPC 2.0**を使用します。JSON-RPCは、JSONでエンコードされた軽量のリモートプロシージャー呼び出しプロトコルであり、以下の特徴を持ちます:
+
+- 人間が読みやすく、デバッグが容易
+- 言語非依存で、あらゆるプログラミング環境での実装をサポート
+- 確立された技術であり、明確な仕様と幅広い採用を持つ
+
+
+
+プロトコルは3種類のメッセージを定義します:
+
+### 1. リクエスト
+
+操作を開始するためにクライアントからサーバーに送信されます。リクエストメッセージには以下が含まれます:
+- 一意の識別子(`id`)
+- 呼び出すメソッド名(例:`tools/call`)
+- メソッドのパラメーター(ある場合)
+
+リクエストの例:
+
+```json
+{
+ "jsonrpc": "2.0",
+ "id": 1,
+ "method": "tools/call",
+ "params": {
+ "name": "weather",
+ "arguments": {
+ "location": "San Francisco"
+ }
+ }
+}
+```
+
+### 2. レスポンス
+
+リクエストに対する返信としてサーバーからクライアントに送信されます。レスポンスメッセージには以下が含まれます:
+- 対応するリクエストと同じ`id`
+- `result`(成功の場合)または`error`(失敗の場合)のいずれか
+
+成功レスポンスの例:
+```json
+{
+ "jsonrpc": "2.0",
+ "id": 1,
+ "result": {
+ "temperature": 62,
+ "conditions": "Partly cloudy"
+ }
+}
+```
+
+エラーレスポンスの例:
+```json
+{
+ "jsonrpc": "2.0",
+ "id": 1,
+ "error": {
+ "code": -32602,
+ "message": "Invalid location parameter"
+ }
+}
+```
+
+### 3. 通知
+
+レスポンスを必要としない一方向メッセージ。通常、イベントに関する更新や通知を提供するためにサーバーからクライアントに送信されます。
+
+通知の例:
+```json
+{
+ "jsonrpc": "2.0",
+ "method": "progress",
+ "params": {
+ "message": "Processing data...",
+ "percent": 50
+ }
+}
+```
+
+## 転送メカニズム
+
+JSON-RPCはメッセージ形式を定義しますが、MCPはこれらのメッセージがクライアントとサーバー間でどのように転送されるかも指定します。2つの主要な転送メカニズムがサポートされています:
+
+### stdio(標準入力/出力)
+
+stdio転送は、クライアントとサーバーが同じマシンで実行されるローカル通信に使用されます:
+
+ホストアプリケーションはサーバーをサブプロセスとして起動し、その標準入力(stdin)に書き込み、標準出力(stdout)から読み取ることでコミュニケーションを行います。
+
+
+
+この転送の**ユースケース**は、ファイルシステムアクセスやローカルスクリプトの実行のようなローカルツールです。
+
+
+
+この転送の主要な**利点**は、シンプルで、ネットワーク設定が不要で、オペレーティングシステムによって安全にサンドボックス化されることです。
+
+### HTTP + SSE(Server-Sent Events)/ Streamable HTTP
+
+HTTP+SSE転送は、クライアントとサーバーが異なるマシンにある可能性があるリモート通信に使用されます:
+
+コミュニケーションはHTTPで行われ、サーバーはServer-Sent Events(SSE)を使用して永続接続でクライアントに更新をプッシュします。
+
+
+
+この転送の**ユースケース**は、リモートAPI、クラウドサービス、または共有リソースへの接続です。
+
+
+
+この転送の主要な**利点**は、ネットワークで機能し、Webサービスとの統合を可能にし、サーバーレス環境と互換性があることです。
+
+MCP標準の最近の更新では、「Streamable HTTP」が導入または改善され、サーバーレス環境との互換性を維持しながら、必要に応じてサーバーがストリーミング用にSSEに動的にアップグレードできるようにすることで、より柔軟性を提供します。
+
+## インタラクションライフサイクル
+
+前のセクションでは、クライアント(💻)とサーバー(🌐)間の単一インタラクションのライフサイクルについて議論しました。今度は、MCPプロトコルのコンテキストでクライアントとサーバー間の完全なインタラクションのライフサイクルを見てみましょう。
+
+MCPプロトコルは、クライアントとサーバー間の構造化されたインタラクションライフサイクルを定義します:
+
+### 初期化
+
+クライアントがサーバーに接続し、プロトコルバージョンと機能を交換し、サーバーはサポートするプロトコルバージョンと機能で応答します。
+
+
+
+## 内容
+
+このコースは4つのユニットに分かれています。**Model Context Protocolの基礎からAIアプリケーションでMCPを実装する最終プロジェクト**まで学習できます。
+
+こちらから登録してください(無料です)👉 [近日公開]
+
+コースはこちらからアクセスできます 👉 [近日公開]
+
+| ユニット | トピック | 説明 |
+| ------- | --------------------------------------------------- | ------------------------------------------------------------------------------------------------------- |
+| 0 | コースへようこそ | ウェルカム、ガイドライン、必要なツール、コース概要 |
+| 1 | Model Context Protocolの紹介 | MCPの定義、主要概念、AIモデルと外部データ・ツールを接続する役割 |
+| 2 | MCPを使った構築:実践的開発 | 利用可能なSDKとフレームワークを使用してMCPクライアントとサーバーの実装を学習 |
+| 3 | MCPプロトコル詳細解説 | 高度なMCP機能、アーキテクチャ、実世界での統合パターンを探索 |
+| 4 | ボーナスユニット & コラボレーション | 特別なトピック、パートナーライブラリ、コミュニティ主導のプロジェクト |
+
+## 前提条件
+
+* AIとLLM概念の基本的理解
+* ソフトウェア開発原則とAPI概念に精通していること
+* 少なくとも1つのプログラミング言語の経験(PythonまたはTypeScriptの例を重視します)
+
+## 貢献ガイドライン
+
+このコースに貢献したい場合は、歓迎いたします。お気軽にissueを作成するか、プルリクエストを提出してください。具体的な貢献については、以下のガイドラインをご参照ください:
+
+### 小さなタイポや文法の修正
+
+小さなタイポや文法の間違いを見つけた場合は、ご自身で修正してプルリクエストを提出してください。これは学習者にとって非常に有用です。
+
+### 新しいユニット
+
+新しいユニットを追加したい場合は、**リポジトリにissueを作成し、そのユニットについて説明し、なぜ追加すべきかを記述してください**。議論を行い、良い追加であれば協力して作業することができます。
+
+## プロジェクトの引用
+
+出版物でこのリポジトリを引用する場合:
+
+```
+@misc{mcp-course,
+ author = {Burtenshaw, Ben and Notov, Alex},
+ title = {The Model Context Protocol Course},
+ year = {2025},
+ howpublished = {\url{https://github.com/huggingface/mcp-course}},
+ note = {GitHub repository},
+}
+```
\ No newline at end of file
diff --git a/units/ja/_toctree.yml b/units/ja/_toctree.yml
new file mode 100644
index 0000000..a863654
--- /dev/null
+++ b/units/ja/_toctree.yml
@@ -0,0 +1,82 @@
+- title: "0. MCPコースへようこそ"
+ sections:
+ - local: unit0/introduction
+ title: MCPコースへようこそ
+
+- title: "1. Model Context Protocolの紹介"
+ sections:
+ - local: unit1/introduction
+ title: Model Context Protocol (MCP)の紹介
+ - local: unit1/key-concepts
+ title: 主要概念と用語
+ - local: unit1/architectural-components
+ title: アーキテクチャコンポーネント
+ - local: unit1/quiz1
+ title: クイズ1 - MCP基礎
+ - local: unit1/communication-protocol
+ title: 通信プロトコル
+ - local: unit1/capabilities
+ title: MCP機能の理解
+ - local: unit1/sdk
+ title: MCP SDK
+ - local: unit1/quiz2
+ title: クイズ2 - MCP SDK
+ - local: unit1/mcp-clients
+ title: MCPクライアント
+ - local: unit1/gradio-mcp
+ title: Gradio MCP統合
+ - local: unit1/unit1-recap
+ title: ユニット1まとめ
+ - local: unit1/certificate
+ title: 証明書を取得しよう!
+
+- title: "2. ユースケース: エンドツーエンドMCPアプリケーション"
+ sections:
+ - local: unit2/introduction
+ title: MCPアプリケーション構築の紹介
+ - local: unit2/gradio-server
+ title: Gradio MCPサーバーの構築
+ - local: unit2/clients
+ title: アプリケーションでのMCPクライアントの使用
+ - local: unit2/continue-client
+ title: AIコーディングアシスタントでのMCPの使用
+ - local: unit2/gradio-client
+ title: GradioでのMCPクライアント構築
+ - local: unit2/tiny-agents
+ title: MCPとHugging Face Hubを使ったTiny Agentsの構築
+
+- title: "3. 高度なMCP開発: カスタムワークフローサーバー"
+ sections:
+ - local: unit3/introduction
+ title: Claude Code用カスタムワークフローサーバーの構築
+ - local: unit3/build-mcp-server
+ title: "モジュール1: MCPサーバーの構築"
+ - local: unit3/github-actions-integration
+ title: "モジュール2: GitHub Actions統合"
+ - local: unit3/slack-notification
+ title: "モジュール3: Slack通知"
+ - local: unit3/build-mcp-server-solution-walkthrough
+ title: "ユニット3解答例: MCPを使ったプルリクエストエージェントの構築"
+ - local: unit3/certificate
+ title: "証明書を取得しよう!"
+ - local: unit3/conclusion
+ title: "ユニット3まとめ"
+
+- title: "3.1. ユースケース: Hub上でのプルリクエストエージェントの構築"
+ sections:
+ - local: unit3_1/introduction
+ title: Hugging Face Hub上でのプルリクエストエージェントの構築
+ - local: unit3_1/setting-up-the-project
+ title: プロジェクトのセットアップ
+ - local: unit3_1/creating-the-mcp-server
+ title: MCPサーバーの作成
+ - local: unit3_1/quiz1
+ title: クイズ1 - MCPサーバー実装
+ - local: unit3_1/mcp-client
+ title: MCPクライアント
+ - local: unit3_1/webhook-listener
+ title: Webhookリスナー
+ - local: unit3_1/quiz2
+ title: クイズ2 - プルリクエストエージェント統合
+ - local: unit3_1/conclusion
+ title: まとめ
diff --git a/units/ja/unit0/introduction.mdx b/units/ja/unit0/introduction.mdx
new file mode 100644
index 0000000..a2cbc19
--- /dev/null
+++ b/units/ja/unit0/introduction.mdx
@@ -0,0 +1,144 @@
+# 🤗 Model Context Protocol (MCP) コースへようこそ
+
+
+
+今日のAIにおいて最も注目すべきトピック、**Model Context Protocol (MCP)**へようこそ!
+
+この無料コースは[Anthropic](https://www.anthropic.com)とのパートナーシップで構築され、MCPの理解、使用、アプリケーション構築について、**初心者から熟練者まで**の旅路にお連れします。
+
+この最初のユニットでは、オンボーディングをお手伝いします:
+
+* **コースのシラバス**を発見する。
+* **認定プロセスとスケジュールに関する詳細情報**を取得する。
+* コース制作チームを知る。
+* **アカウント**を作成する。
+* **Discordサーバーにサインアップ**し、クラスメートや私たちと出会う。
+
+始めましょう!
+
+## このコースに何を期待できますか?
+
+このコースでは、以下のことを行います:
+
+* 📖 Model Context Protocolを**理論、設計、実践**で学習する。
+* 🧑💻 **確立されたMCP SDKとフレームワークの使用方法**を学ぶ。
+* 💾 **プロジェクトを共有**し、コミュニティが作成したアプリケーションを探索する。
+* 🏆 **他の学生のMCP実装と自分の実装を評価**するチャレンジに参加する。
+* 🎓 課題を完了することで**修了証書を取得**する。
+
+その他にも多くのことがあります!
+
+このコースの最後には、**MCPがどのように動作し、最新のMCP標準を使用して外部データやツールを活用する独自のAIアプリケーションを構築する方法**を理解できるようになります。
+
+[**コースにサインアップ**](https://huggingface.co/mcp-course)することをお忘れなく!
+
+## コースはどのような構成ですか?
+
+コースは以下で構成されています:
+
+* _基礎ユニット_: MCPの**概念を理論で**学ぶ部分。
+* _ハンズオン_: **確立されたMCP SDK**を使用してアプリケーションを構築することを学ぶ部分。これらのハンズオンセクションには事前設定された環境があります。
+* _ユースケース課題_: 学習した概念を適用して、あなたが選択する実世界の問題を解決する部分。
+* _コラボレーション_: Hugging Faceのパートナーと協力して、最新のMCP実装とツールを提供します。
+
+この**コースは生きているプロジェクトであり、あなたのフィードバックと貢献によって進化しています!** GitHubでのissueやPRの開設、Discordサーバーでの議論への参加をお気軽にどうぞ。
+
+## シラバスは何ですか?
+
+以下が**コースの一般的なシラバス**です。各ユニットのリリース時により詳細なトピックリストが公開されます。
+
+| チャプター | トピック | 説明 |
+| ------- | ------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------- |
+| 0 | オンボーディング | 使用するツールとプラットフォームをセットアップする。 |
+| 1 | MCP基礎、アーキテクチャ、コア概念 | Model Context Protocolのコア概念、アーキテクチャ、コンポーネントを説明する。MCPを使用したシンプルなユースケースを示す。 |
+| 2 | エンドツーエンドユースケース: MCP in Action | コミュニティと共有できるシンプルなエンドツーエンドMCPアプリケーションを構築する。 |
+| 3 | デプロイされたユースケース: MCP in Action | Hugging Faceエコシステムとパートナーのサービスを使用してデプロイされたMCPアプリケーションを構築する。 |
+| 4 | ボーナスユニット | パートナーのライブラリとサービスを使用して、コースからより多くを得るためのボーナスユニット。 |
+
+## 前提条件は何ですか?
+
+このコースを受講するためには、以下が必要です:
+
+* AIとLLM概念の基本的な理解
+* ソフトウェア開発原則とAPI概念の熟知
+* 少なくとも一つのプログラミング言語の経験(PythonまたはTypeScriptの例が表示されます)
+
+これらのいずれかを持っていなくても心配しないでください!以下のリソースが役立ちます:
+
+* [LLMコース](https://huggingface.co/learn/llm-course/)では、LLMの使用と構築の基礎をガイドします。
+* [エージェントコース](https://huggingface.co/learn/agents-course/)では、LLMを使用したAIエージェントの構築をガイドします。
+
+
+
+上記のコースは前提条件ではありませんので、LLMとエージェントの概念を理解していれば、今すぐコースを開始できます!
+
+
+
+## どのようなツールが必要ですか?
+
+必要なものは2つだけです:
+
+* インターネット接続のある_コンピューター_。
+* _アカウント_: コースリソースにアクセスし、プロジェクトを作成するため。まだアカウントをお持ちでない場合は、[こちら](https://huggingface.co/join)で作成できます(無料です)。
+
+## 認定プロセス
+
+このコースを_聴講モード_で受講することも、活動を行って_私たちが発行する2つの証明書のいずれかを取得_することもできます。コースを聴講する場合、すべてのチャレンジに参加し、希望すれば課題を行うことができ、**私たちに通知する必要はありません**。
+
+認定プロセスは**完全に無料**です:
+
+* _基礎の認定を取得する_: コースのユニット1を完了する必要があります。これは、完全なアプリケーションを構築する必要なく、MCPの最新トレンドを把握したい学生を対象としています。
+* _修了証書を取得する_: ユースケースユニット(2と3)を完了する必要があります。これは、完全なアプリケーションを構築してコミュニティと共有したい学生を対象としています。
+
+## 推奨ペースは何ですか?
+
+このコースの各チャプターは**1週間で完了するように設計されており、週に約3-4時間の作業時間**です。
+
+期限があるため、推奨ペースを提供します:
+
+
+
+## コースを最大限活用するには?
+
+コースを最大限活用するために、以下のアドバイスがあります:
+
+1. [Discordで学習グループに参加](https://discord.gg/UrrTSsSyjb): グループで学習することは常により簡単です。そのためには、私たちのdiscordサーバーに参加し、アカウントを認証する必要があります。
+2. **クイズと課題を行う**: 学習の最良の方法は実践的な練習と自己評価です。
+3. **同期を保つためのスケジュールを定義**: 以下の推奨ペーススケジュールを使用するか、独自のものを作成できます。
+
+
+
+## 私たちについて
+
+著者について:
+
+### Ben Burtenshaw
+
+BenはHugging FaceのMachine Learning Engineerで、ポストトレーニングとエージェンティックアプローチを使用したLLMアプリケーションの構築に焦点を当てています。[HubでBenをフォロー](https://huggingface.co/burtenshaw)して、彼の最新プロジェクトを見てください。
+
+### Alex Notov
+
+Alexは[Anthropic](https://www.anthropic.com)のTechnical Partner Enablement Leadで、このコースのユニット3に取り組みました。AlexはAnthropicのパートナーに対して、それぞれのユースケースでのClaudeのベストプラクティスをトレーニングしています。Alexを[LinkedIn](https://linkedin.com/in/zealoushacker)と[GitHub](https://github.com/zealoushacker)でフォローしてください。
+
+## 謝辞
+
+貴重な貢献とサポートをいただいた以下の個人とパートナーに感謝いたします:
+
+- [Gradio](https://www.gradio.app/)
+- [Continue](https://continue.dev)
+- [Llama.cpp](https://github.com/ggerganov/llama.cpp)
+- [Anthropic](https://www.anthropic.com)
+
+## バグを見つけた、またはコースを改善したい
+
+貢献は**歓迎**です 🤗
+
+* _ノートブックでバグ🐛を見つけた_場合は、[issueを開いて](https://github.com/huggingface/mcp-course/issues/new)**問題を説明**してください。
+* _コースを改善したい_場合は、[Pull Requestを開く](https://github.com/huggingface/mcp-course/pulls)ことができます。
+* _完全なセクションや新しいユニットを追加したい_場合は、[issueを開いて](https://github.com/huggingface/mcp-course/issues/new)**書き始める前に追加したいコンテンツを説明**し、私たちがガイドできるようにすることが最善です。
+
+## まだ質問があります
+
+discordサーバーの#mcp-course-questionsで質問してください。
+
+すべての情報を得たので、さあ始めましょう ⛵
diff --git a/units/ja/unit1/architectural-components.mdx b/units/ja/unit1/architectural-components.mdx
new file mode 100644
index 0000000..4b084c2
--- /dev/null
+++ b/units/ja/unit1/architectural-components.mdx
@@ -0,0 +1,85 @@
+# MCPのアーキテクチャコンポーネント
+
+前のセクションでは、MCPの主要概念と用語について説明しました。今度は、MCPエコシステムを構成するアーキテクチャコンポーネントについてより深く掘り下げてみましょう。
+
+## ホスト、クライアント、サーバー
+
+Model Context Protocol(MCP)は、AIモデルと外部システム間の構造化された通信を可能にするクライアント・サーバー・アーキテクチャ上に構築されています。
+
+
+
+MCPアーキテクチャは、それぞれ明確に定義された役割と責任を持つ3つの主要コンポーネントで構成されています:ホスト、クライアント、サーバー。前のセクションでこれらについて触れましたが、各コンポーネントとその責任についてより深く掘り下げてみましょう。
+
+### ホスト
+
+**ホスト**は、エンドユーザーが直接インタラクトするユーザー向けAIアプリケーションです。
+
+例として以下があります:
+- OpenAI ChatGPTやAnthropicのClaude DesktopのようなAIチャットアプリ
+- CursorのようなAI強化IDE、またはContinue.devのようなツールとの統合
+- LangChainやsmolagentsのようなライブラリで構築されたカスタムAIエージェントやアプリケーション
+
+ホストの責任には以下が含まれます:
+- ユーザーインタラクションと許可の管理
+- MCPクライアントを介したMCPサーバーへの接続開始
+- ユーザーリクエスト、LLM処理、外部ツール間の全体的なフローの統率
+- 結果を一貫した形式でユーザーに渡すレンダリング
+
+ほとんどの場合、ユーザーはニーズと好みに基づいてホストアプリケーションを選択します。たとえば、開発者は強力なコード編集機能を求めてCursorを選択するかもしれませんし、ドメインエキスパートはsmolagentsで構築されたカスタムアプリケーションを使用するかもしれません。
+
+### クライアント
+
+**クライアント**は、特定のMCPサーバーとのコミュニケーションを管理するホストアプリケーション内のコンポーネントです。主要な特徴には以下が含まれます:
+
+- 各クライアントは単一のサーバーとの1:1接続を維持します
+- MCPコミュニケーションのプロトコルレベルの詳細を処理します
+- ホストのロジックと外部サーバー間の中介役として機能します
+
+### サーバー
+
+**サーバー**は、MCPプロトコルを介してAIモデルに機能を公開する外部プログラムまたはサービスです。サーバーは:
+
+- 特定の外部ツール、データソース、またはサービスへのアクセスを提供します
+- 既存の機能の周りの軽量なラッパーとして機能します
+- ローカル(ホストと同じマシン上)またはリモート(ネットワーク経由)で実行できます
+- クライアントが発見し、使用できる標準化された形式で機能を公開します
+
+## コミュニケーションフロー
+
+一般的なMCPワークフローでこれらのコンポーネントがどのようにインタラクトするかを検討してみましょう:
+
+
+
+次のセクションでは、これらのコンポーネントを実用的な例で可能にするコミュニケーションプロトコルについてより深く掘り下げていきます。
+
+
+
+1. **ユーザーインタラクション**: ユーザーが**ホスト**アプリケーションとインタラクトし、意図やクエリを表現します。
+
+2. **ホスト処理**: **ホスト**がユーザーの入力を処理し、リクエストを理解し、どの外部機能が必要になる可能性があるかを決定するためにLLMを使用する可能性があります。
+
+3. **クライアント接続**: **ホスト**がその**クライアント**コンポーネントに適切なサーバーに接続するよう指示します。
+
+4. **機能発見**: **クライアント**が**サーバー**にクエリを送って、どのような機能(ツール、リソース、プロンプト)を提供しているかを発見します。
+
+5. **機能呼び出し**: ユーザーのニーズやLLMの判断に基づいて、ホストが**クライアント**に**サーバー**から特定の機能を呼び出すよう指示します。
+
+6. **サーバー実行**: **サーバー**がリクエストされた機能を実行し、結果を**クライアント**に返します。
+
+7. **結果統合**: **クライアント**がこれらの結果を**ホスト**に中継し、ホストはそれらをLLMのコンテキストに組み込むか、直接ユーザーに提示します。
+
+このアーキテクチャの主要な利点は、そのモジュラー性です。単一の**ホスト**が異なる**クライアント**を介して複数の**サーバー**に同時に接続できます。新しい**サーバー**を既存の**ホスト**の変更を必要とせずにエコシステムに追加できます。機能を異なる**サーバー**間で簡単に組み合わせることができます。
+
+
+
+前のセクションで議論したように、このモジュラー性は、伝統的なM×N統合問題(M個のAIアプリケーションがN個のツール/サービスに接続)を、各ホストとサーバーがMCP標準を一度だけ実装するより管理しやすいM+N問題に変換します。
+
+
+
+アーキテクチャはシンプルに見えるかもしれませんが、その力はコミュニケーションプロトコルの標準化とコンポーネント間の責任の明確な分離にあります。この設計により、AIモデルが常に成長し続ける外部ツールやデータソースの配列とシームレスに接続できる結束力のあるエコシステムが可能になります。
+
+## 結論
+
+これらのインタラクションパターンは、MCPの設計と進化を形作るいくつかの主要原則によってガイドされています。プロトコルはAI接続のための普遍的プロトコルを提供することで**標準化**を強調し、コアプロトコルを直接的に保ちながら高度な機能を可能にすることで**シンプルさ**を維持します。機密な操作に対して明示的なユーザー承認を要求することで**安全性**が優先され、発見性は機能の動的発見を可能にします。プロトコルは**拡張性**を念頭に置いて構築され、バージョニングと機能交渉を通じて進化をサポートし、異なる実装と環境間での**相互運用性**を保証します。
+
+次のセクションでは、これらのコンポーネントが効果的に連携できるようにするコミュニケーションプロトコルを探求していきます。
\ No newline at end of file
diff --git a/units/ja/unit1/capabilities.mdx b/units/ja/unit1/capabilities.mdx
new file mode 100644
index 0000000..29f8cb4
--- /dev/null
+++ b/units/ja/unit1/capabilities.mdx
@@ -0,0 +1,243 @@
+# MCP機能の理解
+
+MCPサーバーは、通信プロトコルを通じてクライアントに様々な機能を公開します。これらの機能は4つの主要カテゴリーに分類され、それぞれが異なる特性とユースケースを持ちます。MCPの機能の基盤を形成するこれらのコアプリミティブを探求してみましょう。
+
+
+
+このセクションでは、各言語でフレームワーク非依存の関数として例を示します。これは、フレームワークの複雑さではなく、概念とそれらがどのように連携するかに焦点を当てるためです。
+
+今後のユニットでは、これらの概念がMCP固有のコードでどのように実装されるかを示します。
+
+
+
+## ツール
+
+ツールは、AIモデルがMCPプロトコルを通じて呼び出すことができる実行可能な関数またはアクションです。
+
+- **制御**: ツールは通常**モデル制御**であり、AIモデル(LLM)がユーザーのリクエストとコンテキストに基づいていつ呼び出すかを決定します。
+- **安全性**: 副作用を伴うアクションを実行する能力があるため、ツールの実行は危険な場合があります。そのため、通常、明示的なユーザー承認が必要です。
+- **ユースケース**: メッセージの送信、チケットの作成、APIのクエリ、計算の実行。
+
+**例**: 指定した場所の現在の天気データを取得する天気ツール:
+
+
+
+
+```python
+def get_weather(location: str) -> dict:
+ """Get the current weather for a specified location."""
+ # Connect to weather API and fetch data
+ return {
+ "temperature": 72,
+ "conditions": "Sunny",
+ "humidity": 45
+ }
+```
+
+
+
+
+```javascript
+function getWeather(location) {
+ // Connect to weather API and fetch data
+ return {
+ temperature: 72,
+ conditions: 'Sunny',
+ humidity: 45
+ };
+}
+```
+
+
+
+
+## リソース
+
+リソースはデータソースへの読み取り専用アクセスを提供し、AIモデルが複雑なロジックを実行することなくコンテキストを取得できるようにします。
+
+- **制御**: リソースは**アプリケーション制御**であり、ホストアプリケーションが通常、いつアクセスするかを決定します。
+- **性質**: REST APIのGETエンドポイントと同様に、最小限の計算でデータ取得用に設計されています。
+- **安全性**: 読み取り専用であるため、通常ツールよりもセキュリティリスクが低くなります。
+- **ユースケース**: ファイルコンテンツのアクセス、データベースレコードの取得、設定情報の読み取り。
+
+**例**: ファイルコンテンツへのアクセスを提供するリソース:
+
+
+
+
+```python
+def read_file(file_path: str) -> str:
+ """Read the contents of a file at the specified path."""
+ with open(file_path, 'r') as f:
+ return f.read()
+```
+
+
+
+
+```javascript
+function readFile(filePath) {
+ // Using fs.readFile to read file contents
+ const fs = require('fs');
+ return new Promise((resolve, reject) => {
+ fs.readFile(filePath, 'utf8', (err, data) => {
+ if (err) {
+ reject(err);
+ return;
+ }
+ resolve(data);
+ });
+ });
+}
+```
+
+
+
+
+## プロンプト
+
+プロンプトは、ユーザー、AIモデル、サーバーの機能間のインタラクションをガイドする事前定義されたテンプレートまたはワークフローです。
+
+- **制御**: プロンプトは**ユーザー制御**であり、しばしばホストアプリケーションのUIでオプションとして提示されます。
+- **目的**: 利用可能なツールとリソースの最適な使用のためにインタラクションを構造化します。
+- **選択**: ユーザーは通常、AIモデルが処理を開始する前にプロンプトを選択し、インタラクションのコンテキストを設定します。
+- **ユースケース**: 一般的なワークフロー、特化タスクテンプレート、ガイド付きインタラクション。
+
+**例**: コードレビューを生成するためのプロンプトテンプレート:
+
+
+
+
+```python
+def code_review(code: str, language: str) -> list:
+ """Generate a code review for the provided code snippet."""
+ return [
+ {
+ "role": "system",
+ "content": f"You are a code reviewer examining {language} code. Provide a detailed review highlighting best practices, potential issues, and suggestions for improvement."
+ },
+ {
+ "role": "user",
+ "content": f"Please review this {language} code:\n\n```{language}\n{code}\n```"
+ }
+ ]
+```
+
+
+
+
+```javascript
+function codeReview(code, language) {
+ return [
+ {
+ role: 'system',
+ content: `You are a code reviewer examining ${language} code. Provide a detailed review highlighting best practices, potential issues, and suggestions for improvement.`
+ },
+ {
+ role: 'user',
+ content: `Please review this ${language} code:\n\n\`\`\`${language}\n${code}\n\`\`\``
+ }
+ ];
+}
+```
+
+
+
+
+## サンプリング
+
+サンプリングは、サーバーがクライアント(具体的にはホストアプリケーション)にLLMインタラクションの実行をリクエストすることを可能にします。
+
+- **制御**: サンプリングは**サーバー主導**ですが、クライアント/ホストの促進が必要です。
+- **目的**: サーバー主導のエージェンティックな行動と、潜在的な再帰的またはマルチステップインタラクションを可能にします。
+- **安全性**: ツールと同様に、サンプリング操作は通常ユーザー承認が必要です。
+- **ユースケース**: 複雑なマルチステップタスク、自律エージェントワークフロー、インタラクティブプロセス。
+
+**例**: サーバーがクライアントに処理したデータの分析をリクエストする場合:
+
+
+
+
+```python
+def request_sampling(messages, system_prompt=None, include_context="none"):
+ """Request LLM sampling from the client."""
+ # In a real implementation, this would send a request to the client
+ return {
+ "role": "assistant",
+ "content": "Analysis of the provided data..."
+ }
+```
+
+
+
+
+```javascript
+function requestSampling(messages, systemPrompt = null, includeContext = 'none') {
+ // In a real implementation, this would send a request to the client
+ return {
+ role: 'assistant',
+ content: 'Analysis of the provided data...'
+ };
+}
+
+function handleSamplingRequest(request) {
+ const { messages, systemPrompt, includeContext } = request;
+ // In a real implementation, this would process the request and return a response
+ return {
+ role: 'assistant',
+ content: 'Response to the sampling request...'
+ };
+}
+```
+
+
+
+
+サンプリングフローは以下のステップで進行します:
+1. サーバーがクライアントに`sampling/createMessage`リクエストを送信
+2. クライアントがリクエストをレビューし、変更することができる
+3. クライアントがLLMからサンプリングする
+4. クライアントが完了結果をレビューする
+5. クライアントが結果をサーバーに返す
+
+
+
+このヒューマン・イン・ザ・ループ設計により、ユーザーはLLMが何を見て何を生成するかを制御できます。サンプリングを実装する際は、明確で構造化されたプロンプトを提供し、関連するコンテキストを含めることが重要です。
+
+
+
+## 機能の連携
+
+これらの機能がどのように連携して複雑なインタラクションを可能にするかを見てみましょう。以下の表では、機能、それらを制御する者、制御の方向、その他の詳細を概説しています。
+
+| 機能 | 制御者 | 方向 | 副作用 | 承認が必要 | 一般的なユースケース |
+|------------|---------------|-----------|--------------|-----------------|-------------------|
+| ツール | モデル (LLM) | クライアント → サーバー | あり(潜在的に) | はい | アクション、API呼び出し、データ操作 |
+| リソース | アプリケーション | クライアント → サーバー | なし(読み取り専用) | 通常はいいえ | データ取得、コンテキスト収集 |
+| プロンプト | ユーザー | サーバー → クライアント | なし | いいえ(ユーザーが選択) | ガイド付きワークフロー、特化テンプレート |
+| サンプリング | サーバー | サーバー → クライアント → サーバー | 間接的に | はい | マルチステップタスク、エージェンティック行動 |
+
+これらの機能は相補的な方法で連携するように設計されています:
+
+1. ユーザーが**プロンプト**を選択して特化ワークフローを開始するかもしれません
+2. プロンプトに**リソース**からのコンテキストが含まれるかもしれません
+3. 処理中、AIモデルが**ツール**を呼び出して特定のアクションを実行するかもしれません
+4. 複雑な操作の場合、サーバーが**サンプリング**を使用して追加のLLM処理をリクエストするかもしれません
+
+これらのプリミティブ間の区別は、MCPインタラクションに明確な構造を提供し、適切な制御境界を維持しながらAIモデルが情報にアクセスし、アクションを実行し、複雑なワークフローに参加できるようにします。
+
+## 発見プロセス
+
+MCPの主要機能の一つは、動的機能発見です。クライアントがサーバーに接続すると、特定のリストメソッドを通じて利用可能なツール、リソース、プロンプトをクエリできます:
+
+- `tools/list`: 利用可能なツールを発見
+- `resources/list`: 利用可能なリソースを発見
+- `prompts/list`: 利用可能なプロンプトを発見
+
+この動的発見メカニズムにより、クライアントはサーバーの機能に関するハードコードされた知識を必要とせずに、各サーバーが提供する特定の機能に適応できます。
+
+## 結論
+
+これらのコアプリミティブを理解することは、MCPを効果的に使用するために不可欠です。明確な制御境界を持つ異なるタイプの機能を提供することで、MCPは適切な安全性と制御メカニズムを維持しながら、AIモデルと外部システム間の強力なインタラクションを可能にします。
+
+次のセクションでは、Gradioがこれらの機能に使いやすいインターフェースを提供するためにMCPとどのように統合されるかを探求していきます。
\ No newline at end of file
diff --git a/units/ja/unit1/certificate.mdx b/units/ja/unit1/certificate.mdx
new file mode 100644
index 0000000..f116595
--- /dev/null
+++ b/units/ja/unit1/certificate.mdx
@@ -0,0 +1,19 @@
+# 認定証を取得しましょう!
+
+よくできました!MCPコースの最初のユニットを完了しました。今度は認定証を取得するために試験を受ける時です。
+
+以下はユニットの理解を確認するためのクイズです。
+
+
+
+
+
+上記のクイズの使用に問題がある場合は、[Hugging Face Hub](https://huggingface.co/spaces/mcp-course/unit_1_quiz)でスペースに直接アクセスしてください。エラーを見つけた場合は、スペースの[Communityタブ](https://huggingface.co/spaces/mcp-course/unit_1_quiz/discussions)で報告できます。
+
+
+
diff --git a/units/ja/unit1/communication-protocol.mdx b/units/ja/unit1/communication-protocol.mdx
new file mode 100644
index 0000000..fe36d2e
--- /dev/null
+++ b/units/ja/unit1/communication-protocol.mdx
@@ -0,0 +1,223 @@
+# 通信プロトコル
+
+MCPは、クライアントとサーバーが一貫性があり予測可能な方法でメッセージを交換できるようにする標準化された通信プロトコルを定義しています。この標準化は、コミュニティ全体での相互運用性にとって重要です。このセクションでは、MCPで使用されるプロトコル構造と転送メカニズムを探求します。
+
+
+
+MCPプロトコルの詳細について説明していきます。MCPを使って構築するためにすべてを知る必要はありませんが、それが存在し、どのように機能するかを知っておくことは良いことです。
+
+
+
+## JSON-RPC: 基盤
+
+コアにおいて、MCPはクライアントとサーバー間のすべてのコミュニケーションのメッセージ形式として**JSON-RPC 2.0**を使用します。JSON-RPCは、JSONでエンコードされた軽量のリモートプロシージャー呼び出しプロトコルであり、以下の特徴を持ちます:
+
+- 人間が読みやすく、デバッグが容易
+- 言語非依存で、あらゆるプログラミング環境での実装をサポート
+- 確立された技術であり、明確な仕様と幅広い採用を持つ
+
+
+
+プロトコルは3種類のメッセージを定義します:
+
+### 1. リクエスト
+
+操作を開始するためにクライアントからサーバーに送信されます。リクエストメッセージには以下が含まれます:
+- 一意の識別子(`id`)
+- 呼び出すメソッド名(例:`tools/call`)
+- メソッドのパラメーター(ある場合)
+
+リクエストの例:
+
+```json
+{
+ "jsonrpc": "2.0",
+ "id": 1,
+ "method": "tools/call",
+ "params": {
+ "name": "weather",
+ "arguments": {
+ "location": "San Francisco"
+ }
+ }
+}
+```
+
+### 2. レスポンス
+
+リクエストに対する返信としてサーバーからクライアントに送信されます。レスポンスメッセージには以下が含まれます:
+- 対応するリクエストと同じ`id`
+- `result`(成功の場合)または`error`(失敗の場合)のいずれか
+
+成功レスポンスの例:
+```json
+{
+ "jsonrpc": "2.0",
+ "id": 1,
+ "result": {
+ "temperature": 62,
+ "conditions": "Partly cloudy"
+ }
+}
+```
+
+エラーレスポンスの例:
+```json
+{
+ "jsonrpc": "2.0",
+ "id": 1,
+ "error": {
+ "code": -32602,
+ "message": "Invalid location parameter"
+ }
+}
+```
+
+### 3. 通知
+
+レスポンスを必要としない一方向メッセージ。通常、イベントに関する更新や通知を提供するためにサーバーからクライアントに送信されます。
+
+通知の例:
+```json
+{
+ "jsonrpc": "2.0",
+ "method": "progress",
+ "params": {
+ "message": "Processing data...",
+ "percent": 50
+ }
+}
+```
+
+## 転送メカニズム
+
+JSON-RPCはメッセージ形式を定義しますが、MCPはこれらのメッセージがクライアントとサーバー間でどのように転送されるかも指定します。2つの主要な転送メカニズムがサポートされています:
+
+### stdio(標準入力/出力)
+
+stdio転送は、クライアントとサーバーが同じマシンで実行されるローカル通信に使用されます:
+
+ホストアプリケーションはサーバーをサブプロセスとして起動し、その標準入力(stdin)に書き込み、標準出力(stdout)から読み取ることでコミュニケーションを行います。
+
+
+
+この転送の**ユースケース**は、ファイルシステムアクセスやローカルスクリプトの実行のようなローカルツールです。
+
+
+
+この転送の主要な**利点**は、シンプルで、ネットワーク設定が不要で、オペレーティングシステムによって安全にサンドボックス化されることです。
+
+### HTTP + SSE(Server-Sent Events)/ Streamable HTTP
+
+HTTP+SSE転送は、クライアントとサーバーが異なるマシンにある可能性があるリモート通信に使用されます:
+
+コミュニケーションはHTTPで行われ、サーバーはServer-Sent Events(SSE)を使用して永続接続でクライアントに更新をプッシュします。
+
+
+
+この転送の**ユースケース**は、リモートAPI、クラウドサービス、または共有リソースへの接続です。
+
+
+
+この転送の主要な**利点**は、ネットワークで機能し、Webサービスとの統合を可能にし、サーバーレス環境と互換性があることです。
+
+MCP標準の最近の更新では、「Streamable HTTP」が導入または改善され、サーバーレス環境との互換性を維持しながら、必要に応じてサーバーがストリーミング用にSSEに動的にアップグレードできるようにすることで、より柔軟性を提供します。
+
+## インタラクションライフサイクル
+
+前のセクションでは、クライアント(💻)とサーバー(🌐)間の単一インタラクションのライフサイクルについて議論しました。今度は、MCPプロトコルのコンテキストでクライアントとサーバー間の完全なインタラクションのライフサイクルを見てみましょう。
+
+MCPプロトコルは、クライアントとサーバー間の構造化されたインタラクションライフサイクルを定義します:
+
+### 初期化
+
+クライアントがサーバーに接続し、プロトコルバージョンと機能を交換し、サーバーはサポートするプロトコルバージョンと機能で応答します。
+
+
+
+ | 💻 |
+ →
initialize |
+ 🌐 |
+
+
+ | 💻 |
+ ←
response |
+ 🌐 |
+
+
+ | 💻 |
+ →
initialized |
+ 🌐 |
+
+
+
+クライアントは通知メッセージで初期化が完了したことを確認します。
+
+### 発見
+
+クライアントが利用可能な機能に関する情報をリクエストし、サーバーが利用可能なツールのリストで応答します。
+
+
+
+ | 💻 |
+ →
tools/list |
+ 🌐 |
+
+
+ | 💻 |
+ ←
response |
+ 🌐 |
+
+
+
+このプロセスは、各ツール、リソース、またはプロンプトタイプに対して繰り返される可能性があります。
+
+### 実行
+
+クライアントがホストのニーズに基づいて機能を呼び出します。
+
+
+
+ | 💻 |
+ →
tools/call |
+ 🌐 |
+
+
+ | 💻 |
+ ←
notification (オプションの進行状況) |
+ 🌐 |
+
+
+ | 💻 |
+ ←
response |
+ 🌐 |
+
+
+
+### 終了
+
+必要がなくなったときに接続が適切にクローズされ、サーバーがシャットダウンリクエストを確認します。
+
+
+
+ | 💻 |
+ →
shutdown |
+ 🌐 |
+
+
+ | 💻 |
+ ←
response |
+ 🌐 |
+
+
+ | 💻 |
+ →
exit |
+ 🌐 |
+
+
+
+クライアントは終了を完了するために最終的なexitメッセージを送信します。
+
+## プロトコルの進化
+
+MCPプロトコルは、拡張可能で適応性があるように設計されています。初期化フェーズにはバージョン交渉が含まれ、プロトコルの進化に伴って後方互換性を可能にします。さらに、機能発見によりクライアントが各サーバーが提供する特定の機能に適応できるようになり、同じエコシステム内で基本的なサーバーと高度なサーバーの混在を可能にします。
diff --git a/units/ja/unit1/gradio-mcp.mdx b/units/ja/unit1/gradio-mcp.mdx
new file mode 100644
index 0000000..1252680
--- /dev/null
+++ b/units/ja/unit1/gradio-mcp.mdx
@@ -0,0 +1,154 @@
+# Gradio MCP統合
+
+これまで、Model Context Protocol (MCP)の中核概念と、MCPサーバーとクライアントの実装方法について探ってきました。このセクションでは、GradioというライブラリでMCPサーバーを作成することで、実装をより簡単にしていきます!
+
+
+
+Gradioは、機械学習モデル用のカスタマイズ可能なWebインターフェースを素早く作成するための人気のPythonライブラリです。
+
+
+
+## Gradioの紹介
+
+Gradioを使うと、開発者はわずか数行のPythonコードでモデル用のUIを作成できます。特に以下の用途で有用です:
+
+- デモとプロトタイプの作成
+- 技術的でないユーザーとのモデル共有
+- モデルの動作のテストとデバッグ
+
+MCP対応が追加されたことで、Gradioは標準化されたMCPプロトコルを通じてAIモデルの機能を公開する直接的な方法を提供するようになりました。
+
+GradioとMCPを組み合わせることで、最小限のコードで人間にとって使いやすいインターフェースとAIがアクセス可能なツールの両方を作成できます。さらに素晴らしいことに、GradioはすでにAIコミュニティで広く使用されているため、MCPサーバーを他の人と共有するのにも使えます。
+
+## 前提条件
+
+MCP対応のGradioを使用するには、MCP拡張機能付きでGradioをインストールする必要があります:
+
+```bash
+pip install "gradio[mcp]"
+```
+
+また、Cursor(「MCPホスト」として知られる)などのMCPプロトコルを使用したツール呼び出しをサポートするLLMアプリケーションも必要です。
+
+## GradioでMCPサーバーを作成する
+
+Gradioを使用してMCPサーバーを作成する基本的な例を見てみましょう:
+
+```python
+import gradio as gr
+
+def letter_counter(word: str, letter: str) -> int:
+ """
+ 単語やテキスト内の文字の出現回数を数える。
+
+ Args:
+ word (str): 検索対象の入力テキスト
+ letter (str): 検索する文字
+
+ Returns:
+ int: テキスト内に文字が現れる回数
+ """
+ word = word.lower()
+ letter = letter.lower()
+ count = word.count(letter)
+ return count
+
+# 標準的なGradioインターフェースを作成
+demo = gr.Interface(
+ fn=letter_counter,
+ inputs=["textbox", "textbox"],
+ outputs="number",
+ title="Letter Counter",
+ description="テキストと文字を入力して、テキスト内にその文字が何回現れるかを数えます。"
+)
+
+# Gradio WebインターフェースとMCPサーバーの両方を起動
+if __name__ == "__main__":
+ demo.launch(mcp_server=True)
+```
+
+この設定により、文字カウンター関数は以下の方法でアクセス可能になります:
+
+1. 人間が直接操作できる従来のGradio Webインターフェース
+2. 互換性のあるクライアントに接続できるMCPサーバー
+
+MCPサーバーは以下のアドレスでアクセス可能になります:
+```
+http://your-server:port/gradio_api/mcp/sse
+```
+
+アプリケーション自体もアクセス可能で、以下のような外観になります:
+
+
+
+## 裏側での動作原理
+
+`launch()`で`mcp_server=True`を設定すると、いくつかのことが起こります:
+
+1. Gradio関数が自動的にMCPツールに変換される
+2. 入力コンポーネントがツール引数スキーマにマッピングされる
+3. 出力コンポーネントが応答形式を決定する
+4. GradioサーバーがMCPプロトコルメッセージも待機するようになる
+5. クライアント・サーバー通信のためのJSON-RPC over HTTP+SSEが設定される
+
+## Gradio <> MCP統合の主要機能
+
+1. **ツール変換**: GradioアプリのAPIエンドポイントはそれぞれ、対応する名前、説明、入力スキーマを持つMCPツールに自動変換されます。ツールとスキーマを確認するには、`http://your-server:port/gradio_api/mcp/schema`にアクセスするか、Gradioアプリのフッターにある「View API」リンクに移動し、「MCP」をクリックしてください。
+
+2. **環境変数サポート**: MCPサーバー機能を有効にする方法は2つあります:
+- `launch()`で`mcp_server`パラメータを使用:
+ ```python
+ demo.launch(mcp_server=True)
+ ```
+- 環境変数を使用:
+ ```bash
+ export GRADIO_MCP_SERVER=True
+ ```
+
+3. **ファイル処理**: サーバーは以下を含むファイルデータ変換を自動処理します:
+ - base64エンコードされた文字列をファイルデータに変換
+ - 画像ファイルを処理して正しい形式で返す
+ - 一時ファイルストレージの管理
+
+ MCPクライアントはローカルファイルを正しく処理しないことがあるため、入力画像とファイルは完全なURL(「http://...」または「https://...」)として渡すことを**強く**推奨します。
+
+4. **🤗 SpacesでホストされるMCPサーバー**: GradioアプリケーションをHugging Face Spacesで無料で公開でき、これにより無料でホストされるMCPサーバーを持つことができます。このようなSpaceの例はこちらです:https://huggingface.co/spaces/abidlabs/mcp-tools
+
+## トラブルシューティングのヒント
+
+1. **型ヒントとドキュメント文字列**: 関数には型ヒントと有効なドキュメント文字列を提供してください。ドキュメント文字列には、インデントされたパラメータ名を含む「Args:」ブロックを含める必要があります。
+
+2. **文字列入力**: 迷った場合は、入力引数を`str`として受け取り、関数内で望ましい型に変換してください。
+
+3. **SSEサポート**: MCPホストの中にはSSEベースのMCPサーバーをサポートしないものがあります。その場合は、`mcp-remote`を使用できます:
+ ```json
+ {
+ "mcpServers": {
+ "gradio": {
+ "command": "npx",
+ "args": [
+ "mcp-remote",
+ "http://your-server:port/gradio_api/mcp/sse"
+ ]
+ }
+ }
+ }
+ ```
+
+4. **再起動**: 接続の問題が発生した場合は、MCPクライアントとMCPサーバーの両方を再起動してみてください。
+
+## MCPサーバーを共有する
+
+GradioアプリをHugging Face Spacesに公開することで、MCPサーバーを共有できます。以下の動画では、Hugging Face Spaceの作成方法を紹介しています。
+
+
+
+これで、Hugging Face Spaceを共有することで、MCPサーバーを他の人と共有できるようになりました。
+
+## まとめ
+
+GradioのMCP統合は、MCPエコシステムへのアクセスしやすいエントリーポイントを提供します。Gradioのシンプルさを活用し、MCPの標準化を追加することで、開発者は最小限のコードで人間にとって使いやすいインターフェースとAIがアクセス可能なツールの両方を素早く作成できます。
+
+このコースを進めるにつれて、より洗練されたMCP実装を探求していきますが、Gradioはプロトコルの理解と実験のための優れた出発点を提供します。
+
+次のユニットでは、MCPアプリケーションの構築により深く掘り下げ、開発環境の設定、SDKの探索、より高度なMCPサーバーとクライアントの実装に焦点を当てます。
diff --git a/units/ja/unit1/introduction.mdx b/units/ja/unit1/introduction.mdx
new file mode 100644
index 0000000..212bae3
--- /dev/null
+++ b/units/ja/unit1/introduction.mdx
@@ -0,0 +1,33 @@
+# Model Context Protocol (MCP)の紹介
+
+MCPコースのユニット1へようこそ!このユニットでは、Model Context Protocolの基礎を探求していきます。
+
+## 学習内容
+
+このユニットでは、以下のことを学習します:
+
+* Model Context Protocolとは何か、そしてなぜ重要なのかを理解する
+* MCPに関連する主要概念と用語を学ぶ
+* MCPが解決する統合課題を探求する
+* MCPの主要な利点と目標を理解する
+* MCP統合の実際の動作例を見る
+
+このユニットの終了時には、MCPの基礎概念をしっかりと理解し、次のユニットでアーキテクチャと実装についてより深く学ぶ準備が整うでしょう。
+
+## MCPの重要性
+
+AIエコシステムは急速に進化しており、大規模言語モデル(LLM)や他のAIシステムがますます高性能になっています。しかし、これらのモデルは多くの場合、学習データに制限され、リアルタイム情報や専門ツールへのアクセスが不足しています。この制限により、多くのシナリオでAIシステムが真に関連性があり、正確で役立つ応答を提供する可能性が妨げられています。
+
+ここでModel Context Protocol(MCP)が登場します。MCPは、AIモデルが外部データソース、ツール、環境と接続することを可能にし、AIシステムと広範なデジタル世界の間で情報と機能のシームレスな転送を可能にします。この相互運用性は、真に有用なAIアプリケーションの成長と採用にとって重要です。
+
+## ユニット1の概要
+
+このユニットで取り扱う内容の簡単な概要は以下の通りです:
+
+1. **Model Context Protocolとは何か?** - MCPが何であり、AIエコシステムにおけるその役割について定義し、議論することから始めます。
+2. **主要概念** - MCPに関連する基本概念と用語を探求します。
+3. **統合課題** - MCPが解決を目指す問題、特に「M×N統合問題」を検討します。
+4. **利点と目標** - 標準化、強化されたAI機能、相互運用性を含む、MCPの主要な利点と目標について議論します。
+5. **シンプルな例** - 最後に、MCP統合のシンプルな例を見て、実際にどのように動作するかを確認します。
+
+Model Context Protocolのエキサイティングな世界を探求してみましょう!
\ No newline at end of file
diff --git a/units/ja/unit1/key-concepts.mdx b/units/ja/unit1/key-concepts.mdx
new file mode 100644
index 0000000..6058b76
--- /dev/null
+++ b/units/ja/unit1/key-concepts.mdx
@@ -0,0 +1,92 @@
+# 主要概念と用語
+
+Model Context Protocolについてより深く掘り下げる前に、MCPの基盤を形成する主要概念と用語を理解することが重要です。このセクションでは、プロトコルを支える基本的なアイデアを紹介し、コース全体を通じてMCP実装について議論するための共通語彙を提供します。
+
+MCPは「AIアプリケーション向けのUSB-C」としてよく説明されます。USB-Cが様々な周辺機器をコンピューティングデバイスに接続するための標準化された物理的および論理的インターフェースを提供するのと同様に、MCPはAIモデルを外部機能にリンクするための一貫したプロトコルを提供します。この標準化はエコシステム全体に利益をもたらします:
+
+- **ユーザー** はAIアプリケーション全体でよりシンプルで一貫した体験を享受できます
+- **AIアプリケーション開発者** は成長するツールとデータソースのエコシステムとの簡単な統合を得られます
+- **ツールとデータプロバイダー** は複数のAIアプリケーションで動作する単一の実装を作成するだけで済みます
+- より広範なエコシステムは相互運用性の向上、イノベーション、分断化の削減から恩恵を受けます
+
+## 統合問題
+
+**M×N統合問題**とは、標準化されたアプローチなしにM個の異なるAIアプリケーションをN個の異なる外部ツールやデータソースに接続する際の課題を指します。
+
+### MCPなしの場合(M×N問題)
+
+MCPのようなプロトコルがなければ、開発者はM×N個のカスタム統合を作成する必要があります—AIアプリケーションと外部機能の可能な組み合わせごとに1つずつ。
+
+
+
+各AIアプリケーションは、各ツール/データソースと個別に統合する必要があります。これは非常に複雑で高コストなプロセスであり、開発者に多くの摩擦をもたらし、高いメンテナンスコストが発生します。
+
+複数のモデルと複数のツールがある場合、統合の数は管理するには大きすぎ、それぞれが独自のユニークなインターフェースを持ちます。
+
+
+
+### MCPありの場合(M+Nソリューション)
+
+MCPは標準インターフェースを提供することで、これをM+N問題に変換します:各AIアプリケーションはMCPのクライアント側を一度実装し、各ツール/データソースはサーバー側を一度実装します。これにより統合の複雑性とメンテナンス負荷が劇的に削減されます。
+
+
+
+各AIアプリケーションはMCPのクライアント側を一度実装し、各ツール/データソースはサーバー側を一度実装します。
+
+## コアMCP用語
+
+MCPが解決する問題を理解した今、MCPプロトコルを構成するコア用語と概念に深く入りましょう。
+
+
+
+MCPはHTTPやUSB-Cのような標準であり、AIアプリケーションを外部ツールやデータソースに接続するためのプロトコルです。そのため、標準用語を使用することは、MCPを効果的に機能させるために重要です。
+
+アプリケーションを文書化し、コミュニティとコミュニケーションを取る際には、以下の用語を使用すべきです。
+
+
+
+### コンポーネント
+
+HTTPのクライアントサーバー関係と同じように、MCPにはクライアントとサーバーがあります。
+
+
+
+- **ホスト**: エンドユーザーが直接インタラクトするユーザー向けAIアプリケーション。例としては、AnthropicのClaude Desktop、CursorのようなAI強化IDE、Hugging Face Python SDKのような推論ライブラリ、またはLangChainやsmolagentsのようなライブラリで構築されたカスタムアプリケーションがあります。ホストはMCPサーバーへの接続を開始し、ユーザーリクエスト、LLM処理、外部ツール間の全体的なフローを統率します。
+
+- **クライアント**: 特定のMCPサーバーとのコミュニケーションを管理するホストアプリケーション内のコンポーネント。各クライアントは単一のサーバーとの1:1接続を維持し、MCPコミュニケーションのプロトコルレベルの詳細を処理し、ホストのロジックと外部サーバー間の中介役として機能します。
+
+- **サーバー**: MCPプロトコルを介して機能(ツール、リソース、プロンプト)を公開する外部プログラムまたはサービス。
+
+
+
+多くのコンテンツでは「クライアント」と「ホスト」が交換可能に使用されています。技術的に言えば、ホストはユーザー向けアプリケーションであり、クライアントは特定のMCPサーバーとのコミュニケーションを管理するホストアプリケーション内のコンポーネントです。
+
+
+
+### 機能
+
+もちろん、アプリケーションの価値は、それが提供する機能の総和です。したがって、機能はアプリケーションの最も重要な部分です。MCPはあらゆるソフトウェアサービスと接続できますが、多くのAIアプリケーションで使用される一般的な機能がいくつかあります。
+
+| 機能 | 説明 | 例 |
+| ---------- | ----------- | ------- |
+| **ツール** | AIモデルがアクションを実行したり、計算されたデータを取得するために呼び出すことができる実行可能な関数。通常、アプリケーションのユースケースに関連している。 | 天気アプリケーションのツールは、特定の場所の天気を返す関数である可能性があります。 |
+| **リソース** | 重要な計算を伴わずにコンテキストを提供する読み取り専用データソース。 | 研究アシスタントは科学論文のリソースを持っている可能性があります。 |
+| **プロンプト** | ユーザー、AIモデル、利用可能な機能間のインタラクションをガイドする事前定義されたテンプレートまたはワークフロー。 | 要約プロンプト。 |
+| **サンプリング** | クライアント/ホストにLLMインタラクションを実行させるサーバー開始のリクエストで、LLMが生成されたコンテンツをレビューし、さらなる決定を行うことを可能にする再帰的アクションを実現します。 | ライティングアプリケーションが自分の出力をレビューし、さらに精巧にすることを決定する。 |
+
+以下の図では、コードエージェントのユースケースに適用された集合的機能を見ることができます。
+
+
+
+このアプリケーションは、MCPエンティティを以下のように使用する可能性があります:
+
+| エンティティ | 名前 | 説明 |
+| --- | --- | --- |
+| ツール | コードインタープリター | LLMが書いたコードを実行できるツール。 |
+| リソース | ドキュメンテーション | アプリケーションのドキュメンテーションを含むリソース。 |
+| プロンプト | コードスタイル | LLMにコードを生成するようガイドするプロンプト。 |
+| サンプリング | コードレビュー | LLMがコードをレビューし、さらなる決定を行うことを可能にするサンプリング。 |
+
+### 結論
+
+これらの主要概念と用語を理解することは、MCPを効果的に使用するための基盤を提供します。以下のセクションでは、この基盤をベースに、Model Context Protocolを構成するアーキテクチャコンポーネント、コミュニケーションプロトコル、機能を探求していきます。
diff --git a/units/ja/unit1/mcp-clients.mdx b/units/ja/unit1/mcp-clients.mdx
new file mode 100644
index 0000000..6b1fa0d
--- /dev/null
+++ b/units/ja/unit1/mcp-clients.mdx
@@ -0,0 +1,357 @@
+# MCPクライアント
+
+Model Context Protocol (MCP) の基本的な理解を深めた今、MCPエコシステムにおけるMCPクライアントの重要な役割を探ることができます。
+
+Unit 1のこの部分では、Model Context Protocol (MCP) エコシステムにおけるMCPクライアントの重要な役割を探ります。
+
+このセクションでは、次のことを学習します:
+
+* MCPクライアントとは何か、MCPアーキテクチャにおける役割を理解する
+* MCPクライアントの主要な責任について学ぶ
+* 主要なMCPクライアント実装を探る
+* Hugging FaceのMCPクライアント実装の使用方法を発見する
+* MCPクライアント使用の実践的な例を確認する
+
+
+
+このページでは、JSON記法を使用してMCPクライアントをいくつかの異なる方法で設定する例を示します。今のところ、MCPサーバーへのパスを表すために `path/to/server.py` のような*例*を使用します。次のユニットでは、これを実際のMCPサーバーで実装します。
+
+今は、MCPクライアント記法の理解に集中してください。MCPサーバーは次のユニットで実装します。
+
+
+
+## MCPクライアントの理解
+
+MCPクライアントは、AIアプリケーション(ホスト)とMCPサーバーによって提供される外部機能との間の橋渡しとして機能する重要なコンポーネントです。ホストをメインアプリケーション(AIアシスタントやIDEなど)として、クライアントをそのホスト内でMCP通信の処理を担当する専用モジュールとして考えてください。
+
+## ユーザーインターフェースクライアント
+
+MCPで利用可能なユーザーインターフェースクライアントを探ることから始めましょう。
+
+### チャットインターフェースクライアント
+
+AnthropicのClaude Desktopは、最も著名なMCPクライアントの一つとして、様々なMCPサーバーとの統合を提供しています。
+
+### インタラクティブ開発クライアント
+
+CursorのMCPクライアント実装は、コード編集機能との直接統合を通じてAI駆動のコーディング支援を可能にします。複数のMCPサーバー接続をサポートし、コーディング中にリアルタイムでツール呼び出しを提供するため、開発者にとって強力なツールとなっています。
+
+Continue.devは、MCPをサポートし、VS CodeからMCPサーバーに接続するインタラクティブ開発クライアントの別の例です。
+
+## MCPクライアントの設定
+
+MCPプロトコルのコアを扱った今、MCPサーバーとクライアントの設定方法を見てみましょう。
+
+MCPサーバーとクライアントの効果的な展開には適切な設定が必要です。
+
+
+
+MCP仕様はまだ進化しているため、設定方法は進化の対象となります。設定の現在のベストプラクティスに焦点を当てます。
+
+
+
+### MCP設定ファイル
+
+MCPホストは設定ファイルを使用してサーバー接続を管理します。これらのファイルは、どのサーバーが利用可能で、どのように接続するかを定義します。
+
+幸い、設定ファイルは非常にシンプルで理解しやすく、主要なMCPホスト間で一貫しています。
+
+#### `mcp.json` 構造
+
+MCPの標準設定ファイルは `mcp.json` という名前です。基本構造は次のとおりです:
+
+これは `mcp.json` の基本構造で、Claude Desktop、Cursor、VS Codeなどのアプリケーションに渡すことができます。
+
+```json
+{
+ "servers": [
+ {
+ "name": "Server Name",
+ "transport": {
+ "type": "stdio|sse",
+ // Transport-specific configuration
+ }
+ }
+ ]
+}
+```
+
+この例では、名前と転送タイプを持つ単一のサーバーがあります。転送タイプは `stdio` または `sse` のいずれかです。
+
+#### stdio転送の設定
+
+stdio転送を使用するローカルサーバーの場合、設定にはサーバープロセスを起動するコマンドと引数が含まれます:
+
+```json
+{
+ "servers": [
+ {
+ "name": "File Explorer",
+ "transport": {
+ "type": "stdio",
+ "command": "python",
+ "args": ["/path/to/file_explorer_server.py"] // これは例です。次のユニットで実際のサーバーを使用します
+ }
+ }
+ ]
+}
+```
+
+ここでは、ローカルスクリプトである「File Explorer」というサーバーがあります。
+
+#### HTTP+SSE転送の設定
+
+HTTP+SSE転送を使用するリモートサーバーの場合、設定にはサーバーURLが含まれます:
+
+```json
+{
+ "servers": [
+ {
+ "name": "Remote API Server",
+ "transport": {
+ "type": "sse",
+ "url": "https://example.com/mcp-server"
+ }
+ }
+ ]
+}
+```
+
+#### 設定における環境変数
+
+環境変数は `env` フィールドを使用してサーバープロセスに渡すことができます。サーバーコードでアクセスする方法は次のとおりです:
+
+
+
+
+Pythonでは、`os` モジュールを使用して環境変数にアクセスします:
+
+```python
+import os
+
+# 環境変数にアクセス
+github_token = os.environ.get("GITHUB_TOKEN")
+if not github_token:
+ raise ValueError("GITHUB_TOKEN environment variable is required")
+
+# サーバーコードでトークンを使用
+def make_github_request():
+ headers = {"Authorization": f"Bearer {github_token}"}
+ # ... コードの残り
+```
+
+
+
+
+JavaScriptでは、`process.env` オブジェクトを使用して環境変数にアクセスします:
+
+```javascript
+// 環境変数にアクセス
+const githubToken = process.env.GITHUB_TOKEN;
+if (!githubToken) {
+ throw new Error("GITHUB_TOKEN environment variable is required");
+}
+
+// サーバーコードでトークンを使用
+function makeGithubRequest() {
+ const headers = { "Authorization": `Bearer ${githubToken}` };
+ // ... コードの残り
+}
+```
+
+
+
+
+`mcp.json` の対応する設定は次のようになります:
+
+```json
+{
+ "servers": [
+ {
+ "name": "GitHub API",
+ "transport": {
+ "type": "stdio",
+ "command": "python",
+ "args": ["/path/to/github_server.py"], // これは例です。次のユニットで実際のサーバーを使用します
+ "env": {
+ "GITHUB_TOKEN": "your_github_token"
+ }
+ }
+ }
+ ]
+}
+```
+
+### 設定例
+
+実際の設定シナリオを見てみましょう:
+
+#### シナリオ1:ローカルサーバー設定
+
+このシナリオでは、ファイルエクスプローラーやコードエディターなどのPythonスクリプトであるローカルサーバーがあります。
+
+```json
+{
+ "servers": [
+ {
+ "name": "File Explorer",
+ "transport": {
+ "type": "stdio",
+ "command": "python",
+ "args": ["/path/to/file_explorer_server.py"] // これは例です。次のユニットで実際のサーバーを使用します
+ }
+ }
+ ]
+}
+```
+
+#### シナリオ2:リモートサーバー設定
+
+このシナリオでは、天気APIであるリモートサーバーがあります。
+
+```json
+{
+ "servers": [
+ {
+ "name": "Weather API",
+ "transport": {
+ "type": "sse",
+ "url": "https://example.com/mcp-server" // これは例です。次のユニットで実際のサーバーを使用します
+ }
+ }
+ ]
+}
+```
+
+適切な設定は、MCP統合の成功した展開に不可欠です。これらの側面を理解することで、AIアプリケーションと外部機能の間の堅牢で信頼性の高い接続を作成できます。
+
+次のセクションでは、Hugging Face Hubで利用可能なMCPサーバーのエコシステムと、そこで独自のサーバーを公開する方法を探ります。
+
+## Tiny Agentsクライアント
+
+今度は、コード内でMCPクライアントを使用する方法を探ってみましょう。
+
+コードから直接MCPサーバーに接続するMCPクライアントとしてtiny agentsを使用することもできます。Tiny agentsは、MCPサーバーからツールを使用できるAIエージェントを作成する簡単な方法を提供します。
+
+Tiny Agentはコマンドライン環境でMCPサーバーを実行できます。これを行うには、`npm` をインストールし、`npx` でサーバーを実行する必要があります。**PythonとJavaScriptの両方でこれらが必要です。**
+
+`npm` で `npx` をインストールしましょう。`npm` がインストールされていない場合は、[npm documentation](https://docs.npmjs.com/downloading-and-installing-node-js-and-npm)を確認してください。
+
+### セットアップ
+
+まず、インストールされていない場合は `npx` をインストールする必要があります。次のコマンドでこれを行うことができます:
+
+```bash
+# npxをインストール
+npm install -g npx
+```
+
+次に、MCPサポート付きのhuggingface_hubパッケージをインストールする必要があります。これにより、MCPサーバーとクライアントを実行できるようになります。
+
+```bash
+pip install "huggingface_hub[mcp]>=0.32.0"
+```
+
+次に、MCPサーバーにアクセスするためにHugging Face Hubにログインする必要があります。これは `huggingface-cli` コマンドラインツールで行うことができます。これを行うには[ログイントークン](https://huggingface.co/docs/huggingface_hub/v0.32.3/en/quick-start#authentication)が必要です。
+
+```bash
+huggingface-cli login
+```
+
+
+
+
+### MCPサーバーへの接続
+
+今度は、エージェント設定ファイル `agent.json` を作成しましょう。
+
+```json
+{
+ "model": "Qwen/Qwen2.5-72B-Instruct",
+ "provider": "nebius",
+ "servers": [
+ {
+ "type": "stdio",
+ "config": {
+ "command": "npx",
+ "args": ["@playwright/mcp@latest"]
+ }
+ }
+ ]
+}
+```
+
+この設定では、`@playwright/mcp` MCPサーバーを使用しています。これは、PlaywrightでブラウザーをコントロールできるMCPサーバーです。
+
+これでエージェントを実行できます:
+
+```bash
+tiny-agents run agent.json
+```
+
+
+
+まず、[npm](https://docs.npmjs.com/downloading-and-installing-node-js-and-npm)でtiny agentsパッケージをインストールします。
+
+```bash
+npm install @huggingface/tiny-agents
+```
+
+### MCPサーバーへの接続
+
+エージェントプロジェクトディレクトリを作成し、`agent.json` ファイルを作成します。
+
+```bash
+mkdir my-agent
+touch my-agent/agent.json
+```
+
+`my-agent/agent.json` でエージェント設定ファイルを作成します:
+
+```json
+{
+ "model": "Qwen/Qwen2.5-72B-Instruct",
+ "provider": "nebius",
+ "servers": [
+ {
+ "type": "stdio",
+ "config": {
+ "command": "npx",
+ "args": ["@playwright/mcp@latest"]
+ }
+ }
+ ]
+}
+```
+
+これでエージェントを実行できます:
+
+```bash
+npx @huggingface/tiny-agents run ./my-agent
+```
+
+
+
+
+下のビデオでは、エージェントを実行してブラウザーで新しいタブを開くように依頼しています。
+
+次の例は、Nebius推論プロバイダー経由で[Qwen/Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct)モデルを使用するように設定されたWebブラウジングエージェントを示しており、playwright MCPサーバーが装備されているため、Webブラウザーを使用できます!エージェント設定は、[`tiny-agents/tiny-agents`](https://huggingface.co/datasets/tiny-agents/tiny-agents/tree/main/celinah/web-browser) Hugging Faceデータセット内のパスを指定して読み込まれます。
+
+
+
+エージェントを実行すると、読み込み中に接続されたMCPサーバーから発見したツールをリストアップし、その後プロンプトの準備が整います!
+
+このデモで使用されたプロンプト:
+
+> do a Web Search for HF inference providers on Brave Search and open the first result and then give me the list of the inference providers supported on Hugging Face
+
+## 次のステップ
+
+MCPクライアントを理解した今、次のことができます:
+* 特定のMCPサーバー実装を探る
+* カスタムMCPクライアントの作成について学ぶ
+* 高度なMCP統合パターンに深く入り込む
+
+Model Context Protocolの世界への旅を続けましょう!
diff --git a/units/ja/unit1/quiz1.mdx b/units/ja/unit1/quiz1.mdx
new file mode 100644
index 0000000..97ea347
--- /dev/null
+++ b/units/ja/unit1/quiz1.mdx
@@ -0,0 +1,125 @@
+# クイズ1:MCP基礎
+
+Model Context Protocolの主要概念の理解をテストしてください。
+
+### Q1: Model Context Protocol(MCP)の主要な目的は何ですか?
+
+
+
+### Q2: MCPが主に解決を目指している問題は何ですか?
+
+
+
+### Q3: 以下のうち、MCPの主要な利点はどれですか?
+
+
+
+### Q4: MCP用語で「ホスト」とは何ですか?
+
+
+
+### Q5: AIアプリケーションのコンテキストで「M×N統合問題」とは何を指しますか?
+
+
+
+このクイズを完了おめでとうございます🥳!要素を復習する必要がある場合は、時間をかけて章を見直して知識を強化してください。
\ No newline at end of file
diff --git a/units/ja/unit1/quiz2.mdx b/units/ja/unit1/quiz2.mdx
new file mode 100644
index 0000000..d6a5b03
--- /dev/null
+++ b/units/ja/unit1/quiz2.mdx
@@ -0,0 +1,125 @@
+# クイズ2:MCP SDK
+
+MCP SDKとその機能に関する知識をテストしてください。
+
+### Q1: MCP SDKの主要な目的は何ですか?
+
+
+
+### Q2: MCP SDKが通常処理する機能は次のうちどれですか?
+
+
+
+### Q3: 提供されたテキストによると、MCPの公式Python SDKを維持している会社はどこですか?
+
+
+
+### Q4: `server.py`という名前のPythonファイルを使用して開発用MCPサーバーを開始するために使用されるコマンドは何ですか?
+
+
+
+### Q5: MCPにおけるJSON-RPC 2.0の役割は何ですか?
+
+
+
+このクイズを完了おめでとうございます🥳!要素を復習する必要がある場合は、時間をかけて章を見直して知識を強化してください。
\ No newline at end of file
diff --git a/units/ja/unit1/sdk.mdx b/units/ja/unit1/sdk.mdx
new file mode 100644
index 0000000..765c06f
--- /dev/null
+++ b/units/ja/unit1/sdk.mdx
@@ -0,0 +1,179 @@
+# MCP SDK
+
+Model Context Protocolは、JavaScript、Python、その他の言語向けの公式SDKを提供しています。これにより、アプリケーションでMCPクライアントとサーバーを簡単に実装できます。これらのSDKは低レベルのプロトコル詳細を処理し、アプリケーションの機能構築に集中できるようにします。
+
+## SDKの概要
+
+両SDKは、先ほど説明したMCPプロトコル仕様に従って、同様のコア機能を提供します。これらは以下を処理します:
+
+- プロトコルレベルの通信
+- 機能の登録と発見
+- メッセージのシリアライゼーション/デシリアライゼーション
+- 接続管理
+- エラーハンドリング
+
+## コアプリミティブの実装
+
+両SDKを使用してコアプリミティブ(ツール、リソース、プロンプト)のそれぞれを実装する方法を探求してみましょう。
+
+
+
+
+
+
+```python
+from mcp.server.fastmcp import FastMCP
+
+# Create an MCP server
+mcp = FastMCP("Weather Service")
+
+# Tool implementation
+@mcp.tool()
+def get_weather(location: str) -> str:
+ """Get the current weather for a specified location."""
+ return f"Weather in {location}: Sunny, 72°F"
+
+# Resource implementation
+@mcp.resource("weather://{location}")
+def weather_resource(location: str) -> str:
+ """Provide weather data as a resource."""
+ return f"Weather data for {location}: Sunny, 72°F"
+
+# Prompt implementation
+@mcp.prompt()
+def weather_report(location: str) -> str:
+ """Create a weather report prompt."""
+ return f"""You are a weather reporter. Weather report for {location}?"""
+
+
+# Run the server
+if __name__ == "__main__":
+ mcp.run()
+```
+
+サーバーを実装したら、サーバースクリプトを実行して起動できます。
+
+```bash
+mcp dev server.py
+```
+
+
+
+
+```javascript
+// index.mjs
+import {
+ McpServer,
+ ResourceTemplate,
+} from "@modelcontextprotocol/sdk/server/mcp.js";
+import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
+import { z } from "zod";
+
+// Create an MCP server
+const server = new McpServer({
+ name: "Weather Service",
+ version: "1.0.0",
+});
+
+// Tool implementation
+server.tool("get_weather", { location: z.string() }, async ({ location }) => ({
+ content: [
+ {
+ type: "text",
+ text: `Weather in ${location}: Sunny, 72°F`,
+ },
+ ],
+}));
+
+// Resource implementation
+server.resource(
+ "weather",
+ new ResourceTemplate("weather://{location}", { list: undefined }),
+ async (uri, { location }) => ({
+ contents: [
+ {
+ uri: uri.href,
+ text: `Weather data for ${location}: Sunny, 72°F`,
+ },
+ ],
+ })
+);
+
+// Prompt implementation
+server.prompt(
+ "weather_report",
+ { location: z.string() },
+ async ({ location }) => ({
+ messages: [
+ {
+ role: "assistant",
+ content: {
+ type: "text",
+ text: "You are a weather reporter.",
+ },
+ },
+ {
+ role: "user",
+ content: {
+ type: "text",
+ text: `Weather report for ${location}?`,
+ },
+ },
+ ],
+ })
+);
+
+// Run the server
+const transport = new StdioServerTransport();
+await server.connect(transport);
+```
+
+サーバーを実装したら、サーバースクリプトを実行して起動できます。
+
+```bash
+npx @modelcontextprotocol/inspector node ./index.mjs
+```
+
+
+
+
+これにより、ファイル`server.py`を実行する開発サーバーが初期化され、以下の出力がログに表示されます:
+
+```bash
+Starting MCP inspector...
+⚙️ Proxy server listening on port 6277
+Spawned stdio transport
+Connected MCP client to backing server transport
+Created web app transport
+Set up MCP proxy
+🔍 MCP Inspector is up and running at http://127.0.0.1:6274 🚀
+```
+
+その後、[http://127.0.0.1:6274](http://127.0.0.1:6274)でMCP Inspectorを開いて、サーバーの機能を見て、それらとインタラクトできます。
+
+UIを通じてサーバーの機能とそれらを呼び出す機能が表示されます。
+
+
+
+## MCP SDK
+
+MCPは言語非依存に設計されており、いくつかの人気のあるプログラミング言語向けの公式SDKが利用可能です:
+
+| 言語 | リポジトリ | メンテナー | ステータス |
+| ---------- | -------------------------------------------------------------------------------------------------------- | ------------------- | ---------------- |
+| TypeScript | [github.com/modelcontextprotocol/typescript-sdk](https://github.com/modelcontextprotocol/typescript-sdk) | Anthropic | アクティブ |
+| Python | [github.com/modelcontextprotocol/python-sdk](https://github.com/modelcontextprotocol/python-sdk) | Anthropic | アクティブ |
+| Java | [github.com/modelcontextprotocol/java-sdk](https://github.com/modelcontextprotocol/java-sdk) | Spring AI (VMware) | アクティブ |
+| Kotlin | [github.com/modelcontextprotocol/kotlin-sdk](https://github.com/modelcontextprotocol/kotlin-sdk) | JetBrains | アクティブ |
+| C# | [github.com/modelcontextprotocol/csharp-sdk](https://github.com/modelcontextprotocol/csharp-sdk) | Microsoft | アクティブ (プレビュー) |
+| Swift | [github.com/modelcontextprotocol/swift-sdk](https://github.com/modelcontextprotocol/swift-sdk) | loopwork-ai | アクティブ |
+| Rust | [github.com/modelcontextprotocol/rust-sdk](https://github.com/modelcontextprotocol/rust-sdk) | Anthropic/Community | アクティブ |
+| Dart | [https://github.com/leehack/mcp_dart](https://github.com/leehack/mcp_dart) | Flutter Community | アクティブ |
+
+これらのSDKは、MCPプロトコルとの作業を簡素化する言語固有の抽象化を提供し、低レベルのプロトコル詳細を扱うことなく、サーバーやクライアントのコアロジックの実装に集中できるようにします。
+
+## 次のステップ
+
+MCPでできることの表面をかじっただけですが、すでに基本的なサーバーが動作しています。実際、ブラウザでMCPクライアントを使用して接続しています。
+
+次のセクションでは、LLMからサーバーに接続する方法を見ていきます。
diff --git a/units/ja/unit1/unit1-recap.mdx b/units/ja/unit1/unit1-recap.mdx
new file mode 100644
index 0000000..51d496d
--- /dev/null
+++ b/units/ja/unit1/unit1-recap.mdx
@@ -0,0 +1,45 @@
+# Unit1 まとめ
+
+## Model Context Protocol (MCP)
+
+MCPは、AIモデルを外部ツール、データソース、環境と接続するために設計された標準化されたプロトコルです。相互運用性を可能にし、リアルタイム情報へのアクセスを提供することで、既存のAIシステムの制限に対処します。
+
+## 主要概念
+
+### クライアント・サーバー・アーキテクチャ
+MCPはクライアントがユーザーとサーバー間の通信を管理するクライアント・サーバーモデルに従います。このアーキテクチャはモジュラー性を促進し、既存のホストに変更を加えることなく新しいサーバーの追加を容易にします。
+
+### コンポーネント
+#### ホスト
+エンドユーザーのインターフェースとして機能するユーザー向けAIアプリケーション。
+
+##### クライアント
+特定のMCPサーバーとの通信を管理する責任を持つホストアプリケーション内のコンポーネント。クライアントはサーバーとの1:1接続を維持し、プロトコルレベルの詳細を処理します。
+
+#### サーバー
+MCPプロトコルを介してツール、データソース、またはサービスへのアクセスを提供する外部プログラムまたはサービス。サーバーは既存の機能の軽量なラッパーとして機能します。
+
+### 機能
+#### ツール
+アクションを実行できる実行可能な関数(例:メッセージの送信、APIのクエリ)。ツールは通常モデル制御であり、副作用を伴うアクションを実行する能力があるため、ユーザーの承認が必要です。
+
+#### リソース
+重要な計算を伴わずにコンテキスト取得のための読み取り専用データソース。リソースはアプリケーション制御であり、REST APIのGETエンドポイントと同様にデータ取得用に設計されています。
+
+#### プロンプト
+ユーザー、AIモデル、利用可能な機能間のインタラクションをガイドする事前定義されたテンプレートまたはワークフロー。プロンプトはユーザー制御であり、インタラクションのコンテキストを設定します。
+
+#### サンプリング
+LLM処理のためのサーバー開始のリクエストで、サーバー駆動のエージェンティック行動と潜在的に再帰的またはマルチステップインタラクションを可能にします。サンプリング操作は通常ユーザーの承認が必要です。
+
+### 通信プロトコル
+MCPプロトコルは、クライアントとサーバー間の通信のメッセージ形式としてJSON-RPC 2.0を使用します。2つの主要な転送メカニズムがサポートされています:stdio(ローカル通信用)とHTTP+SSE(リモート通信用)。メッセージには、リクエスト、レスポンス、通知が含まれます。
+
+### 発見プロセス
+MCPは、クライアントがリストメソッド(例:`tools/list`)を通じて利用可能なツール、リソース、プロンプトを動的に発見することを可能にします。この動的発見メカニズムにより、クライアントは各サーバーが提供する特定の機能に適応でき、サーバー機能のハードコードされた知識を必要としません。
+
+### MCP SDK
+MCPクライアントとサーバーの実装のために、様々なプログラミング言語で公式SDKが利用可能です。これらのSDKは、プロトコルレベルの通信、機能登録、エラーハンドリングを処理し、開発プロセスを簡素化します。
+
+### Gradio統合
+GradioはMCPプロトコルに機能を公開するWebインターフェースの簡単な作成を可能にし、人間とAIモデルの両方がアクセスできるようにします。この統合は、最小限のコードで人間にとって使いやすいインターフェースとAIがアクセス可能なツールを提供します。
diff --git a/units/ja/unit2/clients.mdx b/units/ja/unit2/clients.mdx
new file mode 100644
index 0000000..02391c2
--- /dev/null
+++ b/units/ja/unit2/clients.mdx
@@ -0,0 +1,136 @@
+# MCPクライアントの構築
+
+このセクションでは、異なるプログラミング言語を使用してMCPサーバーと相互作用できるクライアントを作成します。HuggingFace.jsを使用したJavaScriptクライアントとsmolagentsを使用したPythonクライアントの両方を実装します。
+
+## MCPクライアントの設定
+
+MCPサーバーとクライアントの効果的なデプロイには適切な設定が必要です。MCP仕様はまだ進化しているため、設定方法は進化する可能性があります。現在の設定のベストプラクティスに焦点を当てます。
+
+### MCP設定ファイル
+
+MCPホストは設定ファイルを使用してサーバー接続を管理します。これらのファイルは、利用可能なサーバーとそれらへの接続方法を定義します。
+
+設定ファイルは非常にシンプルで、理解しやすく、主要なMCPホスト間で一貫しています。
+
+#### `mcp.json`構造
+
+MCPの標準設定ファイルは`mcp.json`という名前です。基本的な構造は以下の通りです:
+
+```json
+{
+ "servers": [
+ {
+ "name": "MCP Server",
+ "transport": {
+ "type": "sse",
+ "url": "http://localhost:7860/gradio_api/mcp/sse"
+ }
+ }
+ ]
+}
+```
+
+この例では、SSEトランスポートを使用し、ポート7860で実行されているローカルGradioサーバーに接続する単一のサーバーが設定されています。
+
+
+
+Gradioアプリがリモートサーバーで実行されていると仮定しているため、SSEトランスポート経由でGradioアプリに接続しています。しかし、ローカルスクリプトに接続したい場合は、`sse`トランスポートの代わりに`stdio`トランスポートを使用することがより良い選択肢です。
+
+
+
+#### HTTP+SSEトランスポートの設定
+
+HTTP+SSEトランスポートを使用するリモートサーバーの場合、設定にはサーバーURLが含まれます:
+
+```json
+{
+ "servers": [
+ {
+ "name": "Remote MCP Server",
+ "transport": {
+ "type": "sse",
+ "url": "https://example.com/gradio_api/mcp/sse"
+ }
+ }
+ ]
+}
+```
+
+この設定により、UIクライアントはMCPプロトコルを使用してGradio MCPサーバーと通信でき、フロントエンドとMCPサービス間のシームレスな統合を可能にします。
+
+## UI MCPクライアントの設定
+
+Gradio MCPサーバーで作業する場合、MCPプロトコルを使用してサーバーに接続するようにUIクライアントを設定できます。設定方法は以下の通りです:
+
+### 基本設定
+
+以下の設定で`config.json`という新しいファイルを作成してください:
+
+```json
+{
+ "mcpServers": {
+ "mcp": {
+ "url": "http://localhost:7860/gradio_api/mcp/sse"
+ }
+ }
+}
+```
+
+この設定により、UIクライアントはMCPプロトコルを使用してGradio MCPサーバーと通信でき、フロントエンドとMCPサービス間のシームレスな統合を可能にします。
+
+## Cursor IDE内でのMCPクライアントの設定
+
+Cursorは組み込みMCPサポートを提供し、デプロイされたMCPサーバーを開発環境に直接接続できます。
+
+### 設定
+
+Cursor設定(`Ctrl + Shift + J` / `Cmd + Shift + J`)→ **MCP**タブ→ **Add new global MCP server**を開きます:
+
+**macOS:**
+```json
+{
+ "mcpServers": {
+ "sentiment-analysis": {
+ "command": "npx",
+ "args": [
+ "-y",
+ "mcp-remote",
+ "https://YOURUSENAME-mcp-sentiment.hf.space/gradio_api/mcp/sse",
+ "--transport",
+ "sse-only"
+ ]
+ }
+ }
+}
+```
+
+**Windows:**
+```json
+{
+ "mcpServers": {
+ "sentiment-analysis": {
+ "command": "cmd",
+ "args": [
+ "/c",
+ "npx",
+ "-y",
+ "mcp-remote",
+ "https://YOURUSENAME-mcp-sentiment.hf.space/gradio_api/mcp/sse",
+ "--transport",
+ "sse-only"
+ ]
+ }
+ }
+}
+```
+
+### mcp-remoteを使用する理由
+
+Cursorを含むほとんどのMCPクライアントは、現在stdioトランスポート経由のローカルサーバーのみをサポートしており、OAuth認証を使用するリモートサーバーはまだサポートしていません。`mcp-remote`ツールは以下の機能を提供するブリッジソリューションとして機能します:
+
+- マシン上でローカルに実行
+- CursorからリモートMCPサーバーへのリクエストを転送
+- 馴染みのある設定ファイル形式を使用
+
+設定完了後、コードコメント、ユーザーフィードバック、プルリクエストの説明の分析などのタスクに、感情分析ツールを使用するようにCursorに求めることができます。
+
diff --git a/units/ja/unit2/continue-client.mdx b/units/ja/unit2/continue-client.mdx
new file mode 100644
index 0000000..e368ebb
--- /dev/null
+++ b/units/ja/unit2/continue-client.mdx
@@ -0,0 +1,193 @@
+# ローカルおよびオープンソースモデルでのMCPの使用
+
+このセクションでは、Ollamaのようなローカルツールと連携するAIコーディングアシスタント構築ツールであるContinueを使用して、MCPをローカルおよびオープンソースモデルと接続します。
+
+## Continueのセットアップ
+
+ContinueはVS Code マーケットプレイスからインストールできます。
+
+
+
+*Continueは[JetBrains](https://plugins.jetbrains.com/plugin/22707-continue)の拡張機能もあります。*
+
+
+
+### VS Code拡張機能
+
+1. [Visual Studio MarketplaceのContinue拡張機能ページ](https://marketplace.visualstudio.com/items?itemName=Continue.continue)で`Install`をクリック
+2. これによりVS CodeでContinue拡張機能ページが開き、そこで再度`Install`をクリックする必要があります
+3. Continueロゴが左サイドバーに表示されます。より良い体験のために、Continueを右サイドバーに移動してください
+
+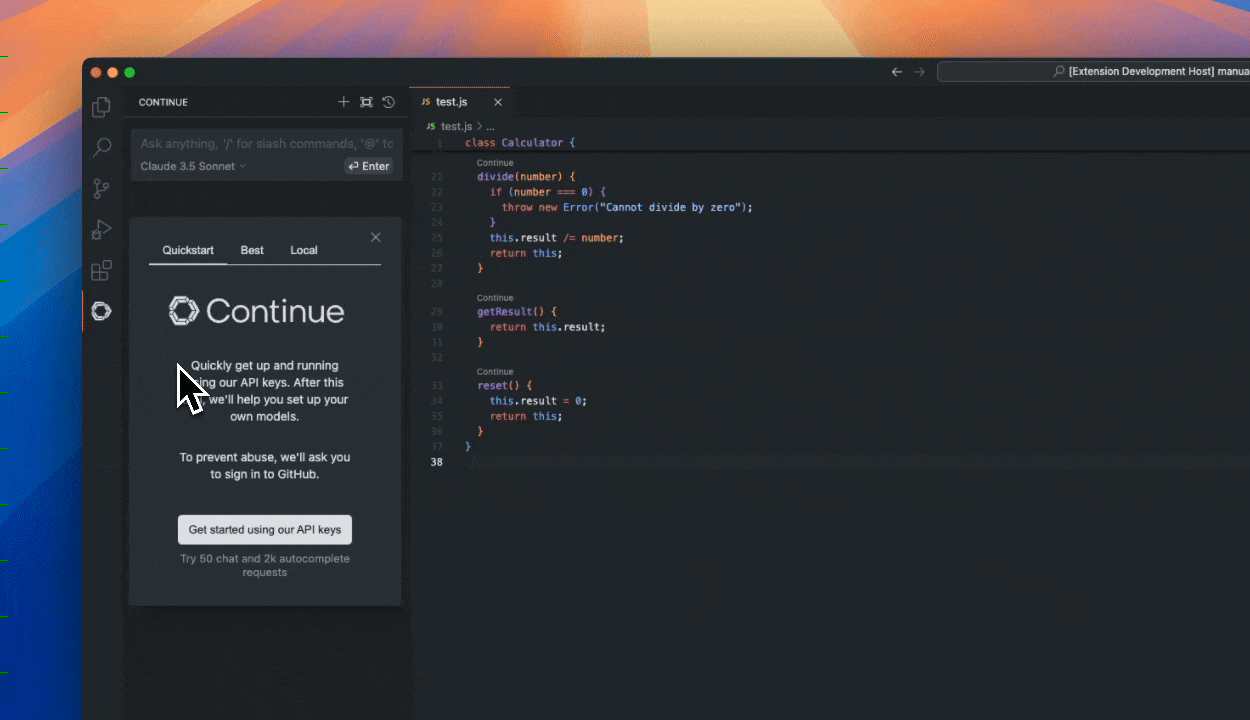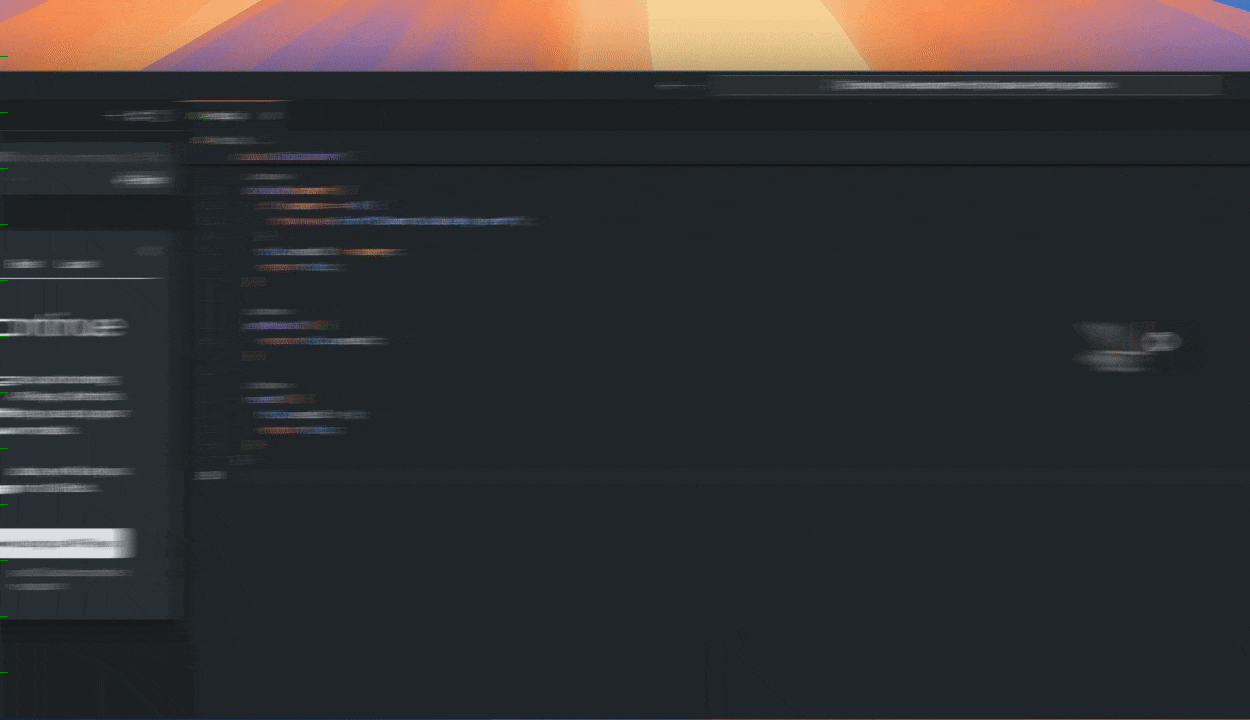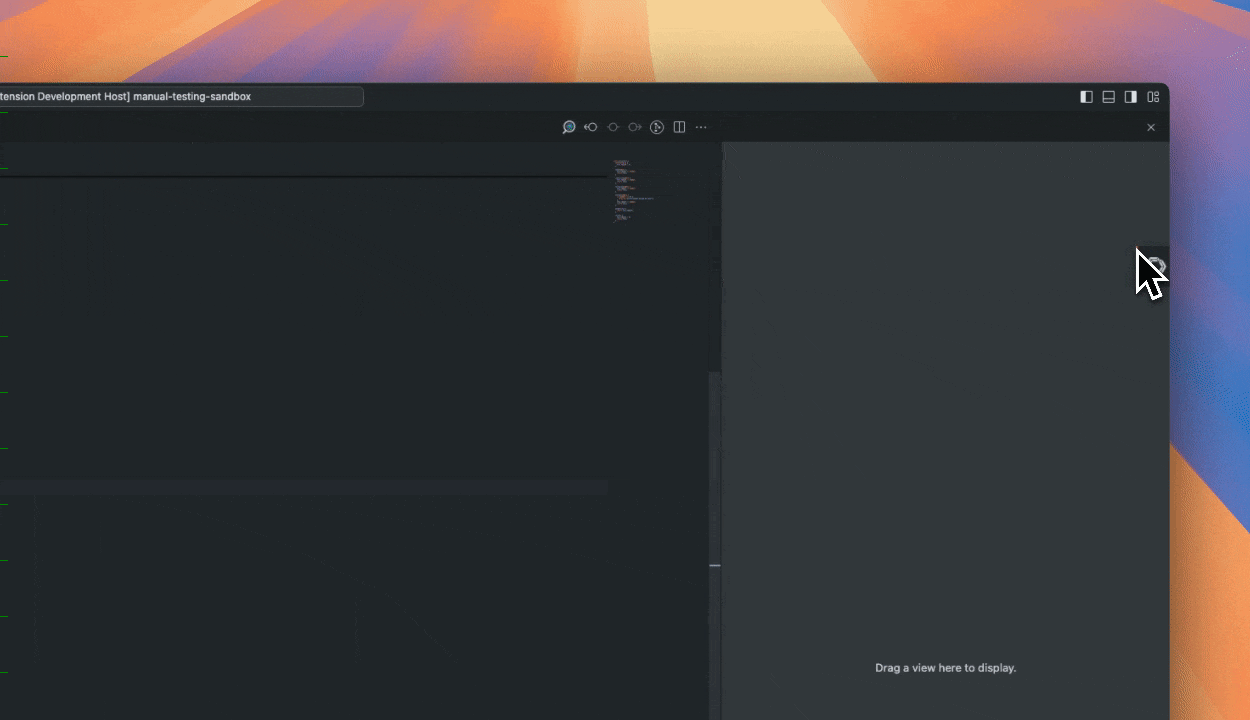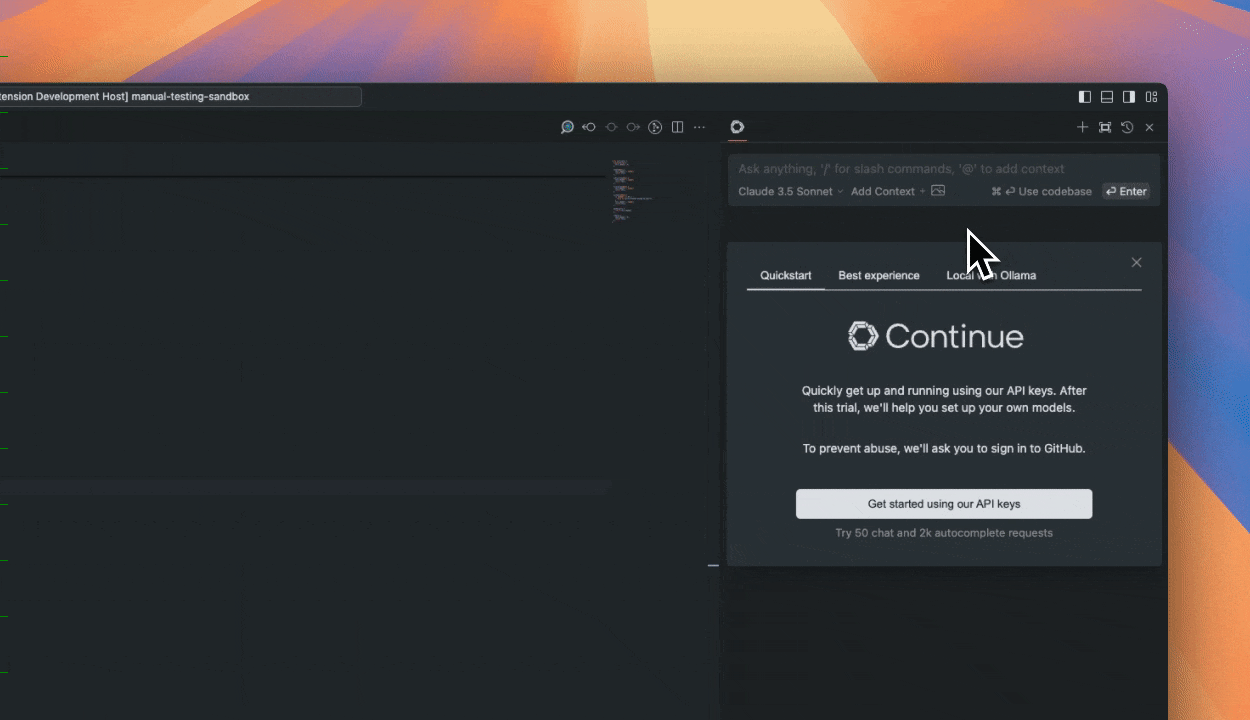
+
+Continueの設定が完了したら、ローカルモデルを取得するためのOllamaのセットアップに移ります。
+
+### ローカルモデル
+
+Continueと互換性のあるローカルモデルを実行する方法は多数あります。人気のある3つのオプションは、Ollama、Llama.cpp、LM Studioです。Ollamaは、ユーザーが大規模言語モデル(LLM)をローカルで簡単に実行できるオープンソースツールです。Llama.cppは、OpenAI互換サーバーも含むLLM実行用の高性能C++ライブラリです。LM Studioは、ローカルモデルを実行するためのグラフィカルインターフェースを提供します。
+
+Hugging Face Hubからローカルモデルにアクセスし、すべての主要なローカル推論アプリのコマンドとクイックリンクを取得できます。
+
+
+
+
+
+
+Llama.cppは、LLMを提供するための軽量でOpenAI API互換のHTTPサーバーである`llama-server`を提供しています。[Llama.cppリポジトリ](https://github.com/ggml-org/llama.cpp)の指示に従ってソースからビルドするか、システムで利用可能な場合は事前にビルドされたバイナリを使用できます。詳細については、[Llama.cppドキュメント](https://github.com/ggerganov/llama.cpp)をご確認ください。
+
+`llama-server`を入手したら、次のようなコマンドでHugging Faceからモデルを実行できます:
+
+```bash
+llama-server -hf unsloth/Devstral-Small-2505-GGUF:Q4_K_M
+```
+
+
+
+LM Studioは、Mac、Windows、Linuxで利用可能なアプリケーションで、グラフィカルインターフェースでオープンソースモデルをローカルで簡単に実行できます。開始するには:
+
+1. [ここをクリックしてLM Studioでモデルを開く](lmstudio://open_from_hf?model=unsloth/Devstral-Small-2505-GGUF)
+2. モデルがダウンロードされたら、「Local Server」タブに移動し、「Start Server」をクリック
+
+
+Ollamaを使用するには、[インストール](https://ollama.com/download)して、実行したいモデルを`ollama run`コマンドでダウンロードできます。
+
+例えば、[Devstral-Small](https://huggingface.co/unsloth/Devstral-Small-2505-GGUF?local-app=ollama)モデルをダウンロードして実行するには:
+
+```bash
+ollama run unsloth/devstral-small-2505-gguf:Q4_K_M
+```
+
+
+
+
+
+Continueは様々なローカルモデルプロバイダーをサポートしています。Ollama、Llama.cpp、LM Studio以外にも他のプロバイダーを使用できます。サポートされているプロバイダーの完全なリストと詳細な設定オプションについては、[Continueドキュメント](https://docs.continue.dev/customize/model-providers)をご参照ください。
+
+
+
+組み込み機能としてツール呼び出し機能を持つモデル、つまりCodestral QwenやLlama 3.1xを使用することが重要です。
+
+1. ワークスペースのトップレベルに`.continue/models`というフォルダを作成
+2. モデルプロバイダーを設定するためのファイルをこのフォルダに追加。例:`local-models.yaml`
+3. Ollama、Llama.cpp、LM Studioのどれを使用しているかに応じて、以下の設定を追加
+
+
+
+この設定は`llama-server`で提供される`llama.cpp`モデル用です。`model`フィールドは提供するモデルと一致させる必要があります。
+
+```yaml
+name: Llama.cpp model
+version: 0.0.1
+schema: v1
+models:
+ - provider: llama.cpp
+ model: unsloth/Devstral-Small-2505-GGUF
+ apiBase: http://localhost:8080
+ defaultCompletionOptions:
+ contextLength: 8192 # モデルに基づいて調整
+ name: Llama.cpp Devstral-Small
+ roles:
+ - chat
+ - edit
+```
+
+
+この設定はLM Studio経由で提供されるモデル用です。モデル識別子はLM Studioにロードされているものと一致させる必要があります。
+
+```yaml
+name: LM Studio Model
+version: 0.0.1
+schema: v1
+models:
+ - provider: lmstudio
+ model: unsloth/Devstral-Small-2505-GGUF
+ name: LM Studio Devstral-Small
+ apiBase: http://localhost:1234/v1
+ roles:
+ - chat
+ - edit
+```
+
+
+この設定はOllamaモデル用です。
+
+```yaml
+name: Ollama Devstral model
+version: 0.0.1
+schema: v1
+models:
+ - provider: ollama
+ model: unsloth/devstral-small-2505-gguf:Q4_K_M
+ defaultCompletionOptions:
+ contextLength: 8192
+ name: Ollama Devstral-Small
+ roles:
+ - chat
+ - edit
+```
+
+
+
+デフォルトでは、各モデルには最大コンテキスト長があり、この場合は`128000`トークンです。このセットアップには、複数のMCPリクエストを実行するためのより大きなコンテキストウィンドウの使用が含まれ、より多くのトークンを処理できる必要があります。
+
+## 動作の仕組み
+
+### ツールハンドシェイク
+
+ツールは、モデルが外部世界とインターフェースするための強力な方法を提供します。これらは名前と引数スキーマを持つJSONオブジェクトとしてモデルに提供されます。例えば、`filepath`引数を持つ`read_file`ツールは、モデルに特定のファイルの内容を要求する能力を与えます。
+
+
+
+以下のハンドシェイクは、エージェントがツールを使用する方法を説明しています:
+
+1. エージェントモードでは、使用可能なツールが`user`チャットリクエストと一緒に送信されます
+2. モデルは応答にツール呼び出しを含めることを選択できます
+3. ユーザーが許可を与えます。そのツールのポリシーが`Automatic`に設定されている場合、このステップはスキップされます
+4. Continueは組み込み機能またはその特定のツールを提供するMCPサーバーを使用してツールを呼び出します
+5. Continueは結果をモデルに送り返します
+6. モデルが応答し、場合によっては別のツール呼び出しを行い、ステップ2が再び始まります
+
+Continueは複数のローカルモデルプロバイダーをサポートしています。異なるタスクに異なるモデルを使用したり、必要に応じてモデルを切り替えたりできます。このセクションではローカルファーストソリューションに焦点を当てていますが、ContinueはOpenAI、Anthropic、Microsoft/Azure、Mistralなどの人気プロバイダーでも動作します。独自のモデルプロバイダーを実行することも可能です。
+
+### MCPとのローカルモデル統合
+
+すべてのセットアップが完了したので、既存のMCPサーバーを追加しましょう。以下は、アシスタントで使用する新しいMCPサーバーをセットアップする簡単な例です:
+
+1. ワークスペースのトップレベルに`.continue/mcpServers`というフォルダを作成
+2. このフォルダに`playwright-mcp.yaml`というファイルを追加
+3. `playwright-mcp.yaml`に以下の内容を書き込んで保存
+
+```yaml
+name: Playwright mcpServer
+version: 0.0.1
+schema: v1
+mcpServers:
+ - name: Browser search
+ command: npx
+ args:
+ - "@playwright/mcp@latest"
+```
+
+次のコマンドでMCPサーバーをテストしてください:
+
+```
+1. playwrightを使用して、https://news.ycombinator.com に移動してください。
+
+2. ホームページの上位4つの投稿のタイトルとURLを抽出してください。
+
+3. プロジェクトのルートディレクトリにhn.txtという名前のファイルを作成してください。
+
+4. このリストをhn.txtファイルにプレーンテキストとして保存してください。各行にはタイトルとURLをハイフンで区切って含めてください。
+
+コードや指示を出力せず、タスクを完了して完了時に確認してください。
+```
+
+結果として、現在の作業ディレクトリに`hn.txt`という生成されたファイルが作成されます。
+
+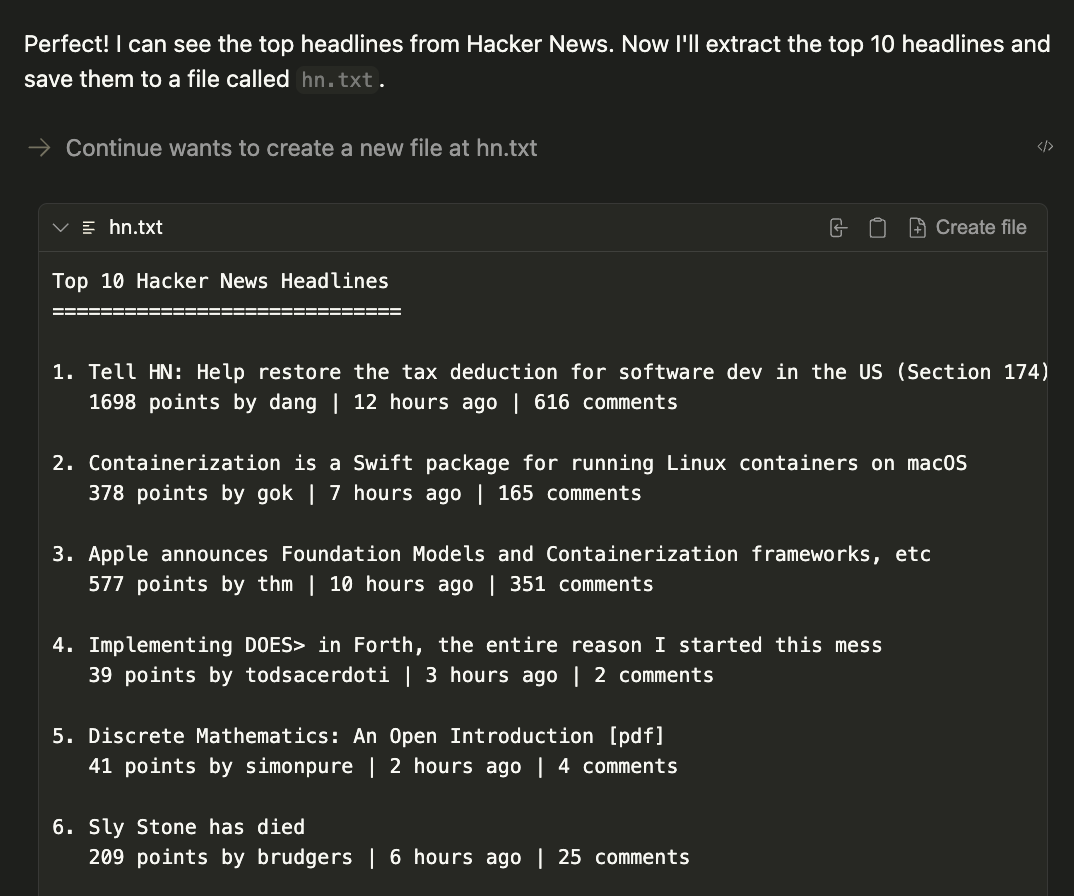
+
+## まとめ
+
+ContinueをLlama 3.1のようなローカルモデルやMCPサーバーと組み合わせることで、最先端のAI機能を活用しながら、コードとデータをプライベートに保つ強力な開発ワークフローを手に入れました。
+
+このセットアップにより、Web自動化からファイル管理まで、すべて完全にローカルマシンで実行される専門ツールでAIアシスタントをカスタマイズする柔軟性が得られます。開発ワークフローを次のレベルに引き上げる準備はできましたか?[Continue Hub MCP探索ページ](https://hub.continue.dev/explore/mcp)から異なるMCPサーバーを試してみることから始めて、ローカルAIがいかにコーディング体験を変革するかを発見してください。
\ No newline at end of file
diff --git a/units/ja/unit2/gradio-client.mdx b/units/ja/unit2/gradio-client.mdx
new file mode 100644
index 0000000..8108af2
--- /dev/null
+++ b/units/ja/unit2/gradio-client.mdx
@@ -0,0 +1,176 @@
+# MCPクライアントとしてのGradio
+
+前のセクションでは、Gradioを使用してMCPサーバーを作成し、MCPクライアントを使用してそれに接続する方法を探りました。このセクションでは、GradioをMCPクライアントとして使用してMCPサーバーに接続する方法を探ります。
+
+
+
+GradioはUIクライアントとMCPサーバーの作成に最も適していますが、MCPクライアントとして使用してそれをUIとして公開することも可能です。
+
+
+
+前のセクションで作成したものと類似したMCPサーバーに接続しますが、追加機能があり、それを使用して質問に答えます。
+
+## GradioでのMCPクライアント
+
+### サンプルMCPサーバーへの接続
+
+Hugging Faceで既に実行されているサンプルMCPサーバーに接続してみましょう。この例では[こちらのサーバー](https://huggingface.co/spaces/abidlabs/mcp-tool-http)を使用します。これはMCPツールのコレクションを含むスペースです。
+
+```python
+from smolagents.mcp_client import MCPClient
+
+with MCPClient(
+ {"url": "https://abidlabs-mcp-tool-http.hf.space/gradio_api/mcp/sse"}
+) as tools:
+ # リモートサーバーからのツールが利用可能
+ print("\n".join(f"{t.name}: {t.description}" for t in tools))
+
+```
+
+
+出力
+
+
+prime_factors: Compute the prime factorization of a positive integer.
+generate_cheetah_image: Generate a cheetah image.
+image_orientation: Returns whether image is portrait or landscape.
+sepia: Apply a sepia filter to the input image.
+
+
+
+
+### GradioからMCPサーバーへの接続
+
+素晴らしい、サンプルMCPサーバーに接続できました。次に、それをサンプルアプリケーションで使用する必要があります。
+
+まず、まだインストールしていない場合は、`smolagents`、Gradio、mcp-clientライブラリをインストールする必要があります:
+
+```bash
+pip install "smolagents[mcp]" "gradio[mcp]" mcp fastmcp
+```
+
+次に、必要なライブラリをインポートし、MCPクライアントを使用してMCPサーバーに接続するシンプルなGradioインターフェースを作成できます。
+
+```python
+import gradio as gr
+import os
+
+from mcp import StdioServerParameters
+from smolagents import InferenceClientModel, CodeAgent, ToolCollection, MCPClient
+```
+
+次に、MCPサーバーに接続し、質問に答えるために使用できるツールを取得します。
+
+```python
+mcp_client = MCPClient(
+ {"url": "https://abidlabs-mcp-tool-http.hf.space/gradio_api/mcp/sse"} # これは前のセクションで作成したMCPクライアントです
+)
+tools = mcp_client.get_tools()
+```
+
+ツールを取得したので、それらを使用して質問に答えるシンプルなエージェントを作成できます。今のところ、シンプルな`InferenceClientModel`と`smolagents`のデフォルトモデルを使用します。
+
+InferenceClientModelにapi_keyを渡すことが重要です。huggingfaceアカウントからトークンにアクセスできます。[こちらを確認してください。](https://huggingface.co/docs/hub/en/security-tokens)そして、環境変数`HF_TOKEN`でアクセストークンを設定してください。
+
+```python
+model = InferenceClientModel(token=os.getenv("HF_TOKEN"))
+agent = CodeAgent(tools=[*tools], model=model)
+```
+
+次に、エージェントを使用して質問に答えるシンプルなGradioインターフェースを作成できます。
+
+```python
+demo = gr.ChatInterface(
+ fn=lambda message, history: str(agent.run(message)),
+ type="messages",
+ examples=["68の素因数分解"],
+ title="MCPツールを使用したエージェント",
+ description="これはMCPツールを使用して質問に答えるシンプルなエージェントです。"
+)
+
+demo.launch()
+```
+
+それで完了です!MCPクライアントを使用してMCPサーバーに接続し、質問に答えるシンプルなGradioインターフェースを作成しました。
+
+
+
+## 完全な例
+
+以下は、GradioでのMCPクライアントの使用の完全な例です:
+
+```python
+import gradio as gr
+import os
+
+from smolagents import InferenceClientModel, CodeAgent, MCPClient
+
+
+try:
+ mcp_client = MCPClient(
+ {"url": "https://abidlabs-mcp-tool-http.hf.space/gradio_api/mcp/sse"}
+ )
+ tools = mcp_client.get_tools()
+
+ model = InferenceClientModel(token=os.getenv("HUGGINGFACE_API_TOKEN"))
+ agent = CodeAgent(tools=[*tools], model=model, additional_authorized_imports=["json", "ast", "urllib", "base64"])
+
+ demo = gr.ChatInterface(
+ fn=lambda message, history: str(agent.run(message)),
+ type="messages",
+ examples=["次のテキストの感情を分析してください 'This is awesome'"],
+ title="MCPツールを使用したエージェント",
+ description="これはMCPツールを使用して質問に答えるシンプルなエージェントです。",
+ )
+
+ demo.launch()
+finally:
+ mcp_client.disconnect()
+```
+
+`finally`ブロックでMCPクライアントを閉じていることに注意してください。これは、MCPクライアントがプログラム終了時に閉じる必要がある長寿命オブジェクトであるため重要です。
+
+## Hugging Face Spacesへのデプロイ
+
+前のセクションで行ったように、サーバーを他の人が利用できるようにするために、Hugging Face Spacesにデプロイできます。
+Gradio MCPクライアントをHugging Face Spacesにデプロイするには:
+
+1. Hugging Faceで新しいスペースを作成:
+ - huggingface.co/spacesに移動
+ - 「Create new Space」をクリック
+ - SDKとして「Gradio」を選択
+ - スペースに名前を付ける(例:「mcp-client」)
+
+2. コード内のMCPサーバーURLを更新:
+
+```python
+mcp_client = MCPClient(
+ {"url": "https://abidlabs-mcp-tool-http.hf.space/gradio_api/mcp/sse"}
+)
+```
+
+3. `requirements.txt`ファイルを作成:
+```txt
+gradio[mcp]
+smolagents[mcp]
+```
+
+4. コードをスペースにプッシュ:
+```bash
+git init
+git add app.py requirements.txt
+git commit -m "Initial commit"
+git remote add origin https://huggingface.co/spaces/YOUR_USERNAME/mcp-client
+git push -u origin main
+```
+
+注意:リモートオリジンを追加する際は、AccessTokenで追加するために[password-git-deprecation](https://huggingface.co/blog/password-git-deprecation)を参照してください。
+
+## まとめ
+
+このセクションでは、GradioをMCPクライアントとして使用してMCPサーバーに接続する方法を探りました。また、MCPクライアントをHugging Face Spacesにデプロイする方法も見ました。
\ No newline at end of file
diff --git a/units/ja/unit2/gradio-server.mdx b/units/ja/unit2/gradio-server.mdx
new file mode 100644
index 0000000..6819eb0
--- /dev/null
+++ b/units/ja/unit2/gradio-server.mdx
@@ -0,0 +1,193 @@
+# Gradio MCPサーバーの構築
+
+このセクションでは、Gradioを使用して感情分析MCPサーバーを作成します。このサーバーは、Webインターフェースを通じたユーザーとMCPプロトコルを通じたAIモデルの両方が使用できる感情分析ツールを公開します。
+
+## Gradio MCP統合の紹介
+
+Gradioは、Python関数をMCPツールに自動変換することでMCPサーバーを作成する簡単な方法を提供します。`launch()`で`mcp_server=True`を設定すると、Gradioは以下を実行します:
+
+1. 関数をMCPツールに自動変換
+2. 入力コンポーネントをツール引数スキーマにマッピング
+3. 出力コンポーネントからレスポンス形式を決定
+4. クライアント・サーバー通信用にHTTP+SSE上のJSON-RPCを設定
+5. WebインターフェースとMCPサーバーエンドポイントの両方を作成
+
+## プロジェクトのセットアップ
+
+まず、プロジェクト用の新しいディレクトリを作成し、必要な依存関係をセットアップしましょう:
+
+```bash
+mkdir mcp-sentiment
+cd mcp-sentiment
+python -m venv venv
+source venv/bin/activate # Windowsの場合: venv\Scripts\activate
+pip install "gradio[mcp]" textblob
+```
+
+## サーバーの作成
+
+> Hugging face spacesはスペースを構築するためにapp.pyファイルが必要です。そのため、Pythonファイルの名前はapp.pyでなければなりません。
+
+以下のコードで`app.py`という新しいファイルを作成してください:
+
+```python
+import json
+import gradio as gr
+from textblob import TextBlob
+
+def sentiment_analysis(text: str) -> str:
+ """
+ 与えられたテキストの感情を分析します。
+
+ Args:
+ text (str): 分析するテキスト
+
+ Returns:
+ str: 極性、主観性、評価を含むJSON文字列
+ """
+ blob = TextBlob(text)
+ sentiment = blob.sentiment
+
+ result = {
+ "polarity": round(sentiment.polarity, 2), # -1 (ネガティブ) から 1 (ポジティブ)
+ "subjectivity": round(sentiment.subjectivity, 2), # 0 (客観的) から 1 (主観的)
+ "assessment": "positive" if sentiment.polarity > 0 else "negative" if sentiment.polarity < 0 else "neutral"
+ }
+
+ return json.dumps(result)
+
+# Gradioインターフェースを作成
+demo = gr.Interface(
+ fn=sentiment_analysis,
+ inputs=gr.Textbox(placeholder="分析するテキストを入力..."),
+ outputs=gr.Textbox(), # gr.JSON()からgr.Textbox()に変更
+ title="テキスト感情分析",
+ description="TextBlobを使用してテキストの感情を分析します"
+)
+
+# インターフェースとMCPサーバーを起動
+if __name__ == "__main__":
+ demo.launch(mcp_server=True)
+```
+
+## コードの理解
+
+主要なコンポーネントを分解してみましょう:
+
+1. **関数定義**:
+ - `sentiment_analysis`関数はテキスト入力を受け取り、辞書を返します
+ - TextBlobを使用して感情を分析します
+ - docstringはGradioがMCPツールスキーマを生成するために重要です
+ - 型ヒント(`str`と`dict`)は入出力スキーマを定義するのに役立ちます
+
+2. **Gradioインターフェース**:
+ - `gr.Interface`はWeb UIとMCPサーバーの両方を作成します
+ - 関数は自動的にMCPツールとして公開されます
+ - 入力と出力コンポーネントがツールのスキーマを定義します
+ - JSON出力コンポーネントは適切なシリアライゼーションを保証します
+
+3. **MCPサーバー**:
+ - `mcp_server=True`を設定するとMCPサーバーが有効になります
+ - サーバーは`http://localhost:7860/gradio_api/mcp/sse`で利用可能になります
+ - 環境変数を使用して有効にすることもできます:
+ ```bash
+ export GRADIO_MCP_SERVER=True
+ ```
+
+## サーバーの実行
+
+以下を実行してサーバーを起動します:
+
+```bash
+python app.py
+```
+
+WebインターフェースとMCPサーバーの両方が実行されていることを示す出力が表示されるはずです。Webインターフェースは`http://localhost:7860`で、MCPサーバーは`http://localhost:7860/gradio_api/mcp/sse`で利用可能です。
+
+## サーバーのテスト
+
+サーバーは2つの方法でテストできます:
+
+1. **Webインターフェース**:
+ - ブラウザで`http://localhost:7860`を開きます
+ - テキストを入力し、"送信"をクリックします
+ - 感情分析結果が表示されるはずです
+
+2. **MCPスキーマ**:
+ - `http://localhost:7860/gradio_api/mcp/schema`を訪問します
+ - これはクライアントが使用するMCPツールスキーマを表示します
+ - Gradioアプリのフッターにある"View API"リンクでもこれを見つけることができます
+
+## トラブルシューティングティップス
+
+1. **型ヒントとDocstring**:
+ - 関数パラメーターと戻り値に必ず型ヒントを提供してください
+ - 各パラメーターに対して"Args:"ブロックを含むdocstringを含めてください
+ - これはGradioが正確なMCPツールスキーマを生成するのに役立ちます
+
+2. **文字列入力**:
+ - 迷ったときは、入力引数を`str`として受け入れてください
+ - 関数内で目的の型に変換してください
+ - これはMCPクライアントとの互換性を向上させます
+
+3. **SSEサポート**:
+ - 一部のMCPクライアントはSSEベースのMCPサーバーをサポートしていません
+ - その場合、`mcp-remote`を使用してください:
+ ```json
+ {
+ "mcpServers": {
+ "gradio": {
+ "command": "npx",
+ "args": [
+ "mcp-remote",
+ "http://localhost:7860/gradio_api/mcp/sse"
+ ]
+ }
+ }
+ }
+ ```
+
+4. **接続問題**:
+ - 接続問題が発生した場合、クライアントとサーバーの両方を再起動してみてください
+ - サーバーが実行され、アクセス可能であることを確認してください
+ - MCPスキーマが期待されるURLで利用可能であることを確認してください
+
+## Hugging Face Spacesへのデプロイ
+
+サーバーを他の人が利用できるようにするために、Hugging Face Spacesにデプロイできます:
+
+1. Hugging Faceで新しいSpaceを作成します:
+ - huggingface.co/spacesにアクセスします
+ - "Create new Space"をクリックします
+ - SDKとして"Gradio"を選択します
+ - スペースに名前を付けます(例:"mcp-sentiment")
+
+2. `requirements.txt`ファイルを作成します:
+```txt
+gradio[mcp]
+textblob
+```
+
+3. コードをSpaceにプッシュします:
+```bash
+git init
+git add app.py requirements.txt
+git commit -m "Initial commit"
+git remote add origin https://huggingface.co/spaces/YOUR_USERNAME/mcp-sentiment
+git push -u origin main
+```
+
+MCPサーバーは以下で利用可能になります:
+```
+https://YOUR_USERNAME-mcp-sentiment.hf.space/gradio_api/mcp/sse
+```
+
+## 次のステップ
+
+MCPサーバーが実行されたので、それとインタラクトするクライアントを作成します。次のセクションでは、以下を行います:
+
+1. Tiny AgentsにインスパイアされたHuggingFace.jsベースのクライアントを作成
+2. SmolAgentsベースのPythonクライアントを実装
+3. デプロイされたサーバーで両方のクライアントをテスト
+
+最初のクライアントの構築に移りましょう!
diff --git a/units/ja/unit2/introduction.mdx b/units/ja/unit2/introduction.mdx
new file mode 100644
index 0000000..de6a74e
--- /dev/null
+++ b/units/ja/unit2/introduction.mdx
@@ -0,0 +1,64 @@
+# エンドツーエンドMCPアプリケーションの構築
+
+MCPコースのユニット2へようこそ!
+
+このユニットでは、完全なMCPアプリケーションをゼロから構築し、Gradioを使用したサーバーの作成と複数のクライアントとの接続に焦点を当てます。このハンズオンアプローチにより、MCPエコシステム全体の実践的な経験を積むことができます。
+
+
+
+このユニットでは、GradioとHuggingFace hubを使用してシンプルなMCPサーバーとクライアントを構築します。次のユニットでは、実際のユースケースに取り組むより複雑なサーバーを構築します。
+
+
+
+## 学習内容
+
+このユニットでは、以下のことを学びます:
+
+- Gradioの組み込みMCPサポートを使用したMCPサーバーの作成
+- AIモデルで使用できる感情分析ツールの構築
+- 異なるクライアント実装を使用したサーバーへの接続:
+ - HuggingFace.jsベースのクライアント
+ - PythonのSmolAgentsベースのクライアント
+- MCPサーバーのHugging Face Spacesへのデプロイ
+- 完全なシステムのテストとデバッグ
+
+このユニットの終わりには、プロトコルの力と柔軟性を実証する動作するMCPアプリケーションを手にすることになります。
+
+## 前提条件
+
+このユニットを進める前に、以下を確認してください:
+
+- ユニット1を完了しているか、MCPの概念の基本的な理解がある
+- PythonとJavaScript/TypeScriptの両方に慣れている
+- APIとクライアント・サーバーアーキテクチャの基本的な理解がある
+- 開発環境を持っている:
+ - Python 3.10+
+ - Node.js 18+
+ - Hugging Faceアカウント(デプロイ用)
+
+## エンドツーエンドプロジェクト
+
+サーバー、クライアント、デプロイメントの3つの主要部分からなる感情分析アプリケーションを構築します。
+
+
+
+### サーバー側
+
+- Gradioを使用して`gr.Interface`経由でWebインターフェースとMCPサーバーを作成
+- TextBlobを使用した感情分析ツールの実装
+- HTTPとMCPプロトコルの両方を通じたツールの公開
+
+### クライアント側
+
+- HuggingFace.jsクライアントの実装
+- または、smolagents Pythonクライアントの作成
+- 異なるクライアント実装で同じサーバーを使用する方法の実証
+
+### デプロイメント
+
+- サーバーのHugging Face Spacesへのデプロイ
+- デプロイされたサーバーと連携するためのクライアントの設定
+
+## 始めましょう!
+
+初めてのエンドツーエンドMCPアプリケーションを構築する準備はできましたか?開発環境の設定とGradio MCPサーバーの作成から始めましょう。
\ No newline at end of file
diff --git a/units/ja/unit2/tiny-agents.mdx b/units/ja/unit2/tiny-agents.mdx
new file mode 100644
index 0000000..f175d19
--- /dev/null
+++ b/units/ja/unit2/tiny-agents.mdx
@@ -0,0 +1,271 @@
+# MCPとHugging Face HubでTiny Agentsを構築
+
+これまでGradioでMCPサーバーを構築し、MCPクライアントの作成について学んできました。今度は、感情分析ツールとシームレスに相互作用できるエージェントを構築して、エンドツーエンドアプリケーションを完成させましょう。このセクションは、[Tiny Agents](https://huggingface.co/blog/tiny-agents)プロジェクトをベースにしており、Gradio感情分析サーバーのようなサービスに接続できるMCPクライアントをデプロイする超シンプルな方法を実証しています。
+
+このユニット2の最終演習では、前のセクションで構築したGradioベースの感情分析サーバーを含む、あらゆるMCPサーバーと通信できるTypeScript(JS)とPythonの両方のMCPクライアントを実装する方法をご案内します。これにより、感情分析ツールを公開するGradio MCPサーバーの構築から、他の機能と組み合わせてこのツールを使用できる柔軟なエージェントの作成まで、エンドツーエンドMCPアプリケーションフローが完成します。
+
+
+画像クレジット https://x.com/adamdotdev
+
+## インストール
+
+Tiny Agentsを構築するために必要なパッケージをインストールしましょう。
+
+
+
+Claude Desktopなど、一部のMCPクライアントはまだSSEベースのMCPサーバーをサポートしていません。その場合、[mcp-remote](https://github.com/geelen/mcp-remote)のようなツールを使用できます。まずNode.jsをインストールしてください。次に、独自のMCPクライアント設定に以下を追加してください:
+
+
+
+Tiny Agentはコマンドライン環境でMCPサーバーを実行できます。これを行うには、`npm`をインストールし、`npx`でサーバーを実行する必要があります。**PythonとJavaScriptの両方でこれらが必要です。**
+
+`npm`で`npx`をインストールしましょう。`npm`がインストールされていない場合は、[npmドキュメント](https://docs.npmjs.com/downloading-and-installing-node-js-and-npm)を確認してください。
+
+```bash
+# npxをインストール
+npm install -g npx
+```
+
+次に、`mcp-remote`パッケージをインストールする必要があります。
+
+```bash
+npm i mcp-remote
+```
+
+
+
+
+JavaScriptの場合、`tiny-agents`パッケージをインストールする必要があります。
+
+```bash
+npm install @huggingface/tiny-agents
+```
+
+
+
+
+Pythonの場合、必要なコンポーネントをすべて取得するために、`mcp`エクストラ付きの最新バージョンの`huggingface_hub`をインストールする必要があります。
+
+```bash
+pip install "huggingface_hub[mcp]>=0.32.0"
+```
+
+
+
+
+## コマンドラインでのTiny Agents MCPクライアント
+
+基本的なTiny Agentを作成するために、[ユニット1](../unit1/mcp-clients.mdx)の例を繰り返しましょう。Tiny AgentsはJSON設定ファイルに基づいてコマンドラインからMCPクライアントを作成できます。
+
+
+
+
+基本的なTiny Agentでプロジェクトをセットアップしましょう。
+
+```bash
+mkdir my-agent
+touch my-agent/agent.json
+```
+
+JSONファイルは次のようになります:
+
+```json
+{
+ "model": "Qwen/Qwen2.5-72B-Instruct",
+ "provider": "nebius",
+ "servers": [
+ {
+ "type": "stdio",
+ "config": {
+ "command": "npx",
+ "args": [
+ "mcp-remote",
+ "http://localhost:7860/gradio_api/mcp/sse" // これは前のセクションで作成したMCPサーバーです
+ ]
+ }
+ }
+ ]
+}
+```
+
+次のコマンドでエージェントを実行できます:
+
+```bash
+npx @huggingface/tiny-agents run ./my-agent
+```
+
+
+
+
+基本的なTiny Agentでプロジェクトをセットアップしましょう。
+
+```bash
+mkdir my-agent
+touch my-agent/agent.json
+cd my-agent
+```
+
+JSONファイルは次のようになります:
+
+```json
+{
+ "model": "Qwen/Qwen2.5-72B-Instruct",
+ "provider": "nebius",
+ "servers": [
+ {
+ "type": "stdio",
+ "config": {
+ "command": "npx",
+ "args": [
+ "mcp-remote",
+ "http://localhost:7860/gradio_api/mcp/sse"
+ ]
+ }
+ }
+ ]
+}
+```
+
+次のコマンドでエージェントを実行できます:
+
+```bash
+tiny-agents run agent.json
+```
+
+
+
+
+ここで、Gradio MCPサーバーに接続できる基本的なTiny Agentができました。これには、モデル、プロバイダー、サーバー設定が含まれています。
+
+| フィールド | 説明 |
+|-------|-------------|
+| `model` | エージェントに使用するオープンソースモデル |
+| `provider` | エージェントに使用する推論プロバイダー |
+| `servers` | エージェントに使用するサーバー。Gradio MCPサーバー用に`mcp-remote`サーバーを使用します。 |
+
+
+
+Tiny Agentsでローカルで実行されているオープンソースモデルを使用することもできます。ローカル推論サーバーを起動する場合は
+
+```json
+{
+ "model": "Qwen/Qwen3-32B",
+ "endpointUrl": "http://localhost:1234/v1",
+ "servers": [
+ {
+ "type": "stdio",
+ "config": {
+ "command": "npx",
+ "args": [
+ "mcp-remote",
+ "http://localhost:1234/v1/mcp/sse"
+ ]
+ }
+ }
+ ]
+}
+```
+
+ここで、ローカルモデルに接続できるTiny Agentができました。これには、モデル、エンドポイントURL(`http://localhost:1234/v1`)、サーバー設定が含まれています。エンドポイントはOpenAI互換のエンドポイントである必要があります。
+
+
+
+## カスタムTiny Agents MCPクライアント
+
+Tiny AgentsとGradio MCPサーバーの両方を理解したので、それらがどのように連携するかを見てみましょう!MCPの美しさは、前のセクションのGradioベースの感情分析サーバーを含む、あらゆるMCP互換サーバーとエージェントが相互作用するための標準化された方法を提供することです。
+
+### Tiny AgentsでGradioサーバーを使用
+
+このユニットで前に構築したGradio感情分析サーバーにTiny Agentを接続するには、サーバーのリストに追加するだけです。エージェント設定を変更する方法は次のとおりです:
+
+
+
+
+```ts
+const agent = new Agent({
+ provider: process.env.PROVIDER ?? "nebius",
+ model: process.env.MODEL_ID ?? "Qwen/Qwen2.5-72B-Instruct",
+ apiKey: process.env.HF_TOKEN,
+ servers: [
+ // ... 既存のサーバー ...
+ {
+ command: "npx",
+ args: [
+ "mcp-remote",
+ "http://localhost:7860/gradio_api/mcp/sse" // あなたのGradio MCPサーバー
+ ]
+ }
+ ],
+});
+```
+
+
+
+
+```python
+import os
+
+from huggingface_hub import Agent
+
+agent = Agent(
+ model="Qwen/Qwen2.5-72B-Instruct",
+ provider="nebius",
+ servers=[
+ {
+ "command": "npx",
+ "args": [
+ "mcp-remote",
+ "http://localhost:7860/gradio_api/mcp/sse" # あなたのGradio MCPサーバー
+ ]
+ }
+ ],
+)
+```
+
+
+
+
+これで、エージェントは他のツールと組み合わせて感情分析ツールを使用できます!例えば、以下のことができます:
+1. ファイルシステムサーバーを使用してファイルからテキストを読み取る
+2. Gradioサーバーを使用してその感情を分析する
+3. 結果をファイルに書き戻す
+
+### デプロイメントの考慮事項
+
+Gradio MCPサーバーをHugging Face Spacesにデプロイする場合、デプロイされたスペースを指すようにエージェント設定のサーバーURLを更新する必要があります:
+
+```json
+{
+ command: "npx",
+ args: [
+ "mcp-remote",
+ "https://YOUR_USERNAME-mcp-sentiment.hf.space/gradio_api/mcp/sse"
+ ]
+}
+```
+
+これにより、エージェントはローカルだけでなく、どこからでも感情分析ツールを使用できます!
+
+## まとめ:完全なエンドツーエンドMCPアプリケーション
+
+このユニットでは、MCPの基本理解から完全なエンドツーエンドアプリケーションの構築まで進んできました:
+
+1. 感情分析ツールを公開するGradio MCPサーバーを作成しました
+2. MCPクライアントを使用してこのサーバーに接続する方法を学びました
+3. ツールと相互作用できるTypeScriptとPythonの小さなエージェントを構築しました
+
+これは、Model Context Protocolの力を実証しています - 慣れ親しんだフレームワーク(Gradioなど)を使用して専門ツールを作成し、標準化されたインターフェース(MCP)を通じてそれらを公開し、エージェントがこれらのツールを他の機能と組み合わせてシームレスに使用できます。
+
+構築した完全なフローにより、エージェントは以下のことができます:
+- 複数のツールプロバイダーに接続
+- 利用可能なツールを動的に発見
+- カスタム感情分析ツールを使用
+- ファイルシステムアクセスやWebブラウジングなどの他の機能と組み合わせる
+
+このモジュラーアプローチが、柔軟なAIアプリケーションを構築するためのMCPの強力さの源です。
+
+## 次のステップ
+
+- [Python](https://huggingface.co/blog/python-tiny-agents)と[TypeScript](https://huggingface.co/blog/tiny-agents)のTiny Agentsブログ投稿をチェック
+- [Tiny Agentsドキュメント](https://huggingface.co/docs/huggingface.js/main/en/tiny-agents/README)を確認
+- Tiny Agentsで何かを構築しましょう!
\ No newline at end of file
diff --git a/units/ja/unit3/build-mcp-server-solution-walkthrough.mdx b/units/ja/unit3/build-mcp-server-solution-walkthrough.mdx
new file mode 100644
index 0000000..00ec5e5
--- /dev/null
+++ b/units/ja/unit3/build-mcp-server-solution-walkthrough.mdx
@@ -0,0 +1,444 @@
+# Unit 3 解決方法ウォークスルー: MCPでプルリクエストエージェントを構築する
+
+## 概要
+
+このウォークスルーでは、Unit 3のプルリクエストエージェントの完全な解決方法を説明します。これは、コードの変更を分析し、CI/CDパイプラインを監視し、チームコミュニケーションを自動化することで、開発者がより良いプルリクエストを作成できるようにするMCPサーバーです。この解決方法では、MCPの3つのプリミティブ(Tools、Resources、Prompts)が実際のワークフローで連携して動作することを実演します。
+
+## アーキテクチャ概要
+
+PRエージェントは、完全な自動化システムを段階的に構築する相互接続されたモジュールで構成されています:
+
+1. **Build MCP Server** - PRテンプレート提案用のToolsを含む基本サーバー
+2. **Smart File Analysis** - プロジェクトコンテキスト用のResourcesを使用した拡張分析
+3. **GitHub Actions Integration** - 標準化されたPromptsを使用したCI/CD監視
+4. **Hugging Face Hub Integration** - モデルデプロイメントとデータセットPRワークフロー
+5. **Slack Notification** - すべてのMCPプリミティブを統合したチームコミュニケーション
+
+## モジュール1: Build MCP Server
+
+### 構築するもの
+MCPツールを使用してファイルの変更を分析し、適切なPRテンプレートを提案する最小限のMCPサーバー。
+
+### 主要コンポーネント
+
+#### 1. サーバー初期化 (`server.py`)
+```python
+# サーバーは3つの重要なツールを登録します:
+# - analyze_file_changes: 変更されたファイルに関する構造化データを返す
+# - get_pr_templates: メタデータ付きの利用可能なテンプレートをリストする
+# - suggest_template: インテリジェントなテンプレート推奨を提供する
+```
+
+サーバーはMCP SDKを使用してこれらのツールをClaude Codeに公開し、情報を収集して使用するPRテンプレートについて賢明な決定を下すことができます。
+
+#### 2. ファイル分析ツール
+`analyze_file_changes`ツールはgit diffを検査して以下を特定します:
+- ファイルタイプと拡張子
+- 変更されたファイル数
+- 追加/削除された行数
+- 一般的なパターン(テスト、設定、ドキュメント)
+
+この構造化データにより、Claudeは決定ロジックをハードコーディングすることなく変更の性質を理解できます。
+
+#### 3. テンプレート管理
+テンプレートは`templates/`ディレクトリにmarkdownファイルとして保存されます:
+- `bug.md` - バグ修正用
+- `feature.md` - 新機能用
+- `docs.md` - ドキュメント更新用
+- `refactor.md` - コードリファクタリング用
+
+各テンプレートには、Claudeが分析に基づいて入力できるプレースホルダーが含まれています。
+
+### Claudeがこれらのツールを使用する方法
+
+1. Claudeは`analyze_file_changes`を呼び出して何が変更されたかを理解します
+2. `get_pr_templates`を使用して利用可能なオプションを確認します
+3. 分析データを使用して`suggest_template`を呼び出します
+4. 理由付きの推奨を受け取ります
+5. 特定の変更に基づいてテンプレートをカスタマイズできます
+
+### 学習成果
+- ツール登録とスキーマの理解
+- 構造化データを使用してClaudeに決定を委ねる
+- データ収集と決定ロジックの分離
+
+## モジュール2: Smart File Analysis
+
+### 構築するもの
+MCPリソースを使用してプロジェクトコンテキストとチームガイドラインを提供する拡張ファイル分析。
+
+### 主要コンポーネント
+
+#### 1. リソース登録
+サーバーは4つのタイプのリソースを公開します:
+```python
+# リソースは以下への読み取り専用アクセスを提供します:
+# - file://templates/ - PRテンプレートファイル
+# - file://project-context/ - コーディング標準、規約
+# - git://recent-changes/ - コミット履歴とパターン
+# - team://guidelines/ - レビュープロセスと標準
+```
+
+#### 2. プロジェクトコンテキストリソース
+`project-context/`ディレクトリには以下が含まれます:
+- `coding-standards.md` - 言語固有の規約
+- `review-guidelines.md` - レビュアーが確認する項目
+- `architecture.md` - システム設計パターン
+- `dependencies.md` - サードパーティライブラリポリシー
+
+Claudeはこれらを読み取ってプロジェクト固有の要件を理解できます。
+
+#### 3. Git履歴分析
+`git://recent-changes/`リソースは以下を提供します:
+- 最近のコミットメッセージとパターン
+- 一般的なPRタイトルと説明
+- チームメンバーの貢献パターン
+- 履歴的なテンプレート使用状況
+
+これにより、Claudeはチームの慣行と一致するテンプレートを提案できます。
+
+### Claudeがリソースを使用する方法
+
+1. `team://guidelines/review-process.md`を読み取ってPR要件を理解します
+2. `file://project-context/coding-standards.md`にアクセスしてスタイルガイドを取得します
+3. `git://recent-changes/`を分析してチームパターンと一致させます
+4. このコンテキストをファイル分析と組み合わせて、より良い提案を行います
+
+### 拡張された意思決定
+リソースにより、Claudeは以下のことができるようになります:
+- チーム規約と一致するテンプレートを提案する
+- PRにプロジェクト固有の要件を含める
+- 説明でコーディング標準を参照する
+- 履歴的なチーム慣行と整合させる
+
+### 学習成果
+- リソースURIの設計とスキーマ
+- プロジェクト知識をAIにアクセス可能にする
+- コンテキストを意識した意思決定
+- 自動化とチーム標準のバランス
+
+## モジュール3: GitHub Actions Integration
+
+### 構築するもの
+webhookと一貫したチームコミュニケーションのための標準化されたプロンプトを使用したリアルタイムCI/CD監視。
+
+### 主要コンポーネント
+
+#### 1. Webhookサーバー
+Cloudflare TunnelでGitHub Actionsイベントを受信します:
+```python
+# Webhookエンドポイントは以下を処理します:
+# - workflow_runイベント
+# - check_runイベント
+# - pull_requestステータス更新
+# - デプロイメント通知
+```
+
+#### 2. プロンプトテンプレート
+4つの標準化されたプロンプトが一貫性を保証します:
+- **"Analyze CI Results"** - テスト失敗とビルドエラーを処理
+- **"Generate Status Summary"** - 人間が読みやすいステータス更新を作成
+- **"Create Follow-up Tasks"** - 結果に基づいて次のステップを提案
+- **"Draft Team Notification"** - 異なる対象者向けの更新をフォーマット
+
+#### 3. イベント処理パイプライン
+1. GitHubからwebhookを受信
+2. イベントデータを解析し、関連情報を抽出
+3. イベントタイプに基づいて適切なプロンプトを使用
+4. 標準化されたレスポンスを生成
+5. チーム通知のために保存
+
+### Claudeがプロンプトを使用する方法
+
+プロンプト使用例:
+```python
+# テストが失敗した場合、Claudeは"Analyze CI Results"プロンプトを使用します:
+prompt_data = {
+ "event_type": "workflow_run",
+ "status": "failure",
+ "failed_jobs": ["unit-tests", "lint"],
+ "error_logs": "...",
+ "pr_context": {...}
+}
+
+# Claudeが生成するもの:
+# - 根本原因分析
+# - 提案修正
+# - 影響評価
+# - 次のステップ
+```
+
+### 標準化されたワークフロー
+プロンプトは、誰が作業していても以下を保証します:
+- CI失敗が一貫して分析される
+- ステータス更新がチーム形式に従う
+- フォローアップアクションがプロセスと整合する
+- 通知が必要な情報を含む
+
+### 学習成果
+- Webhook統合パターン
+- 一貫性のためのプロンプトエンジニアリング
+- イベント駆動アーキテクチャ
+- チームワークフローの標準化
+
+## モジュール4: Hugging Face Hub Integration
+
+### 構築するもの
+LLMとデータセットPR用のHugging Face Hub統合、言語モデルを扱うチーム向けの専用ワークフローを追加。
+
+### 主要コンポーネント
+
+#### 1. Hub固有のツール
+```python
+# Hugging Faceワークフロー用のツール:
+# - analyze_model_changes: LLMファイル変更を検出
+# - validate_dataset_format: 訓練データコンプライアンスをチェック
+# - generate_model_card: モデルドキュメンテーションを作成/更新
+# - suggest_hub_template: LLM/データセット用PRテンプレート
+```
+
+#### 2. Hubリソース
+```python
+# Hubコンテキスト用のリソース:
+# - hub://model-cards/ - LLMカードテンプレートと例
+# - hub://dataset-formats/ - 訓練データ仕様
+# - hub://community-standards/ - Hubコミュニティガイドライン
+# - hub://license-info/ - ライセンス互換性チェック
+```
+
+#### 3. LLM固有のプロンプト
+```python
+# LLMワークフロー用のプロンプト:
+# - "Analyze Model Changes" - LLM更新を理解
+# - "Generate Benchmark Summary" - 評価メトリクスを作成
+# - "Check Dataset Quality" - 訓練データを検証
+# - "Draft Model Card Update" - ドキュメンテーションを更新
+```
+
+### Hub固有のワークフロー
+
+PRがLLMファイルを変更する場合:
+1. **ツール**: `analyze_model_changes`がモデルアーキテクチャの変更を検出
+2. **リソース**: `hub://model-cards/llm-template.md`を読み取り
+3. **プロンプト**: "Generate Benchmark Summary"が評価セクションを作成
+4. **ツール**: `generate_model_card`がドキュメンテーションを更新
+5. **リソース**: `hub://license-info/`で互換性をチェック
+
+### データセットPR処理
+訓練データ更新の場合:
+- 形式の一貫性を検証
+- データ品質メトリクスをチェック
+- データセットカードを更新
+- 適切なレビュアーを提案
+
+### 学習成果
+- Hugging Face Hub API統合
+- LLM固有のPRワークフロー
+- モデルとデータセットドキュメンテーション
+- コミュニティ標準準拠
+
+## モジュール5: Slack Notification
+
+### 構築するもの
+完全なワークフロー自動化のためにTools、Resources、Promptsを組み合わせた自動チーム通知。
+
+### 主要コンポーネント
+
+#### 1. コミュニケーションツール
+```python
+# チーム更新用の3つのツール:
+# - send_slack_message: チームチャンネルに投稿
+# - get_team_members: 通知対象者を特定
+# - track_notification_status: 配信を監視
+```
+
+#### 2. チームリソース
+```python
+# チームデータ用のリソース:
+# - team://members/ - 開発者プロフィールと設定
+# - slack://channels/ - チャンネル設定
+# - notification://templates/ - メッセージ形式
+```
+
+#### 3. 通知プロンプト
+```python
+# コミュニケーション用のプロンプト:
+# - "Format Team Update" - メッセージを適切にスタイル
+# - "Choose Communication Channel" - 適切な対象者を選択
+# - "Escalate if Critical" - 緊急問題を処理
+```
+
+### 統合例
+
+重要なPRでCIが失敗した場合:
+1. **ツール**: `get_team_members`がPR作成者とレビュアーを特定
+2. **リソース**: `team://members/{user}/preferences`が通知設定をチェック
+3. **プロンプト**: "Format Team Update"が適切なメッセージを作成
+4. **ツール**: `send_slack_message`が適切なチャンネルに配信
+5. **リソース**: `notification://templates/ci-failure`が一貫した形式を保証
+6. **プロンプト**: "Escalate if Critical"が追加アラートが必要かを判断
+
+### インテリジェントルーティング
+システムは以下を考慮します:
+- チームメンバーの空き状況(カレンダーリソースから)
+- 通知設定(メール vs Slack)
+- メッセージの緊急度(PRラベルに基づく)
+- タイムゾーンと勤務時間
+
+### 学習成果
+- プリミティブ統合パターン
+- 複雑なワークフローオーケストレーション
+- 自動化と人間のニーズのバランス
+- 本番環境対応のエラー処理
+
+## 完全なワークフロー例
+
+典型的なPRでのすべてのコンポーネントの連携方法:
+
+1. **開発者がPRを作成**
+ - GitHub webhookがサーバーをトリガー
+ - ツール: `analyze_file_changes`がdiffを調査
+ - リソース: チームガイドラインとプロジェクトコンテキストを読み取り
+ - プロンプト: 最適なPRテンプレートを提案
+
+2. **CI/CDパイプライン実行**
+ - Webhookがワークフローイベントを受信
+ - プロンプト: "Analyze CI Results"が結果を処理
+ - リソース: チームエスカレーションポリシーをチェック
+ - ツール: GitHubでPRステータスを更新
+
+3. **Hugging Face Hub統合**
+ - ツール: LLM/データセット変更を検出
+ - リソース: Hubガイドラインを読み取り
+ - プロンプト: モデルカード更新を生成
+ - ツール: Hub標準に対して検証
+
+4. **チーム通知**
+ - ツール: 関連チームメンバーを特定
+ - リソース: 通知設定を読み取り
+ - プロンプト: 適切なメッセージをフォーマット
+ - ツール: Slackチャンネル経由で送信
+
+5. **フォローアップアクション**
+ - プロンプト: "Create Follow-up Tasks"が次のステップを生成
+ - ツール: 必要に応じてGitHub issueを作成
+ - リソース: ドキュメンテーションにリンク
+ - すべてのプリミティブがシームレスに連携
+
+## テスト戦略
+
+### 単体テスト
+各モジュールには包括的な単体テストが含まれます:
+- ツールスキーマ検証
+- リソースURI解析
+- プロンプトテンプレートレンダリング
+- 統合シナリオ
+
+### 統合テスト
+エンドツーエンドテストのカバー範囲:
+- 完全なPRワークフロー
+- エラー回復シナリオ
+- 負荷下でのパフォーマンス
+- セキュリティ検証
+
+### テスト構造
+```
+tests/
+├── unit/
+│ ├── test_tools.py
+│ ├── test_resources.py
+│ ├── test_prompts.py
+│ └── test_integration.py
+├── integration/
+│ ├── test_workflow.py
+│ ├── test_webhooks.py
+│ └── test_notifications.py
+└── fixtures/
+ ├── sample_events.json
+ └── mock_responses.json
+```
+
+## 解決方法の実行
+
+### ローカル開発環境設定
+1. **MCPサーバーを開始**: `python server.py`
+2. **Claude Codeを設定**: サーバーをMCP設定に追加
+3. **Cloudflare Tunnelを設定**: `cloudflared tunnel --url http://localhost:3000`
+4. **Webhookを設定**: GitHubリポジトリにトンネルURLを追加
+5. **ワークフローをテスト**: PRを作成して自動化を確認
+
+### 設定
+簡単なセットアップのためのファイルベース設定:
+- `.env`ファイルのGitHubトークン
+- 設定のSlack webhook
+- `templates/`のテンプレートカスタマイゼーション
+- すべての設定を1箇所に
+
+## 一般的なパターンとベストプラクティス
+
+### ツール設計
+- ツールを集中的で単一目的に保つ
+- AI解釈のための構造化データを返す
+- 包括的なエラーメッセージを含める
+- ツールスキーマにバージョンを付ける
+
+### リソース整理
+- 明確なURI階層を使用
+- リソース発見を実装
+- 頻繁にアクセスされるリソースをキャッシュ
+- すべてのリソースをバージョン管理
+
+### プロンプトエンジニアリング
+- プロンプトを具体的だが柔軟にする
+- コンテキストと例を含める
+- 様々な入力でテスト
+- プロンプトライブラリを維持
+
+### 統合パターン
+- 疎結合のためのイベントを使用
+- サーキットブレーカーを実装
+- バックオフ付きリトライを追加
+- すべての外部呼び出しを監視
+
+## トラブルシューティングガイド
+
+### 一般的な問題
+
+1. **Webhookがイベントを受信しない**
+ - Cloudflare Tunnelが実行中かチェック
+ - GitHub webhook設定を確認
+ - シークレットが一致することを確認
+
+2. **ツールがClaudeに表示されない**
+ - ツールスキーマを検証
+ - サーバー登録をチェック
+ - MCP接続を確認
+
+3. **リソースにアクセスできない**
+ - ファイル権限を確認
+ - URI形式をチェック
+ - リソース登録を確認
+
+4. **プロンプトが一貫しない結果を生成**
+ - プロンプトテンプレートを確認
+ - 提供されたコンテキストをチェック
+ - 入力形式を検証
+
+## 次のステップと拡張
+
+### 潜在的な拡張
+1. より多くのコード分析ツールを追加(複雑さ、セキュリティ)
+2. より多くのコミュニケーションプラットフォームと統合
+3. カスタムワークフロー定義を追加
+4. PR自動マージ機能を実装
+
+### 学習パス
+- **次**: Unit 4 - このサーバーをリモートデプロイ
+- **上級**: カスタムMCPプロトコル拡張
+- **エキスパート**: マルチサーバーオーケストレーション
+
+## 結論
+
+このPRエージェントは、MCPの3つのプリミティブが連携して動作する力を実演しています。ツールは機能を提供し、リソースはコンテキストを提供し、プロンプトは一貫性を保証します。組み合わせることで、チーム標準を維持しながら開発者の生産性を向上させるインテリジェントな自動化システムを作成します。
+
+モジュラーアーキテクチャにより、各コンポーネントを独立して理解、テスト、拡張できる一方で、統合は本番環境のMCPサーバーで使用する実際のパターンを示しています。
\ No newline at end of file
diff --git a/units/ja/unit3/build-mcp-server.mdx b/units/ja/unit3/build-mcp-server.mdx
new file mode 100644
index 0000000..48e52f9
--- /dev/null
+++ b/units/ja/unit3/build-mcp-server.mdx
@@ -0,0 +1,379 @@
+# モジュール1: MCPサーバーの構築
+
+## CodeCraft StudiosでのPRカオス
+
+CodeCraft Studiosでの最初の週で、あなたはあらゆる開発者が身震いするような光景を目の当たりにしています。チームのプルリクエストは以下のような感じです:
+
+- "stuff"
+- "more changes"
+- "fix"
+- "update things"
+
+一方で、レビュワーが何が変更されたのか、なぜ変更されたのかを理解できないため、コードレビューのバックログが溜まり続けています。バックエンドチームのSarahは「various improvements」が実際に何を意味するのかを理解するのに30分を費やし、フロントエンドのMikeは「small fix」を理解するために47個のファイルを調べなければなりませんでした。
+
+チームは、より良いPR説明が必要だと分かっていますが、みんな機能の出荷に忙しくて詳細な説明を書く時間がありません。作業速度を落とすことなく支援するソリューションが必要です。
+
+**あなたのミッション**: コードの変更を分析し、自動的に有用な説明を提案するインテリジェントなPRエージェントを構築することです。
+
+### スクリーンキャスト: PRの問題の実際の様子 😬
+
+
+
+**見えるもの**: CodeCraft Studioでの実際のPRで、タイトルは「various improvements」、説明は単に「Fixed some stuff and made updates」と書かれています。典型的ですね?
+
+**混乱**: チームメートが苦労している様子を見てください:
+- **Sarah**(3時間前):「何が修正されたの?Userモデルの変更は見えるけど、これがバグの対処なのか機能追加なのか分からない」
+- **Jamie**(3時間前):「4つのサービスにまたがって8つのファイル...これらの変更は関連している?レビュー中に何に焦点を当てるべき?」
+
+**痛いポイント**: スクリーンキャストは実際のdiffを示しています—複数のサービスに散らばった8つのファイルで、コンテキストがゼロです。レビュワーが自分でストーリーをつなぎ合わせなければならず、貴重な時間を無駄にし、重要な問題を見逃す可能性があります。
+
+**なぜこれが重要か**: これは、あなたのMCPサーバーが解決する正確なPRカオスです!このモジュールの終わりまでに、これらの不可解なPRを、みんなの生活を楽にする明確で実行可能な説明に変えることができるでしょう。
+
+## 構築するもの
+
+この最初のモジュールでは、CodeCraft Studiosの自動化システムの基盤を作成します:チームがプルリクエストを書く方法を変革するMCPサーバーです。このモジュールは、モジュール2と3で構築するコアMCPコンセプトに焦点を当てています。
+
+### スクリーンキャスト: あなたのPRエージェントが問題を解決! 🚀
+
+
+
+**動作中のソリューション**: あなたのMCPサーバーがどのようにPRカオスを明確さに変えるかを見てください:
+1. **`analyze_file_changes`** - すべての変更を取得(8つのファイルにわたって453行!)
+2. **`get_per_templates`** - Claudeに選択する7つのテンプレートを表示
+3. **`suggest_template`** - Claudeが「Feature」を選択(賢い選択!)
+
+**見えるもの**: Claudeは単にテンプレートを選ぶだけでなく:
+- 実際に何が変更されたかの明確な要約を書く
+- セキュリティの問題を発見(うわ、ハッシュ化されていないパスワード!)
+- フォローアップ作業のナイスなTo-Doリストを作成
+- 最初に修正する必要があるものの優先順位付けも行う
+
+**「ワオ」の瞬間** ✨: ほんの数秒で、あなたのMCPサーバーがClaude同じブランチを実際に何が起こっているかを説明するPRに変えるのを助けます。もう混乱したレビュワーはいません、もう「これは何をするの?」というコメントもありません。
+
+**これがあなたが構築するもの**: PRの恐怖をPRの喜びに変えるツール—始めましょう!
+
+## 学習すること
+
+この基礎モジュールで、あなたは以下をマスターします:
+- **FastMCPを使用した基本的なMCPサーバーの作成方法** - モジュール2と3の構築ブロック
+- **データ取得と分析のためのMCPツールの実装** - ユニット3全体で使用するコアプリミティブ
+- **生データに基づいてClaudeに知的な決定をさせる** - すべてのMCP開発の重要な原則
+- **MCPサーバーのテストと検証** - 信頼できるツールを構築するための必須スキル
+
+## 概要
+
+あなたのPRエージェントは、MCP開発の重要な原則を使用してCodeCraft Studiosの問題を解決します:良いPRを作る硬直したルールをハードコーディングする代わりに、Claudeに生のgitデータを提供し、適切な説明を知的に提案させます。
+
+このアプローチが機能する理由:
+- **柔軟な分析**: Claudeは単純なルールが見逃すコンテキストを理解できる
+- **自然言語**: 提案が人間らしく、ロボット的でない
+- **適応性**: どのコードベースやコーディングスタイルでも機能する
+
+自動化システム全体のパターンを確立する3つの必須ツールを実装します:
+
+1. **analyze_file_changes** - gitの差分情報と変更されたファイルを取得(データ収集)
+2. **get_pr_templates** - 利用可能なPRテンプレートをリスト(リソース管理)
+3. **suggest_template** - Claudeが最も適切なテンプレートを推奨できるようにする(知的意思決定)
+
+## 始める
+
+### 前提条件
+
+- Python 3.10以上
+- Gitがインストールされており、テスト用のgitリポジトリがある
+- uvパッケージマネージャー([インストールガイド](https://docs.astral.sh/uv/getting-started/installation/))
+
+### スターターコード
+
+スターターコードリポジトリをクローンします:
+
+```bash
+git clone https://github.com/huggingface/mcp-course.git
+```
+
+スターターコードディレクトリに移動します:
+
+```bash
+cd mcp-course/projects/unit3/build-mcp-server/starter
+```
+
+依存関係をインストールします:
+
+
+
+このプロジェクト用に仮想環境を作成することをお勧めします:
+
+```bash
+uv venv .venv
+source .venv/bin/activate # Windowsの場合: .venv\Scripts\activate
+```
+
+
+```bash
+uv sync --all-extras
+```
+
+### あなたのタスク
+
+これはあなたの最初のハンズオンMCP開発体験です!`server.py`を開き、TODOコメントに従って3つのツールを実装してください。スターターコードは基本構造を提供しているので、あなたがする必要があるのは:
+
+1. **`analyze_file_changes`を実装** - gitコマンドを実行してdiffデータを返す
+ - ⚠️ **重要**: トークン制限エラーに遭遇する可能性があります(レスポンスあたり最大25,000トークン)
+ - これは適切な出力管理を教える実世界の制約です
+ - 解決策については下の「大きな出力の処理」セクションを参照してください
+ - ⚠️ **注意**: GitコマンドはデフォルトでMCPサーバーのディレクトリで実行されます。詳細については下の「作業ディレクトリの考慮事項」を参照してください
+2. **`get_pr_templates`を実装** - PRテンプレートを管理して返す
+3. **`suggest_template`を実装** - 変更タイプをテンプレートにマッピングする
+
+完璧にすることを心配する必要はありません - ユニットを進むにつれてこれらのスキルを磨いていきます。
+
+### 設計哲学
+
+ファイル拡張子や硬直したパターンに基づいて変更を分類する従来のシステムとは異なり、あなたの実装は以下を行うべきです:
+
+- Claudeに生のgitデータ(差分、ファイルリスト、統計)を提供する
+- Claudeに実際のコード変更を分析させる
+- Claudeが知的なテンプレート提案を行えるようにする
+- ロジックをシンプルに保つ - Claudeが複雑さを処理する
+
+
+
+**MCPの哲学**: ツールに複雑なロジックを構築する代わりに、Claudeに豊富なデータを提供し、その知性に決定を任せます。これにより、従来のルールベースシステムよりもコードがシンプルで柔軟になります。
+
+
+
+## 実装のテスト
+
+### 1. コードの検証
+
+検証スクリプトを実行して実装をチェックします:
+
+```bash
+uv run python validate_starter.py
+```
+
+### 2. ユニットテストの実行
+
+提供されたテストスイートで実装をテストします:
+
+```bash
+uv run pytest test_server.py -v
+```
+
+### 3. Claude Codeでのテスト
+
+Claude Codeでサーバーを直接設定します:
+
+```bash
+# MCPサーバーをClaude Codeに追加
+claude mcp add pr-agent -- uv --directory /absolute/path/to/starter run server.py
+
+# サーバーが設定されていることを確認
+claude mcp list
+```
+
+その後:
+1. gitリポジトリで何かを変更する
+2. Claudeに質問:「私の変更を分析してPRテンプレートを提案できますか?」
+3. Claudeがあなたのツールを使って知的な提案を提供するのを見る
+
+
+
+**よくある最初のエラー**: 「MCPツールレスポンスが最大許可トークン数(25000)を超えています」というエラーが出た場合、これは予想されることです!大きなリポジトリは大量のdiffを生成する可能性があります。これは貴重な学習の瞬間です - 解決策については「大きな出力の処理」セクションを参照してください。
+
+
+
+## 一般的なパターン
+
+### ツール実装パターン
+
+```python
+@mcp.tool()
+async def tool_name(param1: str, param2: bool = True) -> str:
+ """Claudeのためのツール説明。
+
+ Args:
+ param1: パラメータの説明
+ param2: デフォルト値を持つオプションパラメータ
+ """
+ # あなたの実装
+ result = {"key": "value"}
+ return json.dumps(result)
+```
+
+### エラーハンドリング
+
+常に潜在的なエラーを適切に処理します:
+
+```python
+try:
+ result = subprocess.run(["git", "diff"], capture_output=True, text=True)
+ return json.dumps({"output": result.stdout})
+except Exception as e:
+ return json.dumps({"error": str(e)})
+```
+
+
+
+**エラーハンドリング**: エラーの場合でも、ツールからは常に有効なJSONを返してください。Claudeは何が間違ったかを理解し、ユーザーに有用な回答を提供するために構造化データが必要です。
+
+
+
+### 大きな出力の処理(重要な学習の瞬間!)
+
+
+
+**実世界の制約**: MCPツールには、レスポンスあたり25,000トークンの制限があります。大きなgit diffは簡単にこの制限を10倍以上超える可能性があります!これはプロダクションMCP開発にとって重要な教訓です。
+
+
+
+`analyze_file_changes`を実装する際、このエラーに遭遇する可能性があります:
+```
+Error: MCP tool response (262521 tokens) exceeds maximum allowed tokens (25000)
+```
+
+**なぜこれが起こるか:**
+- 単一ファイルの変更が数千行になることがある
+- エンタープライズリポジトリには大規模なリファクタリングがある
+- Git diffはデフォルトで完全なコンテキストを含む
+- JSONエンコーディングがオーバーヘッドを追加する
+
+これは重要な原則を教えてくれます:**常に出力制限を念頭に置いてツールを設計する**。解決策は以下の通りです:
+
+```python
+@mcp.tool()
+async def analyze_file_changes(base_branch: str = "main",
+ include_diff: bool = True,
+ max_diff_lines: int = 500) -> str:
+ """スマートな出力制限付きでファイル変更を分析。
+
+ Args:
+ base_branch: 比較対象のブランチ
+ include_diff: 実際のdiffを含めるかどうか
+ max_diff_lines: 含める最大diff行数(デフォルト500)
+ """
+ try:
+ # diffを取得
+ result = subprocess.run(
+ ["git", "diff", f"{base_branch}...HEAD"],
+ capture_output=True,
+ text=True
+ )
+
+ diff_output = result.stdout
+ diff_lines = diff_output.split('\n')
+
+ # 必要に応じてスマート切り捨て
+ if len(diff_lines) > max_diff_lines:
+ truncated_diff = '\n'.join(diff_lines[:max_diff_lines])
+ truncated_diff += f"\n\n... 出力が切り捨てられました。{len(diff_lines)}行のうち{max_diff_lines}行を表示 ..."
+ diff_output = truncated_diff
+
+ # サマリー統計を取得
+ stats_result = subprocess.run(
+ ["git", "diff", "--stat", f"{base_branch}...HEAD"],
+ capture_output=True,
+ text=True
+ )
+
+ return json.dumps({
+ "stats": stats_result.stdout,
+ "total_lines": len(diff_lines),
+ "diff": diff_output if include_diff else "include_diff=trueを使用してdiffを表示",
+ "files_changed": self._get_changed_files(base_branch)
+ })
+
+ except Exception as e:
+ return json.dumps({"error": str(e)})
+```
+
+**大きな出力のベストプラクティス:**
+1. **ページネーションの実装**: 大きな結果をページに分割
+2. **フィルタリングオプションの追加**: ユーザーが特定のファイルやディレクトリを要求できるようにする
+3. **まずサマリーを提供**: 完全なコンテンツの前に統計を返す
+4. **段階的開示を使用**: 高レベル情報から始めて、詳細に掘り下げを許可
+5. **合理的なデフォルトを設定**: ほとんどのケースで機能する合理的な制限をデフォルトにする
+
+## 作業ディレクトリの考慮事項
+
+デフォルトでは、MCPサーバーは、Claudeの現在の作業ディレクトリではなく、インストールディレクトリでコマンドを実行します。これは、gitコマンドが間違ったリポジトリを分析する可能性があることを意味します!
+
+これを解決するために、MCPは[roots](https://modelcontextprotocol.io/docs/concepts/roots)を提供します - クライアントが関連ディレクトリについてサーバーに通知する方法です。Claude Codeは自動的に作業ディレクトリをrootとして提供します。
+
+ツールでこれにアクセスする方法は以下の通りです:
+
+```python
+@mcp.tool()
+async def analyze_file_changes(...):
+ # rootsからClaudeの作業ディレクトリを取得
+ context = mcp.get_context()
+ roots_result = await context.session.list_roots()
+
+ # FileUrlオブジェクトからパスを抽出
+ working_dir = roots_result.roots[0].uri.path
+
+ # すべてのgitコマンドに使用
+ result = subprocess.run(
+ ["git", "diff", "--name-status"],
+ capture_output=True,
+ text=True,
+ cwd=working_dir # Claudeのディレクトリで実行!
+ )
+```
+
+これにより、ツールがMCPサーバーのインストール場所ではなく、Claudeが実際に作業しているリポジトリで動作することが保証されます。
+
+## トラブルシューティング
+
+- **インポートエラー**: `uv sync`を実行したことを確認してください
+- **Gitエラー**: gitリポジトリ内にいることを確認してください
+- **出力なし**: MCPサーバーはstdio経由で通信します - Claude Desktopでテストしてください
+- **JSONエラー**: すべてのツールは有効なJSON文字列を返す必要があります
+- **トークン制限超過**: これは大きなdiffでは予想されることです!上記のような出力制限を実装してください
+- **「レスポンスが大きすぎる」エラー**: `max_diff_lines`パラメータを追加するか、`include_diff=false`を設定してください
+- **Gitコマンドが間違ったディレクトリで実行される**: MCPサーバーはデフォルトでClaudeの作業ディレクトリではなく、インストールディレクトリで実行されます。これを修正するには、[MCP roots](https://modelcontextprotocol.io/docs/concepts/roots)を使用してClaudeの現在のディレクトリにアクセスしてください:
+ ```python
+ # rootsからClaudeの作業ディレクトリを取得
+ context = mcp.get_context()
+ roots_result = await context.session.list_roots()
+ working_dir = roots_result.roots[0].uri.path # FileUrlオブジェクトには.pathプロパティがある
+
+ # subprocessコールで使用
+ subprocess.run(["git", "diff"], cwd=working_dir)
+ ```
+ Claude Codeは自動的に作業ディレクトリをrootとして提供し、MCPサーバーが正しい場所で動作できるようにします。
+
+## 次のステップ
+
+おめでとうございます!ユニット3で続くすべての基盤となる、ツール付きの最初のMCPサーバーを構築しました。
+
+### モジュール1で達成したこと:
+- **MCPツールを作成** - Claudeに構造化データを提供
+- **コアMCP哲学を実装** - 生データからClaudeに知的決定をさせる
+- **実用的なPRエージェントを構築** - コード変更を分析してテンプレートを提案できる
+- **実世界の制約について学習** - 25,000トークン制限とその対処法
+- **テストパターンを確立** - 検証スクリプトとユニットテストを使用
+
+### 再利用可能な重要パターン:
+- **データ収集ツール** - 外部ソースから情報を収集
+- **知的分析** - Claudeが生データを処理して決定を下す
+- **出力管理** - 有用性を保ちながら大きなレスポンスを切り捨てる
+- **エラーハンドリング** - 構造化JSONレスポンスを返す
+- **テスト戦略** - MCPサーバー開発のため
+
+### 次にすること:
+1. **ソリューションを確認** - `/projects/unit3/build-mcp-server/solution/`で異なる実装アプローチを見る
+2. **実装を比較** - 提供されたソリューションと比較 - 問題を解決する「正しい」方法は一つではありません
+3. **ツールを徹底的にテスト** - 異なるタイプのコード変更で試して、Claudeがどう適応するかを見る
+4. **モジュール2に進む** - リアルタイムwebhook機能を追加し、ワークフロー標準化のためのMCPプロンプトについて学ぶ
+
+モジュール2は、ここで作成したサーバーを直接基盤として構築し、静的ファイル分析ツールを補完する動的イベントハンドリングを追加します!
+
+### ストーリーは続く...
+あなたのPRエージェントが機能することで、CodeCraft Studiosの開発者はすでにより良いプルリクエストを書いています。しかし来週、あなたは新しい挑戦に直面します:重要なCI/CD障害が気づかれずに通り過ぎています。モジュール2では、これらの問題がプロダクションに到達する前にキャッチするリアルタイム監視を追加します。
+
+## 追加リソース
+
+- [MCP ドキュメント](https://modelcontextprotocol.io/)
+- [FastMCP ガイド](https://modelcontextprotocol.io/quickstart/server)
+- ソリューションウォークスルー: `unit3/build-mcp-server-solution-walkthrough.md`
\ No newline at end of file
diff --git a/units/ja/unit3/certificate.mdx b/units/ja/unit3/certificate.mdx
new file mode 100644
index 0000000..8f127ec
--- /dev/null
+++ b/units/ja/unit3/certificate.mdx
@@ -0,0 +1,18 @@
+# 認定証を取得しましょう!
+
+よくできました!MCPコースのユニット3を完了しました。今度は認定証を取得するために試験を受ける時です。
+
+以下はユニットの理解を確認するためのクイズです。
+
+
+
+
+
+上記のクイズの使用に問題がある場合は、[Hugging Face Hub](https://huggingface.co/spaces/mcp-course/unit_3_quiz)でスペースに直接アクセスしてください。エラーを見つけた場合は、スペースの[Communityタブ](https://huggingface.co/spaces/mcp-course/unit_3_quiz/discussions)で報告できます。
+
+
\ No newline at end of file
diff --git a/units/ja/unit3/conclusion.mdx b/units/ja/unit3/conclusion.mdx
new file mode 100644
index 0000000..16f822a
--- /dev/null
+++ b/units/ja/unit3/conclusion.mdx
@@ -0,0 +1,147 @@
+# Unit 3 まとめ:CodeCraft Studios の変革
+
+## ミッション完了!
+
+おめでとうございます!CodeCraft Studios を混沌としたスタートアップから、よく整備された開発マシンに変革することに成功しました。これまでの道のりを振り返ってみましょう:
+
+### 自動化システム導入前:
+- ❌ 「stuff」や「fix」といった説明のPR
+- ❌ 検出されずに本番環境に到達する重要なバグ
+- ❌ サイロ化したチームによる作業の重複
+- ❌ 既に修正された問題に対する週末のデバッグセッション
+
+### 自動化システム導入後:
+- ✅ レビュアーの時間を節約する明確で有用なPR説明
+- ✅ 失敗を即座に捉えるリアルタイムCI/CD監視
+- ✅ 全員に情報を提供するスマートなチーム通知
+- ✅ プロセスの問題と戦うのではなく、機能の構築に集中する開発者
+
+CodeCraft Studios チームは現在、MCPの柔軟性とClaudeの知能を組み合わせることで何が可能になるかを実証する完全な自動化システムを持っています。
+
+## 各課題の解決方法
+
+3つのモジュールからなる旅路で、すべての開発チームが直面する実際の問題に取り組みました:
+
+### モジュール 1:PR の混沌を解決
+*「開発者の作業を遅らせることなく、より良いプルリクエストを書く手助けをする」*
+- インテリジェントなファイル分析を持つ **PR Agent**
+- **コア MCP 概念**:ツール、データ収集、Claude統合
+- **設計哲学**:生データを提供し、Claudeに知的な判断をさせる
+- **結果**:レビュアーが変更を理解するのに役立つ明確なPR説明
+
+### モジュール 2:無音の失敗を捕捉
+*「もう二度と重要なバグが気付かれずに通り抜けることを許さない」*
+- GitHub Actions イベントを捕捉する **Webhook サーバー**
+- 標準化されたワークフローガイダンスのための **MCP プロンプト**
+- シンプルなJSONファイルを使用した **イベントストレージシステム**
+- **結果**:本番問題を防ぐリアルタイムCI/CD監視
+
+### モジュール 3:コミュニケーションギャップの橋渡し
+*「何が起こっているかについてチーム全体に情報を提供し続ける」*
+- チーム通知のための **Slack 統合**
+- Claudeの知能を使用した **メッセージフォーマット**
+- 強力な自動化のための **ツール + プロンプトの組み合わせ**
+- **結果**:情報のサイロを排除するスマート通知
+
+## 学んだ主要なMCP概念
+
+### MCP プリミティブ
+- **ツール**:データアクセスと外部API呼び出し用
+- **プロンプト**:一貫したワークフローガイダンスとフォーマット用
+- **統合パターン**:ツールとプロンプトがどのように連携するか
+
+### アーキテクチャパターン
+- **関心の分離**:MCPサーバー vs webhookサーバー
+- **ファイルベースのイベント保存**:シンプル、信頼性があり、テスト可能
+- **知能層としてのClaude**:生データから判断を下す
+
+### 開発ベストプラクティス
+- **エラーハンドリング**:失敗時でも構造化されたJSONを返す
+- **セキュリティ**:機密認証情報のための環境変数
+- **テスト**:バリデーションスクリプトと手動テストワークフロー
+
+## 実世界での応用
+
+学んだパターンは多くの自動化シナリオに適用できます:
+
+
+
+**CI/CDを超えて**:ツール + プロンプトパターンは、カスタマーサポート自動化、コンテンツモデレーション、データ分析ワークフロー、そして外部データのインテリジェントな処理が必要なあらゆるシナリオで機能します。
+
+
+
+### Unit 3の共通パターン
+1. **データ収集** → 情報を集めるツール
+2. **インテリジェント分析** → Claudeがデータを処理
+3. **フォーマット済み出力** → プロンプトが一貫したプレゼンテーションをガイド
+4. **外部統合** → ツールがAPIやサービスとやり取り
+
+## 次のステップ
+
+### 即座のアクション
+1. ワークフロー自動化を**実験**する - 異なるGitHubイベントを試す
+2. 追加統合(Discord、メールなど)でシステムを**拡張**する
+3. 実際のプロジェクトで使用するために、MCPサーバーをチームメイトと**共有**する
+
+### 高度な探索
+- **スケールアップ**:複数のリポジトリやチームを処理
+- **永続性の追加**:より大きなイベントボリュームにはデータベースを使用
+- **ダッシュボードの作成**:自動化のためのWebインターフェースを構築
+- **他のMCPクライアントを探索**:Claude CodeとClaude Desktopを超えて
+
+### コミュニティへの参加
+- 独自のサーバーでMCPエコシステムに**貢献**
+- 発見したパターンをコミュニティと**共有**
+- 既存のMCPサーバーの上に**構築**し、その機能を拡張
+
+## 重要なポイント
+
+
+
+**MCP哲学**:最も効果的なMCPサーバーはスマートになろうとしません - Claudeに豊富で構造化されたデータを提供し、Claudeの知能に重い作業をさせます。これによりコードがよりシンプルで柔軟になります。
+
+
+
+### 技術的洞察
+- **シンプルは強力**:JSONファイルストレージは多くのユースケースを処理可能
+- **オーケストレーターとしてのClaude**:Claudeにツール間の調整をさせる
+- **一貫性のためのプロンプト**:信頼できる出力フォーマットを保証するためにプロンプトを使用
+
+### 開発の洞察
+- **小さく始める**:一度に一つのツールを構築し、徹底的にテスト
+- **ワークフローで考える**:うまく連携するツールを設計
+- **人間のために計画**:自動化はチームを置き換えるのではなく、支援すべき
+
+## 継続学習のためのリソース
+
+### MCP ドキュメント
+- [公式 MCP プロトコル](https://modelcontextprotocol.io/)
+- [Python SDK リファレンス](https://github.com/modelcontextprotocol/python-sdk)
+- [FastMCP フレームワーク](https://gofastmcp.com/)
+
+### コミュニティリソース
+- [MCP サーバーディレクトリ](https://modelcontextprotocol.io/servers)
+- [実装例](https://github.com/modelcontextprotocol)
+- [コミュニティ Discord](https://discord.gg/modelcontextprotocol)
+
+---
+
+## CodeCraft Studios サクセスストーリー
+
+3週間前、CodeCraft Studios は以下の問題に苦しんでいました:
+- レビューの遅延を引き起こす不明確なプルリクエスト
+- 本番環境に入り込む重要なバグ
+- 孤立して作業し、作業を重複させるチーム
+
+今日、彼らは以下を行うインテリジェントな自動化システムを持っています:
+- **開発者を支援**し、明確で有用なPR説明を自動的に書く
+- **CI/CDパイプラインを監視**し、問題を即座にチームに警告
+- **全員に情報を提供**し続ける、スマートでコンテキストに応じたチーム通知
+
+あなたは単なるMCPサーバー以上のものを構築しました - 開発チームの協働方法を変革するソリューションを作成したのです。
+
+## あなたのMCP の旅は続く
+
+CodeCraft Studios で学んだパターンは、無数の他の自動化課題を解決できます。カスタマーサービスツール、データ分析パイプライン、またはインテリジェントな処理が必要なあらゆるシステムを構築している場合でも、MCPで強力で適応性のあるソリューションを作成するための基盤を今や持っています。
+
+インテリジェント自動化の未来はあなたの手の中にあります。次に何を構築しますか?🚀
\ No newline at end of file
diff --git a/units/ja/unit3/github-actions-integration.mdx b/units/ja/unit3/github-actions-integration.mdx
new file mode 100644
index 0000000..6e2685b
--- /dev/null
+++ b/units/ja/unit3/github-actions-integration.mdx
@@ -0,0 +1,268 @@
+# モジュール2:GitHub Actions統合
+
+## 静寂な失敗の襲来
+
+CodeCraft Studiosでの2週目。モジュール1で作成したPRエージェントは既に開発者のより良いプルリクエスト作成を支援しています - Sarahの最新PRには、Mikeの調査時間を20分節約した明確な説明がありました。チームは大喜びです!
+
+しかし、その後災害が起こります。
+
+金曜日の午後、重要なバグが本番環境に到達しました。決済システムがダウンし、顧客が苦情を言い、チームは調査のために奔走します。2時間のストレスフルな時間の後、根本原因を発見しました:火曜日のCI実行でのテスト失敗で、誰も気づいていませんでした。
+
+「これを見逃すなんて?」とチームリーダーがGitHub Actionsをスクロールしながら尋ねます。「テストは明らかに失敗していたのに、47のリポジトリと数十の日次コミットで、誰がすべてのビルドをチェックする時間があるでしょうか?」
+
+チームは、CI/CDパイプラインへのリアルタイムの可視性が必要だと認識しますが、すべてのプロジェクトでGitHub Actionsを手動でチェックするのはスケーラブルではありません。問題を監視し、即座にアラートする自動化が必要です。
+
+**あなたのミッション**:MCPサーバーをWebhook機能で拡張し、GitHub Actionsを監視して、もう一つの失敗が気づかれずに通り過ぎることがないようにする。
+
+## 構築するもの
+
+このモジュールは、静的ファイル分析(モジュール1)と動的チーム通知(モジュール3)の間のギャップを埋めます。PRエージェントを包括的な開発監視システムに変換するリアルタイム機能を追加します。
+
+モジュール1で作成した基盤の上に、以下を追加します:
+- GitHub Actionsイベントを受信するための**Webhookサーバー**
+- CI/CDステータスを監視するための**新しいツール**
+- 一貫したワークフローパターンを提供する**MCPプロンプト**
+- GitHubリポジトリとの**リアルタイム統合**
+
+### スクリーンキャスト:リアルタイムCI/CD監視の実践!🎯
+
+
+
+**セットアップ**:CodeCraft Studiosの新しいシステムが本番環境に到達する前に失敗をキャッチする様子をご覧ください:
+1. **GitHub Webhooks** - サーバーにイベントを送信する実際のWebhook設定を確認
+2. **失敗したテスト** - 以前は気づかれなかった赤いX?もう違います!
+3. **ローカル開発** - Webhookサーバーとcloudflare tunnelが連携して動作
+
+**リアルタイムでのMCPマジック**:Claudeが3つの主要リクエストに対応:
+- **「どのGitHub Actionsイベントを受信しましたか?」** - Claudeが新しいツールを使用して最近のアクティビティをチェック
+- **「CI結果を分析」** - Claudeがテスト失敗を深く調査し、実用的な洞察を提供する様子を確認
+- **「デプロイメント要約を作成」** - MCPプロンプトがClaudeをガイドしてチームフレンドリーな更新を作成する様子を確認
+
+**もう静寂な失敗はありません**🚨:火曜日の失敗したテストから来た重要なバグを覚えていますか?このシステムがあれば、Claudeは即座にそれを捕捉したでしょう。スクリーンキャストは、MCPサーバーがGitHubの生のWebhookデータを明確で実用的なアラートに変換する正確な方法を示しています。
+
+**これが特別な理由**:モジュール1のPRエージェントは静的でした - 尋ねられたときにコードを分析しました。このモジュール2の拡張は動的です - CI/CDパイプラインを24/7監視し、Claudeがリアルタイムの洞察を提供するのを支援します。もう金曜日の午後のサプライズはありません!
+
+## 学習目標
+
+このモジュールの終わりまでに、以下のことを理解します:
+1. MCPサーバーと並行してWebhookサーバーを実行する方法
+2. GitHub Webhookを受信・処理する方法
+3. 標準化されたワークフローのためのMCPプロンプトを作成する方法
+4. ローカルWebhookテスト用にCloudflare Tunnelを使用する方法
+
+## 前提条件
+
+モジュール1の作業を直接基盤として構築するため、以下を確認してください:
+- **完了したモジュール1:MCPサーバーの構築** - 同じコードベースを拡張します
+- **GitHub Actionsの基本的な理解** - CI/CDワークフローが何かを知っている必要があります
+- **Actions有効なGitHubリポジトリ** - シンプルなワークフローファイルでも問題ありません
+- **Cloudflare Tunnel(cloudflared)のインストール** - これがローカルWebhookサーバーをGitHubに公開します
+
+## 主要概念
+
+### MCPプロンプト
+
+プロンプトは、Claudeを複雑なワークフローに導く再利用可能なテンプレートです。ツール(Claudeが自動的に呼び出す)とは異なり、プロンプトはユーザーが開始し、構造化されたガイダンスを提供します。
+
+使用例:
+- CI/CD結果を一貫して分析する
+- 標準化されたデプロイメント要約を作成する
+- 失敗を体系的にトラブルシューティングする
+
+### Webhook統合
+
+MCPサーバーは2つのサービスを実行します:
+1. MCPサーバー(Claudeと通信)
+2. ポート8080のWebhookサーバー(GitHubイベントを受信)
+
+これにより、ClaudeがリアルタイムのCI/CDイベントに反応できます!
+
+
+
+**アーキテクチャの洞察**:MCP通信とWebhook処理に別々のサービスを実行することは、関心の明確な分離です。WebhookサーバーはHTTPの複雑さを処理し、MCPサーバーはデータ分析とClaude統合に集中します。
+
+
+
+## プロジェクト構造
+
+```
+github-actions-integration/
+├── starter/ # あなたの開始点
+│ ├── server.py # モジュール1のコード + TODO
+│ ├── pyproject.toml
+│ └── README.md
+└── solution/ # 完全な実装
+ ├── server.py # 完全なWebhook + プロンプト
+ ├── pyproject.toml
+ └── README.md
+```
+
+## 実装手順
+
+### ステップ1:Webhookサーバーのセットアップと実行
+
+既存ファイルで作業したモジュール1とは異なり、このモジュールではリアルタイムイベントハンドリングを導入します。スターターコードには以下が含まれます:
+- **モジュール1の実装** - 既存のPR分析ツールすべて
+- **完全なWebhookサーバー**(`webhook_server.py`) - GitHubイベントを受信する準備完了
+
+1. 依存関係をインストール(モジュール1と同じ):
+ ```bash
+ uv sync
+ ```
+
+2. Webhookサーバーを開始(別のターミナルで):
+ ```bash
+ python webhook_server.py
+ ```
+
+このサーバーはGitHub Webhookを受信し、`github_events.json`に保存します。
+
+**Webhookイベント保存の仕組み:**
+- 各着信GitHub Webhook(push、pull request、ワークフロー完了など)はJSONファイルに追加されます
+- イベントはタイムスタンプ付きで保存され、最近のアクティビティを簡単に見つけられます
+- ファイルはMCPツールが読み取って分析できるシンプルなイベントログとして機能します
+- データベースは不要 - すべてシンプルで読みやすいJSON形式で保存されます
+
+### ステップ2:イベントストレージへの接続
+
+これで、MCPサーバー(モジュール1から)をWebhookデータに接続します。これはHTTPリクエストを直接処理するよりもはるかにシンプルです - WebhookサーバーがすべてのHTTPの重い作業を行い、イベントをJSONファイルに保存します。
+
+Webhookイベントを読み取るパスを追加:
+
+```python
+# Webhookサーバーがイベントを保存するファイル
+EVENTS_FILE = Path(__file__).parent / "github_events.json"
+```
+
+WebhookサーバーがすべてのHTTPの詳細を処理します - JSONファイルを読み取るだけです!この関心の分離により、MCPサーバーは最も得意なことに集中できます。
+
+
+
+**開発のヒント**:HTTPリクエストではなくファイルで作業することで、テストがはるかに簡単になります。Webhookを設定せずに`github_events.json`に手動でイベントを追加してツールをテストできます。
+
+
+
+### ステップ3:GitHub Actionsツールを追加
+
+モジュール1でファイル分析用のツールを作成したのと同様に、今度はCI/CD分析用のツールを作成します。これらのツールは既存のPR分析ツールと並行して動作し、Claudeにコード変更とビルドステータスの両方の完全なビューを提供します。
+
+
+
+**注意**:スターターコードには既にモジュール1の出力制限修正が含まれているため、トークン制限エラーは発生しません。このモジュールの新しい概念に集中してください!
+
+
+
+2つの新しいツールを実装:
+
+1. **`get_recent_actions_events`**:
+ - `EVENTS_FILE`から読み取り
+ - 最新のイベントを返す(制限まで)
+ - ファイルが存在しない場合は空のリストを返す
+
+2. **`get_workflow_status`**:
+ - ファイルからすべてのイベントを読み取り
+ - workflow_runイベントをフィルタリング
+ - ワークフロー名でグループ化し、最新のステータスを表示
+
+これらのツールにより、ClaudeはCI/CDパイプラインを分析できます。
+
+### ステップ4:MCPプロンプトを作成
+
+これで初めてのMCPプロンプトを追加します!ツール(Claudeが自動的に呼び出す)とは異なり、プロンプトはユーザーがClaudeと一貫して相互作用するのを支援するテンプレートです。複雑なワークフローを通じてClaudeをガイドする「会話のきっかけ」と考えてください。
+
+モジュール1はデータアクセス用のツールに焦点を当てましたが、このモジュールはワークフローガイダンス用のプロンプトを導入します。
+
+異なるワークフローパターンを実証する4つのプロンプトを実装:
+
+1. **`analyze_ci_results`**:包括的なCI/CD分析
+2. **`create_deployment_summary`**:チームフレンドリーな更新
+3. **`generate_pr_status_report`**:コード + CIレポートの組み合わせ
+4. **`troubleshoot_workflow_failure`**:体系的なデバッグ
+
+各プロンプトは、Claudeが従うべき明確な指示を含む文字列を返す必要があります。
+
+### ステップ5:Cloudflare Tunnelでテスト
+
+さて、興奮する部分です - 実際のGitHubイベントで拡張されたMCPサーバーをテストします!実際の開発環境と同じように、複数のサービスを一緒に実行します。
+
+1. MCPサーバーを開始(モジュール1と同じコマンド):
+ ```bash
+ uv run server.py
+ ```
+
+2. 別のターミナルでCloudflare Tunnelを開始:
+ ```bash
+ cloudflared tunnel --url http://localhost:8080
+ ```
+
+3. tunnel URLでGitHub Webhookを設定
+
+4. プロンプトを使用してClaude Codeでテスト
+
+## 演習
+
+### 演習1:カスタムワークフロープロンプト
+以下を組み合わせてPRレビューを支援する新しいプロンプトを作成:
+- モジュール1ツールからのコード変更
+- モジュール2ツールからのCI/CDステータス
+- レビュアー用のチェックリスト形式
+
+### 演習2:イベントフィルタリング
+`get_workflow_status`を拡張して以下を行う:
+- ワークフロー結論でフィルタリング(成功/失敗)
+- リポジトリでグループ化
+- 最後の実行からの時間を表示
+
+### 演習3:通知システム
+以下を行うツールを追加:
+- どのイベントが「見られた」かを追跡
+- 新しい失敗をハイライト
+- 通知すべきチームメンバーを提案
+
+## 一般的な問題
+
+### Webhookがイベントを受信しない
+- Cloudflare Tunnelが実行中であることを確認
+- GitHub Webhook設定をチェック(最近の配信を表示する必要があります)
+- ペイロードURLに`/webhook/github`が含まれていることを確認
+
+### プロンプトが動作しない
+- FastMCPプロンプトは単純に文字列を返します
+- 関数が`@mcp.prompt()`でデコレートされていることを確認
+
+### Webhookサーバーの問題
+- webhook_server.pyが別のターミナルで実行されていることを確認
+- ポート8080が空いていることをチェック:`lsof -i :8080`
+- イベントファイルは最初のイベント受信時に自動的に作成されます
+
+## 次のステップ
+
+優秀な作業です!MCPサーバーにリアルタイム機能を正常に追加しました。以下のことができるシステムができました:
+
+- **コード変更を分析**(モジュール1から)
+- **リアルタイムでCI/CDイベントを監視**(このモジュールから)
+- **MCPプロンプトを使用**して一貫したワークフローガイダンスを提供
+- **ファイルベースアーキテクチャ**を通じてWebhookイベントを処理
+
+### モジュール2での主要な成果:
+- 初めてのWebhook統合を構築
+- ワークフロー標準化のためのMCPプロンプトを学習
+- リアルタイムデータで動作するツールを作成
+- イベント駆動自動化のパターンを確立
+
+### 次にすべきこと:
+1. `/projects/unit3/github-actions-integration/solution/`の**解決方法を確認**して異なる実装アプローチを確認
+2. **プロンプトを実験**してみる - 異なるタイプのGitHubイベントに使用してみる
+3. **統合をテスト**する - 単一の会話でClaudeとのモジュール1ファイル分析ツールとモジュール2イベント監視を組み合わせる
+4. **モジュール3に進む** - Slack統合を追加して自動化パイプラインを完成させる
+
+モジュール3では、チームが実際に使用できる完全なワークフローにすべてをまとめます!
+
+### ストーリーは続きます...
+監視システムが動作しています!CodeCraft StudiosはCI/CDの失敗をリアルタイムでキャッチし、チームはデプロイメントについてはるかに自信を持てるようになりました。しかし、来週は新しい課題をもたらします:情報サイロが重複作業と機会の見逃しを引き起こしています。モジュール3では、皆がループに入り続けるインテリジェントなチーム通知で自動化システムを完成させます。
+
+## 追加リソース
+
+- [MCPプロンプトドキュメント](https://modelcontextprotocol.io/docs/concepts/prompts)
+- [GitHub Webhooksガイド](https://docs.github.com/en/developers/webhooks-and-events)
+- [Cloudflare Tunnelドキュメント](https://developers.cloudflare.com/cloudflare-one/connections/connect-apps)
\ No newline at end of file
diff --git a/units/ja/unit3/introduction.mdx b/units/ja/unit3/introduction.mdx
new file mode 100644
index 0000000..2781a64
--- /dev/null
+++ b/units/ja/unit3/introduction.mdx
@@ -0,0 +1,85 @@
+# 高度なMCP開発:Claude Code用カスタムワークフローサーバーの構築
+
+ユニット3へようこそ!このユニットでは、3つのMCPプリミティブすべてを学習しながら、カスタム開発ワークフローでClaude Codeを強化する実用的なMCPサーバーを構築します。
+
+MCPの作成者の声を聞きたい場合は、彼らが作成したビデオをご覧ください:
+
+
+
+このビデオでは、Theo Chu、David Soria Parra、Alex AlbertがModel Context Protocol(MCP)について詳しく解説しています。MCPは、AIアプリケーションが外部データやツールと接続する方法を変革している標準です。
+
+## 構築するもの
+
+**PRエージェントワークフローサーバー** - Claude Codeをチーム対応でワークフロー対応にする方法を実証するMCPサーバー:
+
+- **スマートPR管理**:MCPツールを使用したコード変更に基づく自動PRテンプレート選択
+- **CI/CD監視**:Cloudflare TunnelとスタンダードプロンプトでGitHub Actionsを追跡
+- **チームコミュニケーション**:すべてのMCPプリミティブが連携するSlack通知
+
+## 実世界ケーススタディ
+
+すべての開発チームが直面する実用的なシナリオを実装します:
+
+**以前**:開発者が手動でPRを作成し、Actionsの完了を待ち、手動で結果を確認し、チームメンバーへの通知を忘れずに行う
+
+**以後**:ワークフローサーバーに接続されたClaude Codeは、次のことを知的に行えます:
+- 変更されたファイルに基づいて適切なPRテンプレートを提案
+- GitHub Actionsの実行を監視し、フォーマットされた要約を提供
+- デプロイの成功/失敗時にSlack経由でチームに自動通知
+- Actionsの結果に基づいてチーム固有のレビュープロセスを開発者にガイド
+
+## 主な学習成果
+
+1. **コアMCPプリミティブ**:実践的な例を通じてツールとプロンプトをマスター
+2. **MCPサーバー開発**:適切な構造とエラーハンドリングを持つ機能的なサーバーの構築
+3. **GitHub Actions統合**:Cloudflare Tunnelを使用してWebhookを受信し、CI/CDイベントを処理
+4. **Hugging Face Hubワークフロー**:LLM開発チーム向けの特化したワークフローの作成
+5. **マルチシステム統合**:MCPを通じてGitHub、Slack、Hugging Face Hubを接続
+6. **Claude Code拡張**:Claudeにチームの特定のワークフローを理解させる
+
+## MCPプリミティブの実践
+
+このユニットでは、コアMCPプリミティブの実践的な経験を提供します:
+
+- **ツール**(モジュール1):Claudeがファイルを分析してテンプレートを提案するために呼び出せる関数
+- **プロンプト**(モジュール2):一貫したチームプロセスのための標準化されたワークフロー
+- **統合**(モジュール3):複雑な自動化のためにすべてのプリミティブが連携
+
+## モジュール構成
+
+1. **モジュール1:MCPサーバーの構築** - PRテンプレート提案用のツールを持つ基本サーバーの作成
+2. **モジュール2:GitHub Actions統合** - Cloudflare Tunnelとプロンプトを使用したCI/CD監視
+3. **モジュール3:Slack通知** - すべてのMCPプリミティブを統合したチームコミュニケーション
+
+## 前提条件
+
+このユニットを開始する前に、以下を確認してください:
+
+- ユニット1と2の完了
+- GitHub ActionsとWebhookの概念の基本的な理解
+- テスト用のGitHubリポジトリへのアクセス(個人のテストリポジトリでも可)
+- Webhook統合を作成できるSlackワークスペース
+
+### Claude Codeのインストールとセットアップ
+
+このユニットでは、MCPサーバー統合をテストするためにClaude Codeが必要です。
+
+
+
+**インストール必須:** このユニットでは、AIワークフローとのMCPサーバー統合をテストするためにClaude Codeが必要です。
+
+
+
+**クイックセットアップ:**
+
+[公式インストールガイド](https://docs.anthropic.com/en/docs/claude-code/getting-started)に従ってClaude Codeをインストールし、認証を完了してください。主要なステップは、npmを介したインストール、プロジェクトディレクトリへの移動、`claude`の実行によるconsole.anthropic.comを通じた認証です。
+
+インストール後は、このユニット全体でClaude Codeを使用してMCPサーバーをテストし、構築するワークフロー自動化と相互作用します。
+
+
+
+**Claude Codeが初めてですか?** セットアップの問題が発生した場合、[トラブルシューティングガイド](https://docs.anthropic.com/en/docs/claude-code/troubleshooting)で一般的なインストールと認証の問題をカバーしています。
+
+
+
+このユニットの終わりには、Claude Codeを強力なチーム開発アシスタントに変換する方法を実証する完全なMCPサーバーを構築し、3つのMCPプリミティブすべてを使用した実践的な経験を積むことになります。
\ No newline at end of file
diff --git a/units/ja/unit3/mcp-server-hf-course-in-action.png b/units/ja/unit3/mcp-server-hf-course-in-action.png
new file mode 100644
index 0000000..1b15335
Binary files /dev/null and b/units/ja/unit3/mcp-server-hf-course-in-action.png differ
diff --git a/units/ja/unit3/slack-notification.mdx b/units/ja/unit3/slack-notification.mdx
new file mode 100644
index 0000000..73ea10f
--- /dev/null
+++ b/units/ja/unit3/slack-notification.mdx
@@ -0,0 +1,376 @@
+# モジュール3: Slack通知
+
+## コミュニケーションギャップの危機
+
+CodeCraft Studiosの第3週。あなたの自動化システムは既にチームの働き方を変革しています:
+- **PRエージェント**(モジュール1):開発者が明確で役立つプルリクエストの説明を書いている
+- **CI/CDモニター**(モジュール2):チームがテストの失敗を即座に発見し、本番環境にバグが到達することを防いでいる
+
+チームはずっと自信を持てるようになっていました...月曜日の朝に新しい危機が訪れるまでは。
+
+フロントエンドチーム(EmmaとJake)は、厄介なAPI統合問題のデバッグに週末全体を費やしました。彼らはあらゆることを試しました:ネットワークコールをチェックし、リクエスト形式を検証し、エラーハンドリングまで書き直しました。ついに日曜日の午前2時、彼らはバックエンドチームが金曜日にこの正確な問題を修正し、ステージング環境にその修正をデプロイしていたことを発見しました - しかし、それを発表するのを忘れていたのです。
+
+「私たちは既に修正された問題を解決するのに12時間も無駄にした!」Emmaは苛立って言いました。
+
+一方、デザインチームは先週新しいユーザーオンボーディングフローのイラストを完成させましたが、フロントエンドチームはそれが準備できていることを知りませんでした。それらの美しいアセットは、チームが一時的なデザインを出荷している間、まだ使用されずに置かれています。
+
+チームは情報サイロの問題があることに気づきました。みんな一生懸命働いているのに、いつ何が起こっているかについて効果的にコミュニケーションを取れていないのです。
+
+**あなたのミッション**:重要な開発について自動的にチーム全体に知らせる、インテリジェントなSlack通知で自動化システムを完成させる。
+
+## 構築するもの
+
+この最終モジュールはCodeCraft Studiosの変革を完成させます。ToolsとPromptsを統合して、CI/CDイベントについてフォーマットされたSlackメッセージを送信するスマート通知システムを作成し、すべてのMCPプリミティブが実際のシナリオでどのように連携するかを実演します。
+
+モジュール1と2の基盤の上に、パズルの最後のピースを追加します:
+- チームチャンネルにメッセージを送信するための**Slackウェブフックツール**
+- CIイベントをインテリジェントにフォーマットする**2つの通知プロンプト**
+- すべてのMCPプリミティブが連携する様子を示す**完全統合**
+
+### スクリーンキャスト: 完全な自動化システム! 🎉
+
+
+
+**最後のピース**:あなたの完全な自動化システムが、EmmaとJakeを悩ませた月曜日の朝のサプライズをどのように防ぐかを見てください!
+
+**あなたが見るもの**:
+- **Claudeのインテリジェントワークフロー** - Claudeがタスクを分解する方法に注目:☐ イベントをチェック → ☐ 通知を送信
+- **リアルタイムMCPツールの動作** - `get_recent_actions_events`が新鮮なCIデータを取得し、`send_slack_notification`がアラートを配信
+- **並列実演** - Slackチャンネルが並行して開かれ、Claudeがメッセージを送信する際にフォーマットされたメッセージが表示される様子
+
+**スマート通知**:Claudeは単にチームをスパムするのではなく、以下を含むプロフェッショナルなアラートを作成します:
+- 🚨 明確な緊急度インジケーターと絵文字
+- **詳細な失敗分析** (test-auth-service ❌, test-api ❌, test-frontend ⏳)
+- パイプライン実行とプルリクエストへの**アクション可能なリンク**
+- **全員が必要とするコンテキスト** - リポジトリ、PR #1 "various improvements"、コミットハッシュ
+
+**なぜこれが重要か**:コミュニケーションギャップの危機を覚えていますか?もうありません!このシステムは、`demo-bad-pr`ブランチでCIが失敗したとき、チーム全体がすぐに知ることを保証します。既に修正された問題のための週末のデバッグセッションはもうありません!
+
+**完全な旅路**:モジュール1のPRの混乱からモジュール3のインテリジェントチーム通知まで - あなたはCodeCraft Studiosのコラボレーション方法を変革するシステムを構築しました。週末戦士が情報を得たチームメイトになります! 🚀
+
+## 学習目標
+
+このモジュールの終了時には、以下を理解できるようになります:
+1. 外部APIをMCP Toolsと統合する方法
+2. 完全なワークフローのためにToolsとPromptsを組み合わせる方法
+3. Slackマークダウンを使用してリッチメッセージをフォーマットする方法
+4. すべてのMCPプリミティブが実際にどのように連携するか
+
+## 前提条件
+
+以前のモジュールのすべてに加えて、以下が必要です:
+- **モジュール1と2の完了** - このモジュールは既存のMCPサーバーを直接拡張します
+- 受信ウェブフックを作成できる**Slackワークスペース**(個人ワークスペースで問題ありません)
+- **REST APIの基本的な理解** - SlackのウェブフックエンドポイントにHTTPリクエストを作成します
+
+## 主要概念
+
+### MCP統合パターン
+
+このモジュールは完全なワークフローを実演します:
+1. **イベント** → GitHub Actionsウェブフック(モジュール2から)
+2. **プロンプト** → イベントを読みやすいメッセージにフォーマット
+3. **ツール** → フォーマットされたメッセージをSlackに送信
+4. **結果** → プロフェッショナルなチーム通知
+
+### Slackマークダウンフォーマット
+
+リッチメッセージのための[Slackのマークダウン](https://api.slack.com/reference/surfaces/formatting)を使用します:
+- 強調のための[`*太字テキスト*`](https://api.slack.com/reference/surfaces/formatting#visual-styles)
+- 詳細のための[`_斜体テキスト_`](https://api.slack.com/reference/surfaces/formatting#visual-styles)
+- 技術情報のための[`` `コードブロック` ``](https://api.slack.com/reference/surfaces/formatting#inline-code)
+- 要約のための[`> 引用テキスト`](https://api.slack.com/reference/surfaces/formatting#quotes)
+- [絵文字](https://api.slack.com/reference/surfaces/formatting#emoji):✅ ❌ 🚀 ⚠️
+- [リンク](https://api.slack.com/reference/surfaces/formatting#linking-urls):``
+
+## プロジェクト構造
+
+```
+slack-notification/
+├── starter/ # 開始地点
+│ ├── server.py # モジュール1+2のコード + TODO
+│ ├── webhook_server.py # モジュール2から
+│ ├── pyproject.toml
+│ └── README.md
+└── solution/ # 完全な実装
+ ├── server.py # 完全なSlack統合
+ ├── webhook_server.py
+ └── README.md
+```
+
+## 実装手順
+
+### ステップ1: Slack統合の設定(10分)
+
+1. Slackウェブフックを作成:
+ - [Slack API Apps](https://api.slack.com/apps)に移動
+ - 新しいアプリを作成 → "From scratch"([アプリ作成ガイド](https://api.slack.com/authentication/basics#creating))
+ - アプリ名:"MCP Course Notifications"
+ - ワークスペースを選択
+ - "Features" → "[Incoming Webhooks](https://api.slack.com/messaging/webhooks)"に移動
+ - [受信ウェブフックを有効化](https://api.slack.com/messaging/webhooks#enable_webhooks)
+ - "Add New Webhook to Workspace"をクリック
+ - チャンネルを選択し、認可([ウェブフック設定ガイド](https://api.slack.com/messaging/webhooks#getting_started))
+ - ウェブフックURLをコピー
+
+2. ウェブフックが動作することをテスト([ウェブフック投稿例](https://api.slack.com/messaging/webhooks#posting_with_webhooks)に従って):
+ ```bash
+ curl -X POST -H 'Content-type: application/json' \
+ --data '{"text":"Hello from MCP Course!"}' \
+ YOUR_WEBHOOK_URL
+ ```
+
+3. 環境変数を設定:
+ ```bash
+ export SLACK_WEBHOOK_URL="https://hooks.slack.com/services/YOUR/WEBHOOK/URL"
+ ```
+
+ **⚠️ セキュリティ注意**: ウェブフックURLは、Slackチャンネルへのメッセージ投稿許可を与える機密秘密です。常に:
+ - 環境変数として保存し、コードにハードコードしない
+ - ウェブフックURLをバージョン管理にコミットしない(.gitignoreに追加)
+ - パスワードのように扱う - このURLを持つ誰でもあなたのチャンネルにメッセージを送信できる
+
+
+
+**セキュリティアラート**: ウェブフックURLは機密認証情報です!あなたのウェブフックURLを持つ誰でもあなたのSlackチャンネルにメッセージを送信できます。常に環境変数として保存し、バージョン管理にコミットしないでください。
+
+
+
+### ステップ2: Slackツールの追加(15分)
+
+動作するウェブフックができたので、モジュール2の既存のserver.pyに新しいMCPツールを追加します。このツールは、ウェブフックURLにHTTPリクエストを作成してSlackに通知を送信することを処理します。
+
+
+
+**注意**: スターターコードにはモジュール1と2のすべての改善(出力制限、ウェブフック処理)が含まれています。新しいSlack統合に焦点を当ててください!
+
+
+
+このツールをserver.pyに追加:
+
+**`send_slack_notification`**:
+- メッセージ文字列パラメータを受け取る
+- 環境変数からウェブフックURLを読み取る
+- SlackウェブフックにPOSTリクエストを送信
+- 成功/失敗メッセージを返す
+- 基本的なエラーケースを処理
+
+```python
+import os
+import requests
+from mcp.types import TextContent
+
+@mcp.tool()
+def send_slack_notification(message: str) -> str:
+ """フォーマットされた通知をチームSlackチャンネルに送信します。"""
+ webhook_url = os.getenv("SLACK_WEBHOOK_URL")
+ if not webhook_url:
+ return "Error: SLACK_WEBHOOK_URL environment variable not set"
+
+ try:
+ # TODO: webhook_urlにPOSTリクエストを送信
+ # TODO: "mrkdwn": trueでJSONペイロードにメッセージを含める
+ # TODO: レスポンスを処理してステータスを返す
+ pass
+ except Exception as e:
+ return f"Error sending message: {str(e)}"
+```
+
+### ステップ3: フォーマットプロンプトの作成(15分)
+
+次に、MCPプロンプトをサーバーに追加します - ここで魔法が起こります!これらのプロンプトはClaudeと連携して、GitHubウェブフックデータを構造化されたSlackメッセージに自動的にフォーマットします。モジュール1から、プロンプトはClaudeが一貫して使用できる再利用可能な指示を提供することを覚えておいてください。
+
+Slackフォーマットされたメッセージを生成する2つのプロンプトを実装:
+
+1. **`format_ci_failure_alert`**:
+ ```python
+ @mcp.prompt()
+ def format_ci_failure_alert() -> str:
+ """CI/CD失敗のSlackアラートを作成します。"""
+ return """このGitHub Actions失敗をSlackメッセージとしてフォーマット:
+
+ このテンプレートを使用:
+ :rotating_light: *CI失敗アラート* :rotating_light:
+
+ CIワークフローが失敗しました:
+ *ワークフロー*: workflow_name
+ *ブランチ*: branch_name
+ *ステータス*: 失敗
+ *詳細を表示*:
+
+ ログを確認し、問題に対処してください。
+
+ Slackマークダウンフォーマットを使用し、チームの迅速なスキャンのために簡潔にしてください。"""
+ ```
+
+2. **`format_ci_success_summary`**:
+ ```python
+ @mcp.prompt()
+ def format_ci_success_summary() -> str:
+ """成功したデプロイメントを祝うSlackメッセージを作成します。"""
+ return """この成功したGitHub Actions実行をSlackメッセージとしてフォーマット:
+
+ このテンプレートを使用:
+ :white_check_mark: *デプロイメント成功* :white_check_mark:
+
+ [リポジトリ名]のデプロイメントが正常に完了しました
+
+ *変更内容:*
+ - 主要機能または修正1
+ - 主要機能または修正2
+
+ *リンク:*
+
+
+ 祝福的でありながら情報的に保ってください。Slackマークダウンフォーマットを使用してください。"""
+ ```
+
+### ステップ4: 完全ワークフローのテスト(10分)
+
+さあ、エキサイティングな部分 - 完全なMCPワークフローのテストです!3つのコンポーネントすべてが連携します:モジュール2からのウェブフックキャプチャ、このモジュールからのプロンプトフォーマット、そしてSlack通知。
+
+1. すべてのサービスを開始(モジュール2と同様ですが、今度はSlack統合付き):
+ ```bash
+ # ターミナル1: ウェブフックサーバーを開始
+ python webhook_server.py
+
+ # ターミナル2: MCPサーバーを開始
+ uv run server.py
+
+ # ターミナル3: Cloudflareトンネルを開始
+ cloudflared tunnel --url http://localhost:8080
+ ```
+
+2. Claude Codeで完全統合をテスト:
+ - トンネルURLで**GitHubウェブフックを設定**(モジュール2と同様)
+ - GitHub Actionsをトリガーするために**変更をプッシュ**
+ - 最近のイベントをチェックし、プロンプトを使用してフォーマットするよう**Claudeに依頼**
+ - Slackツールを使用してフォーマットされたメッセージを**Claudeに送信させる**
+ - Slackチャンネルに通知が表示されることを**確認**
+
+### ステップ5: 統合の検証(5分)
+
+実際のGitHubリポジトリを設定することなく実装をテストできます!GitHubウェブフックイベントをシミュレートするcurlコマンドについては`manual_test.md`を参照してください。
+
+**ウェブフックイベントフローの理解:**
+- ウェブフックサーバー(モジュール2から)がGitHubイベントをキャプチャし、`github_events.json`に保存
+- MCPツールがこのファイルから読み取って最近のCI/CDアクティビティを取得
+- Claudeがフォーマットプロンプトを使用して読みやすいメッセージを作成
+- Slackツールがフォーマットされたメッセージをチームチャンネルに送信
+- これにより完全なパイプラインが作成されます:GitHub → ローカルストレージ → Claude分析 → Slack通知
+
+**クイックテストワークフロー:**
+1. curlを使用してウェブフックサーバーに偽のGitHubイベントを送信
+2. 最近のイベントをチェックしてフォーマットするようClaudeに依頼
+3. フォーマットされたメッセージをSlackに送信
+4. すべてがエンドツーエンドで動作することを確認
+
+**手動テストの代替手段:** GitHub設定なしで完全なテスト体験をするには、`manual_test.md`のステップバイステップcurlコマンドに従ってください。
+
+## Claude Codeでのワークフロー例
+
+```
+ユーザー: "最近のCIイベントをチェックして、失敗があればチームに通知してください"
+
+Claude:
+1. get_recent_actions_events(モジュール2から)を使用
+2. ワークフロー失敗を発見
+3. format_ci_failure_alertプロンプトを使用してメッセージを作成
+4. send_slack_notificationツールを使用して配信
+5. 報告:"#dev-teamチャンネルに失敗アラートを送信しました"
+```
+
+## 期待されるSlackメッセージ出力
+
+**失敗アラート:**
+```
+🚨 *CI失敗アラート* 🚨
+
+CIワークフローが失敗しました:
+*ワークフロー*: CI (Run #42)
+*ブランチ*: feature/slack-integration
+*ステータス*: 失敗
+*詳細を表示*:
+
+ログを確認し、問題に対処してください。
+```
+
+**成功サマリー:**
+```
+✅ *デプロイメント成功* ✅
+
+mcp-courseのデプロイメントが正常に完了しました
+
+*変更内容:*
+- チーム通知システムを追加
+- MCP ToolsとPromptsを統合
+
+*リンク:*
+
+```
+
+## よくある問題
+
+### ウェブフックURLの問題
+- 環境変数が正しく設定されているか確認
+- 統合前にcurlでウェブフックを直接テスト
+- Slackアプリが適切な権限を持っているか確認
+
+### メッセージフォーマット
+- [Slackマークダウン](https://api.slack.com/reference/surfaces/formatting)はGitHubマークダウンと異なります
+- **重要**: 太字には`*text*`を使用(`**text**`ではない)
+- 適切なフォーマットのためにウェブフックペイロードに`"mrkdwn": true`を含める
+- 自動化前に手動でメッセージフォーマットをテスト
+- コミットメッセージ内の特殊文字を適切に処理([フォーマットリファレンス](https://api.slack.com/reference/surfaces/formatting#escaping))
+
+### ネットワークエラー
+- ウェブフックリクエストに基本的なタイムアウト処理を追加([ウェブフックエラー処理](https://api.slack.com/messaging/webhooks#handling_errors))
+- ツールから意味のあるエラーメッセージを返す
+- リクエストが失敗する場合はインターネット接続を確認
+
+## 主要な要点
+
+完全なMCPワークフローを構築し、以下を実演しました:
+- 外部API統合(Slackウェブフック)のための**ツール**
+- インテリジェントメッセージフォーマットのための**プロンプト**
+- すべてのMCPプリミティブが連携する**統合**
+- チームが実際に使用できる**実世界アプリケーション**
+
+これは実用的な開発自動化ツールを構築するためのMCPの力を示しています!
+
+
+
+**重要な学習**: ツール(外部API呼び出し用)とプロンプト(一貫したフォーマット用)を組み合わせた完全なMCPワークフローを構築しました。このツール + プロンプトのパターンは高度なMCP開発の基本であり、他の多くの自動化シナリオに適用できます。
+
+
+
+## 次のステップ
+
+おめでとうございます!Unit 3の最終モジュールを完了し、完全なエンドツーエンド自動化システムを構築しました。3つのモジュールすべてを通じた旅は、以下の実践的な経験を提供しました:
+
+- **モジュール1**: MCPツールとインテリジェントデータ分析
+- **モジュール2**: リアルタイムウェブフックとMCPプロンプト
+- **モジュール3**: 外部API統合とワークフロー完成
+
+### 次にすべきこと:
+1. **完全なシステムをテスト** - 実際のGitHubイベントをトリガーし、完全なパイプラインが動作するのを見る
+2. **カスタマイズを実験** - Slackメッセージフォーマットを変更したり、新しい通知タイプを追加
+3. **Unit 3の結論をレビュー** - 学んだすべてのことを振り返り、次のステップを探求
+4. **成功を共有** - MCPが開発ワークフローを自動化する方法をチームメイトに見せる
+
+MCPでインテリジェント自動化システムを構築するための堅実な基盤を手に入れました!
+
+### 変革が完了しました!
+CodeCraft Studiosは混沌とした開発から円滑な機械へと変わりました。あなたが構築した自動化システムは以下を処理します:
+- レビュアーが変更を理解するのに役立つ**スマートPR説明**
+- 本番環境に到達する前に失敗をキャッチする**リアルタイムCI/CDモニタリング**
+- 全員を自動的に情報提供する**インテリジェントチーム通知**
+
+チームはプロセスの問題と戦う代わりに、素晴らしい製品を構築することに集中できるようになりました。そして、あらゆる自動化チャレンジに適用できる高度なMCPパターンを学びました!
+
+## 追加リソース
+
+- [Slack受信ウェブフックドキュメント](https://api.slack.com/messaging/webhooks)
+- [Slackメッセージフォーマットガイド](https://api.slack.com/reference/surfaces/formatting)
+- [MCPツールドキュメント](https://modelcontextprotocol.io/docs/concepts/tools)
+- [MCPプロンプトガイド](https://modelcontextprotocol.io/docs/concepts/prompts)
\ No newline at end of file
diff --git a/units/ja/unit3_1/conclusion.mdx b/units/ja/unit3_1/conclusion.mdx
new file mode 100644
index 0000000..fae7257
--- /dev/null
+++ b/units/ja/unit3_1/conclusion.mdx
@@ -0,0 +1,42 @@
+# まとめ
+
+おめでとうございます!🎉 Model Context Protocol (MCP)を使用してインテリジェントタグ付けを通じてHugging Faceモデルリポジトリを自動的に拡張するプルリクエストエージェントの構築に成功しました。
+
+あなたが学んだパターン - webhook処理、MCPツール統合、エージェントオーケストレーション、そして本番デプロイメント - は、エージェント構築とMCP構築の基礎的なスキルです。これらの技術はモデルタグ付けをはるかに超えて適用可能であり、人間の能力を拡張するインテリジェントシステムを構築するための強力なアプローチを表しています。
+
+## 構築したもの
+
+このユニット全体を通じて、4つの主要なコンポーネントを持つ完全な自動化システムを作成しました:
+
+- **MCPサーバー** (`mcp_server.py`) - Hub API統合を備えたFastMCPベースのサーバー
+- **MCPクライアント** (エージェント) - 言語モデル推論によるインテリジェントオーケストレーション
+- **Webhookリスナー** (FastAPI) - Hugging Face Hubからのリアルタイムイベント処理
+- **テストインターフェース** (Gradio) - 開発・監視ダッシュボード
+
+## 次のステップ
+
+### 学習を続ける
+- 高度なMCPパターンとツールを探索する
+- 他の自動化フレームワークとAIシステムアーキテクチャを学ぶ
+- マルチエージェントシステムとツールコンポジションについて学ぶ
+
+### より多くのエージェントを構築する
+- 自分のプロジェクト用のドメイン固有の自動化ツールを開発する
+- 他の種類のwebhook(例:モデルアップロード、モデルダウンロードなど)を試す
+- 異なるワークフローを実験する
+
+### あなたの作業を共有する
+- コミュニティのためにエージェントをオープンソース化する
+- 学習内容と自動化パターンについて書く
+- MCPエコシステムに貢献する
+
+### インパクトを拡大する
+- 複数のリポジトリや組織にエージェントをデプロイする
+- より洗練された自動化ワークフローを構築する
+- AI自動化の商用アプリケーションを探索する
+
+
+
+あなたの経験を文書化し、コミュニティと共有することを検討してください!MCPを学習から本番エージェント構築への旅は、他の人々がAI自動化を探索するのに役立つでしょう。
+
+
diff --git a/units/ja/unit3_1/creating-the-mcp-server.mdx b/units/ja/unit3_1/creating-the-mcp-server.mdx
new file mode 100644
index 0000000..107443f
--- /dev/null
+++ b/units/ja/unit3_1/creating-the-mcp-server.mdx
@@ -0,0 +1,336 @@
+# MCPサーバーの作成
+
+MCPサーバーはプルリクエストエージェントの心臓部です。エージェントがHugging Face Hub、特にモデルリポジトリのタグの読み取りと更新に使用するツールを提供します。このセクションでは、FastMCPとHugging Face Hub Python SDKを使用してサーバーを構築します。
+
+## MCPサーバーアーキテクチャの理解
+
+MCPサーバーは2つの重要なツールを提供します:
+
+| ツール | 説明 |
+| --- | --- |
+| `get_current_tags` | モデルリポジトリから既存のタグを取得 |
+| `add_new_tag` | プルリクエスト経由でリポジトリに新しいタグを追加 |
+
+これらのツールは、Hub APIとのやり取りの複雑さを抽象化し、エージェントが操作するためのクリーンなインターフェースを提供します。
+
+
+
+## 完全なMCPサーバー実装
+
+`mcp_server.py`ファイルを段階的に作成しましょう。各コンポーネントとそれらがどのように連携するかを理解できるよう、段階的に構築していきます。
+
+### 1. インポートと設定
+
+まず、必要なすべてのインポートと設定を行います。
+
+```python
+#!/usr/bin/env python3
+"""
+Simplified MCP Server for HuggingFace Hub Tagging Operations using FastMCP
+"""
+
+import os
+import json
+from fastmcp import FastMCP
+from huggingface_hub import HfApi, model_info, ModelCard, ModelCardData
+from huggingface_hub.utils import HfHubHTTPError
+from dotenv import load_dotenv
+
+load_dotenv()
+```
+
+上記のインポートにより、MCPサーバーの構築に必要なすべてのものが揃います。`FastMCP`はサーバーフレームワークを提供し、`huggingface_hub`のインポートはモデルリポジトリとのやり取りに必要なツールを提供します。
+
+`load_dotenv()`の呼び出しは、`.env`ファイルから環境変数を自動的に読み込み、開発中にAPIトークンなどの秘密情報を管理しやすくします。
+
+
+
+uvを使用している場合、プロジェクトのルートに`.env`ファイルを作成でき、`uv run`を使用してサーバーを実行する場合は`load_dotenv()`を使用する必要はありません。
+
+
+
+次に、必要な認証情報でサーバーを設定し、FastMCPインスタンスを作成します:
+
+```python
+# Configuration
+HF_TOKEN = os.getenv("HF_TOKEN")
+
+# Initialize HF API client
+hf_api = HfApi(token=HF_TOKEN) if HF_TOKEN else None
+
+# Create the FastMCP server
+mcp = FastMCP("hf-tagging-bot")
+```
+
+この設定ブロックは3つの重要なことを行います:
+1. 環境変数からHugging Faceトークンを取得
+2. 認証されたAPIクライアントを作成(トークンが利用できる場合のみ)
+3. 説明的な名前でFastMCPサーバーを初期化
+
+`hf_api`の条件的な作成により、トークンなしでもサーバーを起動できるため、基本的な構造のテストに役立ちます。
+
+### 2. 現在のタグ取得ツール
+
+最初のツール - `get_current_tags`を実装しましょう。このツールは、モデルリポジトリから既存のタグを取得します:
+
+```python
+@mcp.tool()
+def get_current_tags(repo_id: str) -> str:
+ """Get current tags from a HuggingFace model repository"""
+ print(f"🔧 get_current_tags called with repo_id: {repo_id}")
+
+ if not hf_api:
+ error_result = {"error": "HF token not configured"}
+ json_str = json.dumps(error_result)
+ print(f"❌ No HF API token - returning: {json_str}")
+ return json_str
+```
+
+この関数は検証から始まります - 認証されたAPIクライアントがあるかを確認します。PythonオブジェクトではなくJSON文字列を返すことに注意してください。これはMCP通信において重要です。
+
+
+
+すべてのMCPツールは、Pythonオブジェクトではなく文字列を返す必要があります。そのため、結果をJSON文字列に変換するために`json.dumps()`を使用します。これにより、MCPサーバーとクライアント間の信頼性のあるデータ交換が保証されます。
+
+
+
+`get_current_tags`関数のメインロジックを続けましょう:
+
+```python
+ try:
+ print(f"📡 Fetching model info for: {repo_id}")
+ info = model_info(repo_id=repo_id, token=HF_TOKEN)
+ current_tags = info.tags if info.tags else []
+ print(f"🏷️ Found {len(current_tags)} tags: {current_tags}")
+
+ result = {
+ "status": "success",
+ "repo_id": repo_id,
+ "current_tags": current_tags,
+ "count": len(current_tags),
+ }
+ json_str = json.dumps(result)
+ print(f"✅ get_current_tags returning: {json_str}")
+ return json_str
+
+ except Exception as e:
+ print(f"❌ Error in get_current_tags: {str(e)}")
+ error_result = {"status": "error", "repo_id": repo_id, "error": str(e)}
+ json_str = json.dumps(error_result)
+ print(f"❌ get_current_tags error returning: {json_str}")
+ return json_str
+```
+
+この実装は明確なパターンに従っています:
+1. **データを取得** - Hugging Face Hub APIを使用
+2. **レスポンスを処理** - タグ情報を抽出
+3. **結果を構造化** - 一貫したJSON形式で
+4. **エラーを適切に処理** - 詳細なエラーメッセージとともに
+
+
+
+広範囲なログ出力は過剰に見えるかもしれませんが、サーバー実行時のデバッグと監視に役立ちます。アプリケーションはHubからのイベントに自律的に反応するため、リアルタイムでログを確認できないことを覚えておいてください。
+
+
+
+### 3. 新しいタグ追加ツール
+
+より複雑なツール - `add_new_tag`に進みましょう。このツールは、プルリクエストを作成してリポジトリに新しいタグを追加します。初期設定と検証から始めましょう:
+
+```python
+@mcp.tool()
+def add_new_tag(repo_id: str, new_tag: str) -> str:
+ """Add a new tag to a HuggingFace model repository via PR"""
+ print(f"🔧 add_new_tag called with repo_id: {repo_id}, new_tag: {new_tag}")
+
+ if not hf_api:
+ error_result = {"error": "HF token not configured"}
+ json_str = json.dumps(error_result)
+ print(f"❌ No HF API token - returning: {json_str}")
+ return json_str
+```
+
+最初のツールと同様に、検証から始めます。次に、現在のリポジトリ状態を取得して、タグが既に存在するかを確認しましょう:
+
+```python
+ try:
+ # Get current model info and tags
+ print(f"📡 Fetching current model info for: {repo_id}")
+ info = model_info(repo_id=repo_id, token=HF_TOKEN)
+ current_tags = info.tags if info.tags else []
+ print(f"🏷️ Current tags: {current_tags}")
+
+ # Check if tag already exists
+ if new_tag in current_tags:
+ print(f"⚠️ Tag '{new_tag}' already exists in {current_tags}")
+ result = {
+ "status": "already_exists",
+ "repo_id": repo_id,
+ "tag": new_tag,
+ "message": f"Tag '{new_tag}' already exists",
+ }
+ json_str = json.dumps(result)
+ print(f"🏷️ add_new_tag (already exists) returning: {json_str}")
+ return json_str
+```
+
+このセクションは重要な原則を示しています:**行動する前に検証する**。不要なプルリクエストの作成を避けるため、タグが既に存在するかを確認します。
+
+
+
+変更を行う前に必ず現在の状態を確認してください。これにより、重複作業を防ぎ、より良いユーザーフィードバックを提供できます。特にプルリクエストを作成する際は重要で、重複したプルリクエストはリポジトリを乱雑にする可能性があります。
+
+
+
+次に、更新されたタグリストを準備し、モデルカードを処理します:
+
+```python
+ # Add the new tag to existing tags
+ updated_tags = current_tags + [new_tag]
+ print(f"🆕 Will update tags from {current_tags} to {updated_tags}")
+
+ # Create model card content with updated tags
+ try:
+ # Load existing model card
+ print(f"📄 Loading existing model card...")
+ card = ModelCard.load(repo_id, token=HF_TOKEN)
+ if not hasattr(card, "data") or card.data is None:
+ card.data = ModelCardData()
+ except HfHubHTTPError:
+ # Create new model card if none exists
+ print(f"📄 Creating new model card (none exists)")
+ card = ModelCard("")
+ card.data = ModelCardData()
+
+ # Update tags - create new ModelCardData with updated tags
+ card_dict = card.data.to_dict()
+ card_dict["tags"] = updated_tags
+ card.data = ModelCardData(**card_dict)
+```
+
+このセクションはモデルカード管理を処理します。最初に既存のモデルカードを読み込もうとしますが、存在しない場合は新しいものを作成します。これにより、ツールが空のリポジトリでも動作することが保証されます。
+
+モデルカード(`README.md`)には、タグを含むリポジトリメタデータが含まれています。モデルカードデータを更新してプルリクエストを作成することで、メタデータ変更のための標準的なHugging Faceワークフローに従っています。
+
+次に、プルリクエストの作成 - ツールのメイン部分です:
+
+```python
+ # Create a pull request with the updated model card
+ pr_title = f"Add '{new_tag}' tag"
+ pr_description = f"""
+## Add tag: {new_tag}
+
+This PR adds the `{new_tag}` tag to the model repository.
+
+**Changes:**
+- Added `{new_tag}` to model tags
+- Updated from {len(current_tags)} to {len(updated_tags)} tags
+
+**Current tags:** {", ".join(current_tags) if current_tags else "None"}
+**New tags:** {", ".join(updated_tags)}
+
+🤖 This is a pull request created by the Hugging Face Hub Tagging Bot.
+"""
+
+ print(f"🚀 Creating PR with title: {pr_title}")
+```
+
+何が変更されるか、なぜ変更されるかを説明する詳細なプルリクエストの説明を作成します。この透明性は、プルリクエストを確認するリポジトリメンテナにとって重要です。
+
+
+
+明確で詳細なプルリクエストの説明は、自動化されたプルリクエストには不可欠です。リポジトリメンテナが何が起こっているかを理解し、変更をマージするかどうかについて情報に基づいた決定を下すのに役立ちます。
+
+また、プルリクエストが自動化ツールによって作成されたことを明確に述べることも良い慣行です。これにより、リポジトリメンテナがプルリクエストをどのように処理するかを理解できます。
+
+
+
+最後に、コミットとプルリクエストを作成します:
+
+```python
+ # Create commit with updated model card using CommitOperationAdd
+ from huggingface_hub import CommitOperationAdd
+
+ commit_info = hf_api.create_commit(
+ repo_id=repo_id,
+ operations=[
+ CommitOperationAdd(
+ path_in_repo="README.md", path_or_fileobj=str(card).encode("utf-8")
+ )
+ ],
+ commit_message=pr_title,
+ commit_description=pr_description,
+ token=HF_TOKEN,
+ create_pr=True,
+ )
+
+ # Extract PR URL from commit info
+ pr_url_attr = commit_info.pr_url
+ pr_url = pr_url_attr if hasattr(commit_info, "pr_url") else str(commit_info)
+
+ print(f"✅ PR created successfully! URL: {pr_url}")
+
+ result = {
+ "status": "success",
+ "repo_id": repo_id,
+ "tag": new_tag,
+ "pr_url": pr_url,
+ "previous_tags": current_tags,
+ "new_tags": updated_tags,
+ "message": f"Created PR to add tag '{new_tag}'",
+ }
+ json_str = json.dumps(result)
+ print(f"✅ add_new_tag success returning: {json_str}")
+ return json_str
+```
+
+`create_pr=True`を指定した`create_commit`関数が自動化の鍵です。更新された`README.md`ファイルでコミットを作成し、自動的にレビュー用のプルリクエストを開きます。
+
+この複雑な操作のエラーハンドリングを忘れずに:
+
+```python
+ except Exception as e:
+ print(f"❌ Error in add_new_tag: {str(e)}")
+ print(f"❌ Error type: {type(e)}")
+ import traceback
+ print(f"❌ Traceback: {traceback.format_exc()}")
+
+ error_result = {
+ "status": "error",
+ "repo_id": repo_id,
+ "tag": new_tag,
+ "error": str(e),
+ }
+ json_str = json.dumps(error_result)
+ print(f"❌ add_new_tag error returning: {json_str}")
+ return json_str
+```
+
+包括的なエラーハンドリングには完全なトレースバックが含まれており、問題が発生したときのデバッグに非常に価値があります。
+
+ログメッセージの絵文字は馬鹿げているように見えるかもしれませんが、ログのスキャンをはるかに高速にします。関数呼び出しに🔧、APIリクエストに📡、成功に✅、エラーに❌を使用することで、探しているものをすばやく見つけるのに役立つ視覚的パターンを作成します。
+
+
+
+このアプリケーションを構築している間、誤って無限のプルリクエストループを作成しやすいです。これは、`create_pr=True`を指定した`create_commit`関数が、すべてのコミットに対してプルリクエストを作成するためです。プルリクエストがマージされない場合、`create_commit`関数が再度、再度、再度呼び出されます...
+
+これを防ぐためのチェックを追加しましたが、注意すべき点です。
+
+
+
+## 次のステップ
+
+堅牢なタグ付けツールを備えたMCPサーバーが実装できたので、次に必要なことは:
+
+1. **MCPクライアントの作成** - エージェントとMCPサーバー間のインターフェースを構築
+2. **Webhook処理の実装** - Hubディスカッションイベントをリッスン
+3. **エージェントロジックの統合** - WebhookとMCPツール呼び出しを接続
+4. **完全なシステムのテスト** - エンドツーエンド機能の検証
+
+次のセクションでは、Webhook処理機能がこれらのツールとインテリジェントにやり取りできるようにするMCPクライアントを作成します。
+
+
+
+MCPサーバーは、メインアプリケーションとは別のプロセスとして実行されます。この分離により、よりよいエラーハンドリングが提供され、複数のクライアントやアプリケーションでサーバーを再利用できるようになります。
+
+
\ No newline at end of file
diff --git a/units/ja/unit3_1/introduction.mdx b/units/ja/unit3_1/introduction.mdx
new file mode 100644
index 0000000..e4d2fcf
--- /dev/null
+++ b/units/ja/unit3_1/introduction.mdx
@@ -0,0 +1,108 @@
+# Hugging Face Hub上でプルリクエストエージェントを構築
+
+MCPコースのUnit 3へようこそ!
+
+このユニットでは、ディスカッションやコメントに基づいてHugging Faceモデルリポジトリを自動的にタグ付けするプルリクエストエージェントを構築します。この実世界のアプリケーションでは、Model Context Protocol (MCP) をwebhookリスナーや自動ワークフローと統合する方法を実演します。
+
+
+
+このユニットでは、MCPサーバーがHugging Face Hubからのリアルタイムイベントに応答し、リポジトリメタデータを改善するプルリクエストを自動的に作成する実世界のユースケースを紹介します。
+
+
+
+## 学ぶ内容
+
+このユニットでは、以下のことを学習します:
+
+- Hugging Face Hub APIと連携するMCPサーバーの作成
+- ディスカッションイベントに応答するwebhookリスナーの実装
+- モデルリポジトリの自動タグ付けワークフローの設定
+- Hugging Face Spacesへの完全なwebhook駆動アプリケーションのデプロイ
+
+このユニットの終わりには、ディスカッションを監視し、プルリクエストを通じてリポジトリメタデータを自動的に改善できる動作するプルリクエストエージェントを持つことになります。
+
+## 前提条件
+
+このユニットを進める前に、以下のことを確認してください:
+
+- Unit 1およびUnit 2を完了している、またはMCPの概念に精通している
+- Python、FastAPI、webhookの概念に慣れている
+- Hugging Face Hubワークフローとプルリクエストの基本的な理解がある
+- 以下を含む開発環境を持っている:
+ - Python 3.11以上
+ - APIアクセス権限のあるHugging Faceアカウント
+
+## プルリクエストエージェントプロジェクト
+
+4つの主要コンポーネントで構成されるタグ付けエージェントを構築します:MCPサーバー、webhookリスナー、エージェントロジック、およびデプロイメントインフラストラクチャ。エージェントは、ディスカッションとコメントに基づいてモデルリポジトリにタグを付けることができます。これにより、モデル作成者は使用準備済みのプルリクエストを受け取ることで、手動でリポジトリにタグ付けする必要がなくなり、時間を節約できるはずです。
+
+
+
+上の図では、モデルタグを読み取りおよび更新できるMCPサーバーがあります。Hugging Face Hubからwebhookをリッスンできるwebhookリスナーがあります。ディスカッションとコメントを分析し、モデルタグを更新するプルリクエストを作成できるエージェントがあります。MCPサーバーをHugging Face Spacesにデプロイできるデプロイメントインフラストラクチャがあります。
+
+### プロジェクト概要
+
+このアプリケーションを構築するには、以下のファイルが必要です:
+
+| ファイル | 目的 | 説明 |
+|------|---------|-------------|
+| `mcp_server.py` | **コアMCPサーバー** | モデルタグの読み取りと更新のためのツールを持つFastMCPベースのサーバー |
+| `app.py` | **Webhookリスナー & エージェント** | webhookを受信し、ディスカッションを処理し、プルリクエストを作成するFastAPIアプリ |
+| `requirements.txt` | **依存関係** | FastMCP、FastAPI、huggingface-hubを含むPythonパッケージ |
+| `pyproject.toml` | **プロジェクト設定** | uv依存関係管理を使用したモダンなPythonパッケージング |
+| `Dockerfile` | **デプロイメント** | Hugging Face Spaces用のコンテナ設定 |
+| `env.example` | **設定テンプレート** | 必要な環境変数とシークレット |
+| `cleanup.py` | **ユーティリティ** | 開発とテストのクリーンアップ用ヘルパースクリプト |
+
+これらのファイルを一つずつ確認し、その目的を理解しましょう。
+
+### MCPサーバー (`mcp_server.py`)
+
+アプリケーションの中核 - 以下のためのツールを提供するFastMCPサーバー:
+- モデルリポジトリから現在のタグを読み取り
+- Hubへのプルリクエストを通じて新しいタグを追加
+- エラーハンドリングと検証
+
+ここでMCPサーバーを実装し、このプロジェクトの作業の大部分を行います。GradioアプリとFastAPIアプリは、MCPサーバーとwebhookリスナーをテストするために使用され、これらは使用準備が整っています。
+
+### Webhook統合
+
+[Hugging Face Webhooks Guide](https://huggingface.co/docs/hub/webhooks-guide-discussion-bot)に従って、エージェントは:
+- ディスカッションコメントイベントをリッスン
+- セキュリティのためのwebhook署名を検証
+- メンションとタグ提案を処理
+- プルリクエストを自動的に作成
+
+### エージェント機能
+
+エージェントはディスカッション内容を分析して:
+- 明示的なタグメンション(`tag: pytorch`、`#transformers`)を抽出
+- 自然言語から暗黙的なタグを認識
+- 既知のML/AIカテゴリに対してタグを検証
+- 適切なプルリクエスト説明を生成
+
+### デプロイメント & 本番環境
+
+- Hugging Face Spacesへのコンテナ化されたデプロイメント
+- シークレット用の環境変数管理
+- webhook応答のためのバックグラウンドタスク処理
+- テストと監視のためのGradioインターフェース
+
+## Webhook統合概要
+
+プルリクエストエージェントは、Hugging Faceのディスカッションボットで使用されているのと同じwebhookインフラストラクチャを活用します。webhookがリアルタイム応答を可能にする方法は以下の通りです:
+
+
+
+webhookフローは以下のように動作します:
+1. **イベントトリガー**: ユーザーがモデルリポジトリディスカッションでコメントを作成
+2. **Webhook配信**: Hugging Faceがエンドポイントへのリクエストを送信
+3. **認証**: セキュリティのためにwebhookシークレットを検証
+4. **処理**: エージェントがタグ提案についてコメントを分析
+5. **アクション**: 関連するタグが見つかった場合、プルリクエストを作成
+6. **応答**: プルリクエスト作成がバックグラウンドで実行される間、webhookは即座に応答を返す
+
+## さあ始めましょう!
+
+Hugging Faceリポジトリを自動的に改善できる本番環境対応のプルリクエストエージェントを構築する準備はできましたか?プロジェクト構造を設定し、MCPサーバーの実装を理解することから始めましょう。
+
diff --git a/units/ja/unit3_1/mcp-client.mdx b/units/ja/unit3_1/mcp-client.mdx
new file mode 100644
index 0000000..95f2de5
--- /dev/null
+++ b/units/ja/unit3_1/mcp-client.mdx
@@ -0,0 +1,370 @@
+# MCPクライアント
+
+タグ付けツールを持つMCPサーバーができたので、次はこれらのツールと相互作用できるクライアントを作成する必要があります。MCPクライアントは、webhookハンドラーとMCPサーバーの間のブリッジとして機能し、エージェントがHubのタグ付け機能を使用できるようにします。
+
+このプロジェクトでは、APIとGradioアプリの両方を構築します。APIはMCPサーバーとwebhookリスナーのテストに使用し、GradioアプリはシミュレートされたwebhookイベントでMCPクライアントをテストするために使用します。
+
+
+
+教育目的で、MCPサーバーとMCPクライアントを同じリポジトリに構築します。実際のアプリケーションでは、MCPサーバーとMCPクライアント用に別々のリポジトリを使用することが多いでしょう。実際、これらのコンポーネントのうち片方だけを構築する場合もあります。
+
+
+
+## MCPクライアントアーキテクチャの理解
+
+我々のアプリケーションでは、MCPクライアントはメインのFastAPIアプリケーション(`app.py`)に統合されています。これによりMCPサーバーへの接続を作成・管理し、ツール実行のためのシームレスなインターフェースを提供します。
+
+
+
+## エージェントベースのMCPクライアント
+
+MCP対応が組み込まれた`huggingface_hub`のAgentクラスを使用します。これにより、言語モデル機能とMCPツール統合を単一のコンポーネントで提供できます。
+
+### 1. エージェント設定
+
+エージェント設定のセットアップから始めて、各コンポーネントを理解しましょう:
+
+```python
+from huggingface_hub.inference._mcp.agent import Agent
+from typing import Optional, Literal
+
+# Configuration
+HF_TOKEN = os.getenv("HF_TOKEN")
+HF_MODEL = os.getenv("HF_MODEL", "microsoft/DialoGPT-medium")
+DEFAULT_PROVIDER: Literal["hf-inference"] = "hf-inference"
+
+# Global agent instance
+agent_instance: Optional[Agent] = None
+```
+
+必要なインポートと設定から始めます。グローバルな`agent_instance`変数により、エージェントを一度だけ作成し、複数のリクエスト間で再利用することが保証されます。エージェントの初期化にはコストがかかるため、これはパフォーマンスにとって重要です。
+
+次に、エージェントを作成・管理する関数を実装しましょう:
+
+```python
+async def get_agent():
+ """Get or create Agent instance"""
+ print("🤖 get_agent() called...")
+ global agent_instance
+ if agent_instance is None and HF_TOKEN:
+ print("🔧 Creating new Agent instance...")
+ print(f"🔑 HF_TOKEN present: {bool(HF_TOKEN)}")
+ print(f"🤖 Model: {HF_MODEL}")
+ print(f"🔗 Provider: {DEFAULT_PROVIDER}")
+```
+
+この関数は、すでにエージェントインスタンスを持っているかどうかをチェックすることから始まります。このシングルトンパターンは、不要な再作成を防ぎ、一貫した状態を保証します。
+
+エージェントの作成を続けましょう:
+
+```python
+ try:
+ agent_instance = Agent(
+ model=HF_MODEL,
+ provider=DEFAULT_PROVIDER,
+ api_key=HF_TOKEN,
+ servers=[
+ {
+ "type": "stdio",
+ "config": {
+ "command": "python",
+ "args": ["mcp_server.py"],
+ "cwd": ".",
+ "env": {"HF_TOKEN": HF_TOKEN} if HF_TOKEN else {},
+ },
+ }
+ ],
+ )
+ print("✅ Agent instance created successfully")
+ print("🔧 Loading tools...")
+ await agent_instance.load_tools()
+ print("✅ Tools loaded successfully")
+ except Exception as e:
+ print(f"❌ Error creating/loading agent: {str(e)}")
+ agent_instance = None
+```
+
+ここが重要な部分です!Agent設定を分解してみましょう:
+
+**エージェントパラメータ:**
+- `model`: ツール使用について推論する言語モデル
+- `provider`: モデルへのアクセス方法(Hugging Face Inference Providers)
+- `api_key`: Hugging Face APIキー
+
+**MCPサーバー接続:**
+- `type: "stdio"`: 標準入出力を介してMCPサーバーに接続
+- `command: "python"`: MCPサーバーをPythonサブプロセスとして実行
+- `args: ["mcp_server.py"]`: 実行するスクリプトファイル
+- `env`: HF_TOKENをサーバープロセスに渡す
+
+
+
+`stdio`接続タイプは、エージェントがMCPサーバーをサブプロセスとして開始し、標準入出力を通じて通信することを意味します。これは開発や単一マシンでのデプロイメントに最適です。
+
+
+
+`load_tools()`の呼び出しは重要です - これはMCPサーバーから利用可能なツールを発見し、エージェントの推論エンジンがアクセスできるようにします。
+
+これで、適切なエラーハンドリングとログ出力を持つエージェント管理関数が完成しました。
+
+## ツールの発見と使用
+
+エージェントが作成されツールがロードされると、MCPツールを自動的に発見・使用できます。これがAgentアプローチの真の力が発揮される部分です。
+
+### 利用可能なツール
+
+エージェントは我々のMCPツールを自動的に発見します:
+- `get_current_tags(repo_id: str)` - 既存のリポジトリタグを取得
+- `add_new_tag(repo_id: str, new_tag: str)` - プルリクエスト経由で新しいタグを追加
+
+エージェントはこれらのツールを盲目的に呼び出すのではなく、与えられたプロンプトに基づいて、いつどのように使用するかを推論します。
+
+### ツール実行の例
+
+エージェントがツールをインテリジェントに使用する方法は以下のとおりです:
+
+```python
+# Example of how the agent would use tools
+async def example_tool_usage():
+ agent = await get_agent()
+
+ if agent:
+ # The agent can reason about which tools to use
+ response = await agent.run(
+ "Check the current tags for microsoft/DialoGPT-medium and add the tag 'conversational-ai' if it's not already present"
+ )
+ print(response)
+```
+
+エージェントに自然言語の指示を与えると、以下のことを理解することに注目してください:
+1. まず`get_current_tags`を呼び出して既存のタグを確認
+2. `conversational-ai`がすでに存在するかチェック
+3. 存在しない場合、`add_new_tag`を呼び出して追加
+4. 実行した内容の要約を提供
+
+これはツールを直接呼び出すよりもはるかにインテリジェントです!
+
+## webhook処理との統合
+
+次に、MCPクライアントがwebhook処理パイプラインにどのように統合されるかを見てみましょう。ここですべてが統合されます。
+
+### 1. タグ抽出と処理
+
+webhookイベントを処理してMCPエージェントを使用するメイン関数は以下のとおりです:
+
+```python
+async def process_webhook_comment(webhook_data: Dict[str, Any]):
+ """Process webhook to detect and add tags"""
+ print("🏷️ Starting process_webhook_comment...")
+
+ try:
+ comment_content = webhook_data["comment"]["content"]
+ discussion_title = webhook_data["discussion"]["title"]
+ repo_name = webhook_data["repo"]["name"]
+
+ # Extract potential tags from the comment and discussion title
+ comment_tags = extract_tags_from_text(comment_content)
+ title_tags = extract_tags_from_text(discussion_title)
+ all_tags = list(set(comment_tags + title_tags))
+
+ print(f"🔍 All unique tags: {all_tags}")
+
+ if not all_tags:
+ return ["No recognizable tags found in the discussion."]
+```
+
+この最初の部分では、コメント内容とディスカッションタイトルの両方からタグを抽出・結合します。setを使用して、両方の場所に現れるタグを重複除去します。
+
+
+
+コメントとディスカッションタイトルの両方を処理することで、関連するタグをキャッチする可能性が高まります。ユーザーは「Missing pytorch tag」のようにタイトルでタグに言及したり、「This needs #transformers」のようにコメントで言及したりする可能性があります。
+
+
+
+次に、エージェントを取得し各タグを処理します:
+
+```python
+ # Get agent instance
+ agent = await get_agent()
+ if not agent:
+ return ["Error: Agent not configured (missing HF_TOKEN)"]
+
+ # Process each tag
+ result_messages = []
+ for tag in all_tags:
+ try:
+ # Use agent to process the tag
+ prompt = f"""
+ For the repository '{repo_name}', check if the tag '{tag}' already exists.
+ If it doesn't exist, add it via a pull request.
+
+ Repository: {repo_name}
+ Tag to check/add: {tag}
+ """
+
+ print(f"🤖 Processing tag '{tag}' for repo '{repo_name}'")
+ response = await agent.run(prompt)
+
+ # Parse agent response for success/failure
+ if "success" in response.lower():
+ result_messages.append(f"✅ Tag '{tag}' processed successfully")
+ else:
+ result_messages.append(f"⚠️ Issue with tag '{tag}': {response}")
+
+ except Exception as e:
+ error_msg = f"❌ Error processing tag '{tag}': {str(e)}"
+ print(error_msg)
+ result_messages.append(error_msg)
+
+ return result_messages
+```
+
+ここでの重要な洞察は、各タグに対して明確で構造化されたプロンプトをエージェントに与えることです。エージェントは次のことを行います:
+1. まず現在のタグをチェックする必要があることを理解
+2. 追加したい新しいタグと比較
+3. 必要に応じてプルリクエストを作成
+4. その行動の要約を返す
+
+このアプローチは、ツールオーケストレーションの複雑さを自動的に処理します。
+
+### 2. タグ抽出ロジック
+
+MCP処理に供給されるタグ抽出ロジックを調べてみましょう:
+
+```python
+import re
+from typing import List
+
+# Recognized ML/AI tags for validation
+RECOGNIZED_TAGS = {
+ "pytorch", "tensorflow", "jax", "transformers", "diffusers",
+ "text-generation", "text-classification", "question-answering",
+ "text-to-image", "image-classification", "object-detection",
+ "fill-mask", "token-classification", "translation", "summarization",
+ "feature-extraction", "sentence-similarity", "zero-shot-classification",
+ "image-to-text", "automatic-speech-recognition", "audio-classification",
+ "voice-activity-detection", "depth-estimation", "image-segmentation",
+ "video-classification", "reinforcement-learning", "tabular-classification",
+ "tabular-regression", "time-series-forecasting", "graph-ml", "robotics",
+ "computer-vision", "nlp", "cv", "multimodal",
+}
+```
+
+この厳選された認識タグのリストは、関連するML/AIタグに焦点を当て、リポジトリに不適切なタグが追加されることを回避するのに役立ちます。
+
+抽出関数自体を見てみましょう:
+
+```python
+def extract_tags_from_text(text: str) -> List[str]:
+ """Extract potential tags from discussion text"""
+ text_lower = text.lower()
+ explicit_tags = []
+
+ # Pattern 1: "tag: something" or "tags: something"
+ tag_pattern = r"tags?:\s*([a-zA-Z0-9-_,\s]+)"
+ matches = re.findall(tag_pattern, text_lower)
+ for match in matches:
+ tags = [tag.strip() for tag in match.split(",")]
+ explicit_tags.extend(tags)
+
+ # Pattern 2: "#hashtag" style
+ hashtag_pattern = r"#([a-zA-Z0-9-_]+)"
+ hashtag_matches = re.findall(hashtag_pattern, text_lower)
+ explicit_tags.extend(hashtag_matches)
+
+ # Pattern 3: Look for recognized tags mentioned in natural text
+ mentioned_tags = []
+ for tag in RECOGNIZED_TAGS:
+ if tag in text_lower:
+ mentioned_tags.append(tag)
+
+ # Combine and deduplicate
+ all_tags = list(set(explicit_tags + mentioned_tags))
+
+ # Filter to only include recognized tags or explicitly mentioned ones
+ valid_tags = []
+ for tag in all_tags:
+ if tag in RECOGNIZED_TAGS or tag in explicit_tags:
+ valid_tags.append(tag)
+
+ return valid_tags
+```
+
+この関数は複数の戦略を使用してタグを抽出します:
+
+1. **明示的パターン**: "tags: pytorch, transformers" または "tag: nlp"
+2. **ハッシュタグ**: "#pytorch #nlp"
+3. **自然な言及**: "This transformers model does text-generation"
+
+検証ステップにより、適切なタグのみを提案し、スパムや無関係なタグが追加されることを防ぎます。
+
+
+## パフォーマンスの考慮事項
+
+本番環境のMCPクライアントを構築する際、レスポンシブなwebhook処理を維持するためにパフォーマンスは重要です。我々が行った考慮事項のいくつかを見てみましょう。
+
+### 1. エージェントシングルトンパターン
+
+エージェントは一度作成され再利用されることで、以下を回避します:
+- 繰り返されるMCPサーバー起動のオーバーヘッド
+- ツールロードの遅延
+- 接続確立のコスト
+
+このパターンは、迅速に応答する必要があるwebhookハンドラーにとって不可欠です。
+
+### 2. 非同期処理
+
+すべてのMCP操作は以下の理由で非同期です:
+- 複数のwebhookリクエストを同時に処理
+- メインのFastAPIスレッドのブロックを回避
+- レスポンシブなwebhook応答を提供
+
+非同期の性質により、webhookハンドラーはバックグラウンドでタグを処理しながら新しいリクエストを受け入れることができます。
+
+### 3. バックグラウンドタスク処理
+
+FastAPIには、バックグラウンドでタスクを実行するために使用できる組み込みの`BackgroundTasks`クラスがあります。これは、メインスレッドをブロックすることなく長時間実行されるタスクを実行するのに便利です。
+
+```python
+from fastapi import BackgroundTasks
+
+@app.post("/webhook")
+async def webhook_handler(request: Request, background_tasks: BackgroundTasks):
+ """Handle webhook and process in background"""
+
+ # Validate webhook quickly
+ if request.headers.get("X-Webhook-Secret") != WEBHOOK_SECRET:
+ return {"error": "Invalid secret"}
+
+ webhook_data = await request.json()
+
+ # Process in background to return quickly
+ background_tasks.add_task(process_webhook_comment, webhook_data)
+
+ return {"status": "accepted"}
+```
+
+このパターンにより、複雑なタグ処理をバックグラウンドで実行しながら、webhook応答を高速(1秒未満)に保つことができます。
+
+
+
+webhookエンドポイントは10秒以内に応答する必要があります。そうでないと、プラットフォームはタイムアウトしたと見なす可能性があります。バックグラウンドタスクを使用することで、複雑な処理を非同期で処理しながら、常に迅速に応答できることが保証されます。
+
+
+
+## 次のステップ
+
+MCPクライアントの実装により、次のことが可能になります:
+
+1. **webhookリスナーの実装** - Hubイベントを受信するFastAPIエンドポイントを作成
+2. **すべての統合** - webhook、クライアント、サーバーを完全なシステムに接続
+3. **テストインターフェースの追加** - 開発・監視用のGradioインターフェースを作成
+4. **デプロイとテスト** - 本番環境で完全なシステムを検証
+
+次のセクションでは、MCPパワードタグ付けエージェントをトリガーするwebhookリスナーを実装します。
+
+
+
+`huggingface_hub`のAgentクラスは、MCPツール統合と言語モデル推論の両方を提供し、プルリクエストエージェントのようなインテリジェントな自動化ワークフローの構築に最適です。
+
+
\ No newline at end of file
diff --git a/units/ja/unit3_1/quiz1.mdx b/units/ja/unit3_1/quiz1.mdx
new file mode 100644
index 0000000..0d686ff
--- /dev/null
+++ b/units/ja/unit3_1/quiz1.mdx
@@ -0,0 +1,149 @@
+# クイズ1:MCPサーバー実装
+
+プルリクエストエージェントのMCPサーバーの概念と実装について知識をテストしてください。
+
+### Q1: プルリクエストエージェントのアーキテクチャにおけるMCPサーバーの主な役割は何ですか?
+
+
+
+### Q2: FastMCP実装では、なぜすべてのMCPツール関数がPythonオブジェクトではなく文字列を返す必要があるのですか?
+
+
+
+### Q3: `add_new_tag`ツールを実装する際、プルリクエストを作成する前にタグが既に存在するかを確認する目的は何ですか?
+
+
+
+### Q4: MCPサーバー実装において、モデルリポジトリに既存のREADME.mdファイルがない場合、何が起こりますか?
+
+
+
+### Q5: `hf_api.create_commit()`関数呼び出しで`create_pr=True`を使用することの意義は何ですか?
+
+
+
+### Q6: MCPサーバー実装では、コード全体で絵文字を使った広範囲なログ記録を使用するのはなぜですか?
+
+
+
+このクイズの完了おめでとうございます🥳!要素を復習する必要がある場合は、時間をかけて章を再訪し、知識を強化してください。
\ No newline at end of file
diff --git a/units/ja/unit3_1/quiz2.mdx b/units/ja/unit3_1/quiz2.mdx
new file mode 100644
index 0000000..abb02cc
--- /dev/null
+++ b/units/ja/unit3_1/quiz2.mdx
@@ -0,0 +1,173 @@
+# クイズ2:プルリクエストエージェント統合
+
+MCPクライアント統合とwebhook処理を含む、完全なプルリクエストエージェントシステムの知識をテストしてください。
+
+### Q1: プルリクエストエージェントアーキテクチャにおけるwebhookリスナーの主な目的は何ですか?
+
+
+
+### Q2: エージェントベースのMCPクライアント実装において、クライアントはMCPサーバーにどのように接続しますか?
+
+
+
+### Q3: webhookハンドラーがリクエストを同期的に処理する代わりに、FastAPIの`background_tasks.add_task()`を使用する理由は何ですか?
+
+
+
+### Q4: webhookハンドラーで`X-Webhook-Secret`ヘッダーを検証する目的は何ですか?
+
+
+
+### Q5: エージェント実装において、`await agent_instance.load_tools()`が呼び出されたときに何が起こりますか?
+
+
+
+### Q6: 自然言語命令を処理する際に、エージェントはどのようにMCPツールを知的に使用しますか?
+
+
+
+### Q7: webhookイベントがタグ処理をトリガーするかどうかを決定するフィルタリングロジックは何ですか?
+
+
+
+このクイズを完了おめでとうございます!要素を復習する必要がある場合は、時間をかけてチャプターを見直して知識を強化してください。
\ No newline at end of file
diff --git a/units/ja/unit3_1/setting-up-the-project.mdx b/units/ja/unit3_1/setting-up-the-project.mdx
new file mode 100644
index 0000000..77059c0
--- /dev/null
+++ b/units/ja/unit3_1/setting-up-the-project.mdx
@@ -0,0 +1,133 @@
+# プロジェクトのセットアップ
+
+このセクションでは、プルリクエストエージェントの開発環境をセットアップします。
+
+
+
+依存関係管理には`uv`を使用したモダンなPythonツールを使用し、必要な設定ファイルを作成します。`uv`に馴染みがない場合は、[こちら](https://docs.astral.sh/uv/)で詳しく学ぶことができます。
+
+
+
+
+## プロジェクト構造
+
+プロジェクトディレクトリを作成し、ファイル構造を理解することから始めましょう:
+
+```bash
+git clone https://huggingface.co/spaces/mcp-course/tag-this-repo
+```
+
+最終的なプロジェクト構造は以下のようになります:
+
+```
+hf-pr-agent/
+├── mcp_server.py # タグ付けツール付きのコアMCPサーバー
+├── app.py # FastAPI Webhookリスナーとエージェント
+├── requirements.txt # Python依存関係
+├── pyproject.toml # プロジェクト設定ファイル
+├── env.example # 環境変数テンプレート
+├── cleanup.py # 開発ユーティリティ
+```
+
+## 依存関係と設定ファイル
+
+プロジェクトの依存関係と設定について説明します。
+
+### 1. Pythonプロジェクト設定ファイル
+
+`uv`を使用して`pyproject.toml`ファイルを作成し、プロジェクトを定義します:
+
+
+
+`uv`がインストールされていない場合は、[こちら](https://docs.astral.sh/uv/getting-started/installation/)の手順に従ってください。
+
+
+
+```toml
+[project]
+name = "mcp-course-unit3-example"
+version = "0.1.0"
+description = "FastAPI and Gradio app for Hugging Face Hub discussion webhooks"
+readme = "README.md"
+requires-python = ">=3.11"
+dependencies = [
+ "fastapi>=0.104.0",
+ "uvicorn[standard]>=0.24.0",
+ "gradio>=4.0.0",
+ "huggingface-hub[mcp]>=0.32.0",
+ "pydantic>=2.0.0",
+ "python-multipart>=0.0.6",
+ "requests>=2.31.0",
+ "python-dotenv>=1.0.0",
+ "fastmcp>=2.0.0",
+]
+
+[build-system]
+requires = ["hatchling"]
+build-backend = "hatchling.build"
+
+[tool.hatch.build.targets.wheel]
+packages = ["src"]
+```
+
+さまざまなデプロイメントプラットフォームとの互換性のため、同じ内容が`requirements.txt`にも記載されています。
+
+仮想環境を作成するには、以下を実行します:
+
+```bash
+uv venv
+source .venv/bin/activate # WindowsではC.venv/Scripts/activate
+```
+
+依存関係をインストールするには、以下を実行します:
+
+```bash
+uv sync
+```
+
+### 2. 環境設定
+
+必要な環境変数を文書化するために`env.example`を作成します:
+
+```bash
+# Hugging Face APIトークン(必須)
+# 取得先:https://huggingface.co/settings/tokens
+HF_TOKEN=hf_your_token_here
+
+# Webhookシークレット(本番環境では必須)
+# 強力でランダムな文字列を使用
+WEBHOOK_SECRET=your-webhook-secret-here
+
+# エージェント用モデル(オプション)
+HF_MODEL=owner/model
+
+# MCPエージェント用プロバイダー(オプション)
+HF_PROVIDER=huggingface
+```
+
+Hugging Face APIトークンを[こちら](https://huggingface.co/settings/tokens)から取得する必要があります。
+
+また、Webhookシークレットを生成する必要があります。以下のコマンドを実行してください:
+
+```bash
+python -c "import secrets; print(secrets.token_hex(32))"
+```
+
+その後、`env.example`ファイルを基に、Webhookシークレットを`.env`ファイルに追加する必要があります。
+
+## 次のステップ
+
+プロジェクト構造と環境のセットアップが完了したので、以下の準備が整いました:
+
+1. **MCPサーバーの作成** - コアタグ付け機能の実装
+2. **Webhookリスナーの構築** - 受信ディスカッションイベントの処理
+3. **エージェントの統合** - MCPツールとWebhook処理の接続
+4. **テストとデプロイ** - 機能の検証とSpacesへのデプロイ
+
+次のセクションでは、すべてのHugging Face Hub対話を処理するMCPサーバーの作成について詳しく説明します。
+
+
+
+`.env`ファイルを安全に保管し、バージョン管理にコミットしないでください。`.env`ファイルは、秘密情報の偶発的な漏洩を防ぐため、`.gitignore`ファイルに追加する必要があります。
+
+
\ No newline at end of file
diff --git a/units/ja/unit3_1/webhook-listener.mdx b/units/ja/unit3_1/webhook-listener.mdx
new file mode 100644
index 0000000..bdd19e4
--- /dev/null
+++ b/units/ja/unit3_1/webhook-listener.mdx
@@ -0,0 +1,518 @@
+# Webhookリスナー
+
+webhookリスナーは、プルリクエストエージェントのエントリーポイントです。Hugging Face Hubでディスカッションが作成または更新されたときにリアルタイムイベントを受信し、MCPを活用したタグ付けワークフローをトリガーします。このセクションでは、FastAPIを使用してwebhookハンドラーを実装します。
+
+## Webhook統合の理解
+
+[Hugging Face Webhooks Guide](https://raw.githubusercontent.com/huggingface/hub-docs/refs/heads/main/docs/hub/webhooks-guide-discussion-bot.md)に従って、webhookリスナーは受信リクエストを検証し、ディスカッションイベントをリアルタイムで処理します。
+
+
+
+### Webhookイベントフロー
+
+信頼性の高いリスナーを構築するためには、webhookフローを理解することが重要です:
+
+1. **ユーザーアクション**: 誰かがモデルリポジトリのディスカッションでコメントを作成
+2. **Hubイベント**: Hugging Faceがwebhookイベントを生成
+3. **Webhook配信**: HubがPOST requestを私たちのエンドポイントに送信
+4. **認証**: webhookシークレットを検証
+5. **処理**: コメント内容からタグを抽出
+6. **アクション**: MCPツールを使用して新しいタグのプルリクエストを作成
+
+
+
+Webhookはプッシュ通知です - Hugging Face Hubは変更をポーリングするのではなく、アクティブにイベントをアプリケーションに送信します。これにより、ディスカッションやコメントに対するリアルタイムの応答が可能になります。
+
+
+
+## FastAPI Webhookアプリケーション
+
+基盤から始めて完全な処理ロジックまで構築しながら、webhookリスナーをステップバイステップで作成しましょう。
+
+### 1. アプリケーションセットアップ
+
+まず、必要なすべてのインポートと設定を含む基本のFastAPIアプリケーションをセットアップしましょう:
+
+```python
+import os
+import json
+from datetime import datetime
+from typing import List, Dict, Any, Optional
+
+from fastapi import FastAPI, Request, BackgroundTasks
+from fastapi.middleware.cors import CORSMiddleware
+from pydantic import BaseModel
+```
+
+これらのインポートは、堅牢なwebhookハンドラーを構築するために必要なすべてを提供します。`FastAPI`はWebフレームワークを提供し、`BackgroundTasks`は非同期処理を可能にし、typingインポートはデータ検証を支援します。
+
+次に、アプリケーションを設定しましょう:
+
+```python
+# Configuration
+WEBHOOK_SECRET = os.getenv("WEBHOOK_SECRET")
+HF_TOKEN = os.getenv("HF_TOKEN")
+
+# Simple storage for processed operations
+tag_operations_store: List[Dict[str, Any]] = []
+
+app = FastAPI(title="HF Tagging Bot")
+app.add_middleware(CORSMiddleware, allow_origins=["*"])
+```
+
+この設定では以下をセットアップします:
+- **Webhookシークレット**: 受信webhookの検証用
+- **HFトークン**: Hub APIでの認証用
+- **オペレーションストア**: 処理されたオペレーションを監視するためのインメモリストレージ
+- **CORSミドルウェア**: Webインターフェース用のクロスオリジンリクエストを許可
+
+
+`tag_operations_store`リストは最近のwebhook処理オペレーションを追跡します。これはデバッグと監視に役立ちますが、本番環境ではデータベースを使用するか、このリストのサイズを制限することを検討してください。
+
+
+### 2. Webhookデータモデル
+
+[Hugging Face webhook documentation](https://raw.githubusercontent.com/huggingface/hub-docs/refs/heads/main/docs/hub/webhooks-guide-discussion-bot.md)に基づいて、webhookデータ構造を理解する必要があります:
+
+```python
+class WebhookEvent(BaseModel):
+ event: Dict[str, str] # Contains action and scope information
+ comment: Dict[str, Any] # Comment content and metadata
+ discussion: Dict[str, Any] # Discussion information
+ repo: Dict[str, str] # Repository details
+```
+
+このPydanticモデルは、webhook構造の理解を助けます。
+
+私たちが関心を持つ主要なフィールドは:
+- `event.action`: 新しいコメントの場合は通常"create"
+- `event.scope`: コメントイベントの場合は通常"discussion.comment"
+- `comment.content`: 実際のコメントテキスト
+- `repo.name`: コメントが作成されたリポジトリ
+
+### 3. コアWebhookハンドラー
+
+次に、メインのwebhookハンドラーです - ここが重要な部分です。理解しやすい部分に分けて見てみましょう:
+
+```python
+@app.post("/webhook")
+async def webhook_handler(request: Request, background_tasks: BackgroundTasks):
+ """
+ Handle incoming webhooks from Hugging Face Hub
+ Following the pattern from: https://raw.githubusercontent.com/huggingface/hub-docs/refs/heads/main/docs/hub/webhooks-guide-discussion-bot.md
+ """
+ print("🔔 Webhook received!")
+
+ # Step 1: Validate webhook secret (security)
+ webhook_secret = request.headers.get("X-Webhook-Secret")
+ if webhook_secret != WEBHOOK_SECRET:
+ print("❌ Invalid webhook secret")
+ return {"error": "incorrect secret"}, 400
+```
+
+最初のステップはセキュリティ検証です。webhookが正当なものであることを確認するために、`X-Webhook-Secret`ヘッダーを設定されたシークレットと照合します。
+
+
+
+常にwebhookシークレットを検証してください!この確認なしでは、誰でも偽のwebhookリクエストをアプリケーションに送信できてしまいます。シークレットはHugging Faceとアプリケーション間の共有パスワードとして機能します。
+
+
+
+次に、webhookデータの解析と検証を行いましょう:
+
+```python
+ # Step 2: Parse webhook data
+ try:
+ webhook_data = await request.json()
+ print(f"📥 Webhook data: {json.dumps(webhook_data, indent=2)}")
+ except Exception as e:
+ print(f"❌ Error parsing webhook data: {str(e)}")
+ return {"error": "invalid JSON"}, 400
+
+ # Step 3: Validate event structure
+ event = webhook_data.get("event", {})
+ if not event:
+ print("❌ No event data in webhook")
+ return {"error": "missing event data"}, 400
+```
+
+この解析ステップは、潜在的なJSONエラーを適切に処理し、期待されるイベント構造があることを検証します。
+
+次に、イベントフィルタリングロジックです:
+
+```python
+ # Step 4: Check if this is a discussion comment creation
+ # Following the webhook guide pattern:
+ if (
+ event.get("action") == "create" and
+ event.get("scope") == "discussion.comment"
+ ):
+ print("✅ Valid discussion comment creation event")
+
+ # Process in background to return quickly to Hub
+ background_tasks.add_task(process_webhook_comment, webhook_data)
+
+ return {
+ "status": "accepted",
+ "message": "Comment processing started",
+ "timestamp": datetime.now().isoformat()
+ }
+ else:
+ print(f"ℹ️ Ignoring event: action={event.get('action')}, scope={event.get('scope')}")
+ return {
+ "status": "ignored",
+ "reason": "Not a discussion comment creation"
+ }
+```
+
+このフィルタリングにより、私たちが関心を持つイベント(新しいディスカッションコメント)のみを処理することが保証されます。リポジトリ作成、モデルアップロードなどの他のイベントは無視します。
+
+FastAPIの`background_tasks.add_task()`を使用してwebhookを非同期で処理します。これにより、実際のタグ処理はバックグラウンドで実行されながら、迅速にレスポンス(数秒以内)を返すことができます。
+
+
+
+Webhookエンドポイントは10秒以内に応答する必要があります。そうでなければ、送信プラットフォームは失敗とみなす可能性があります。バックグラウンドタスクを使用することで、複雑な処理を非同期で実行しながら高速な応答を保証します。
+
+
+
+### 4. コメント処理ロジック
+
+次に、実際のタグ抽出とMCPツール使用を行うコアコメント処理機能を実装しましょう:
+
+```python
+async def process_webhook_comment(webhook_data: Dict[str, Any]):
+ """
+ Process webhook comment to detect and add tags
+ Integrates with our MCP client for Hub interactions
+ """
+ print("🏷️ Starting process_webhook_comment...")
+
+ try:
+ # Extract comment and repository information
+ comment_content = webhook_data["comment"]["content"]
+ discussion_title = webhook_data["discussion"]["title"]
+ repo_name = webhook_data["repo"]["name"]
+ discussion_num = webhook_data["discussion"]["num"]
+ comment_author = webhook_data["comment"]["author"].get("id", "unknown")
+
+ print(f"📝 Comment from {comment_author}: {comment_content}")
+ print(f"📰 Discussion: {discussion_title}")
+ print(f"📦 Repository: {repo_name}")
+```
+
+この初期セクションは、webhookデータから関連するすべての情報を抽出します。タグがどちらの場所でも言及される可能性があるため、コメント内容とディスカッションタイトルの両方を取得します。
+
+次に、タグを抽出して処理します:
+
+```python
+ # Extract potential tags from comment and title
+ comment_tags = extract_tags_from_text(comment_content)
+ title_tags = extract_tags_from_text(discussion_title)
+ all_tags = list(set(comment_tags + title_tags))
+
+ print(f"🔍 Found tags: {all_tags}")
+
+ # Store operation for monitoring
+ operation = {
+ "timestamp": datetime.now().isoformat(),
+ "repo_name": repo_name,
+ "discussion_num": discussion_num,
+ "comment_author": comment_author,
+ "extracted_tags": all_tags,
+ "comment_preview": comment_content[:100] + "..." if len(comment_content) > 100 else comment_content,
+ "status": "processing"
+ }
+ tag_operations_store.append(operation)
+```
+
+両方のソースからタグを組み合わせ、監視用のオペレーションレコードを作成します。このレコードは、各webhook処理オペレーションの進行状況を追跡します。
+
+
+
+オペレーションレコードの保存は、デバッグと監視にとって重要です。何かが間違ったときに、最近のオペレーションを見て何が起こったか、なぜ起こったかを理解できます。
+
+
+
+次に、MCPエージェント統合です:
+
+```python
+ if not all_tags:
+ operation["status"] = "no_tags"
+ operation["message"] = "No recognizable tags found"
+ print("❌ No tags found to process")
+ return
+
+ # Get MCP agent for tag processing
+ agent = await get_agent()
+ if not agent:
+ operation["status"] = "error"
+ operation["message"] = "Agent not configured (missing HF_TOKEN)"
+ print("❌ No agent available")
+ return
+
+ # Process each extracted tag
+ operation["results"] = []
+ for tag in all_tags:
+ try:
+ print(f"🤖 Processing tag '{tag}' for repo '{repo_name}'")
+
+ # Create prompt for agent to handle tag processing
+ prompt = f"""
+ Analyze the repository '{repo_name}' and determine if the tag '{tag}' should be added.
+
+ First, check the current tags using get_current_tags.
+ If '{tag}' is not already present and it's a valid tag, add it using add_new_tag.
+
+ Repository: {repo_name}
+ Tag to process: {tag}
+
+ Provide a clear summary of what was done.
+ """
+
+ response = await agent.run(prompt)
+ print(f"🤖 Agent response for '{tag}': {response}")
+
+ # Parse response and store result
+ tag_result = {
+ "tag": tag,
+ "response": response,
+ "timestamp": datetime.now().isoformat()
+ }
+ operation["results"].append(tag_result)
+
+ except Exception as e:
+ error_msg = f"❌ Error processing tag '{tag}': {str(e)}"
+ print(error_msg)
+ operation["results"].append({
+ "tag": tag,
+ "error": str(e),
+ "timestamp": datetime.now().isoformat()
+ })
+
+ operation["status"] = "completed"
+ print(f"✅ Completed processing {len(all_tags)} tags")
+```
+
+このセクションは、コアビジネスロジックを処理します:
+1. **検証**: 処理すべきタグと利用可能なエージェントがあることを確認
+2. **処理**: 各タグに対して、エージェント用の自然言語プロンプトを作成
+3. **記録**: 監視とデバッグのためにすべての結果を保存
+4. **エラーハンドリング**: 個々のタグのエラーを適切に処理
+
+エージェントプロンプトは、AIが取るべき正確なステップを指示するように慎重に作成されています:まず現在のタグを確認し、適切な場合は新しいタグを追加します。
+
+### 5. ヘルスと監視エンドポイント
+
+webhookハンドラー以外に、監視とデバッグのためのエンドポイントが必要です。これらの重要なエンドポイントを追加しましょう:
+
+```python
+@app.get("/")
+async def root():
+ """Root endpoint with basic information"""
+ return {
+ "name": "HF Tagging Bot",
+ "status": "running",
+ "description": "Webhook listener for automatic model tagging",
+ "endpoints": {
+ "webhook": "/webhook",
+ "health": "/health",
+ "operations": "/operations"
+ }
+ }
+```
+
+ルートエンドポイントは、サービスとその利用可能なエンドポイントに関する基本情報を提供します。
+
+```python
+@app.get("/health")
+async def health_check():
+ """Health check endpoint for monitoring"""
+ agent = await get_agent()
+
+ return {
+ "status": "healthy",
+ "timestamp": datetime.now().isoformat(),
+ "components": {
+ "webhook_secret": "configured" if WEBHOOK_SECRET else "missing",
+ "hf_token": "configured" if HF_TOKEN else "missing",
+ "mcp_agent": "ready" if agent else "not_ready"
+ }
+ }
+```
+
+ヘルスチェックエンドポイントは、すべてのコンポーネントが適切に設定されていることを検証します。これは本番監視に不可欠です。
+
+```python
+@app.get("/operations")
+async def get_operations():
+ """Get recent tag operations for monitoring"""
+ # Return last 50 operations
+ recent_ops = tag_operations_store[-50:] if tag_operations_store else []
+ return {
+ "total_operations": len(tag_operations_store),
+ "recent_operations": recent_ops
+ }
+```
+
+オペレーションエンドポイントでは、最近のwebhook処理アクティビティを確認できます。これはデバッグと監視にとって非常に有用です。
+
+
+
+ヘルスと監視エンドポイントは、本番デプロイメントにとって重要です。ログを掘り下げることなく、設定の問題を迅速に特定し、アプリケーションのアクティビティを監視するのに役立ちます。
+
+
+
+## Hugging Face HubでのWebhook設定
+
+webhookリスナーの準備ができたので、Hugging Face Hubで設定しましょう。ここで、アプリケーションを実際のリポジトリイベントに接続します。
+
+### 1. 設定でWebhookを作成
+
+[webhook setup guide](https://huggingface.co/docs/hub/webhooks-guide-discussion-bot)に従って:
+
+
+
+[Hugging Face Settings](https://huggingface.co/settings/webhooks)に移動して設定します:
+
+1. **対象リポジトリ**: 監視するリポジトリを指定
+2. **Webhook URL**: デプロイされたアプリケーションエンドポイント(例:`https://your-space.hf.space/webhook`)
+3. **シークレット**: `WEBHOOK_SECRET`環境変数と同じシークレットを使用
+4. **イベント**: "Community (PR & discussions)"イベントを購読
+
+
+
+多くのリポジトリにwebhookを設定する前に、1つまたは2つのテストリポジトリから始めてください。これにより、スケールアップする前にアプリケーションが正しく動作することを検証できます。
+
+
+
+### 2. Space URL設定
+
+Hugging Face Spacesデプロイメントでは、直接URLを取得する必要があります:
+
+
+
+プロセスは以下の通りです:
+1. Space設定で"Embed this Space"をクリック
+2. "Direct URL"をコピー
+3. `/webhook`を追加してwebhookエンドポイントを作成
+4. このURLでwebhook設定を更新
+
+例えば、Space URLが`https://username-space-name.hf.space`の場合、webhookエンドポイントは`https://username-space-name.hf.space/webhook`になります。
+
+
+
+## Webhookリスナーのテスト
+
+本番環境にデプロイする前にテストが重要です。さまざまなテストアプローチを見てみましょう:
+
+### 1. ローカルテスト
+
+簡単なスクリプトを使用してwebhookハンドラーをローカルでテストできます:
+
+```python
+# test_webhook_local.py
+import requests
+import json
+
+# Test data matching webhook format
+test_webhook_data = {
+ "event": {
+ "action": "create",
+ "scope": "discussion.comment"
+ },
+ "comment": {
+ "content": "This model needs tags: pytorch, transformers",
+ "author": {"id": "test-user"}
+ },
+ "discussion": {
+ "title": "Missing tags",
+ "num": 1
+ },
+ "repo": {
+ "name": "test-user/test-model"
+ }
+}
+
+# Send test webhook
+response = requests.post(
+ "http://localhost:8000/webhook",
+ json=test_webhook_data,
+ headers={"X-Webhook-Secret": "your-test-secret"}
+)
+
+print(f"Status: {response.status_code}")
+print(f"Response: {response.json()}")
+```
+
+このスクリプトは実際のwebhookリクエストをシミュレートし、実際のイベントを待つことなくハンドラーをテストできます。
+
+### 2. 開発用シミュレーションエンドポイント
+
+より簡単なテストのために、FastAPIアプリケーションにシミュレーションエンドポイントを追加することもできます:
+
+```python
+@app.post("/simulate_webhook")
+async def simulate_webhook(
+ repo_name: str,
+ discussion_title: str,
+ comment_content: str
+) -> str:
+ """Simulate webhook for testing purposes"""
+
+ # Create mock webhook data
+ mock_webhook_data = {
+ "event": {
+ "action": "create",
+ "scope": "discussion.comment"
+ },
+ "comment": {
+ "content": comment_content,
+ "author": {"id": "test-user"}
+ },
+ "discussion": {
+ "title": discussion_title,
+ "num": 999
+ },
+ "repo": {
+ "name": repo_name
+ }
+ }
+
+ # Process the simulated webhook
+ await process_webhook_comment(mock_webhook_data)
+
+ return f"Simulated webhook processed for {repo_name}"
+```
+
+このエンドポイントにより、アプリケーションのインターフェースを通じてさまざまなシナリオを簡単にテストできます。
+
+
+シミュレーションエンドポイントは開発中に非常に有用です。実際のリポジトリディスカッションを作成することなく、さまざまなタグの組み合わせやエッジケースをテストできます。
+
+
+## 期待されるWebhook結果
+
+すべてが正しく動作している場合、ディスカッションボットの例のような結果が表示されるはずです:
+
+
+
+
+
+このスクリーンショットは、ボットがディスカッションコメントに応答してプルリクエストを作成する成功したwebhook処理を示しています。
+
+## 次のステップ
+
+webhookリスナーが実装されたことで、以下が得られました:
+
+1. **セキュアなwebhook検証** - Hugging Faceのベストプラクティスに従った
+2. **リアルタイムイベント処理** - バックグラウンドタスクハンドリング付き
+3. **MCP統合** - インテリジェントなタグ管理のため
+4. **監視とデバッグ** 機能
+
+次のセクションでは、webhookからPR作成までの完全なワークフローを実証する、完全なプルリクエストエージェントにすべてを統合します。
+
+
+
+タイムアウトを避けるため、常にwebhookレスポンスを迅速に(10秒以内に)返してください。MCPツール実行やプルリクエスト作成などの長い処理オペレーションには、バックグラウンドタスクを使用してください。
+
+
\ No newline at end of file