diff --git a/.github/ISSUE_TEMPLATE/config.yml b/.github/ISSUE_TEMPLATE/config.yml
index 1708201c..ba9aef5b 100644
--- a/.github/ISSUE_TEMPLATE/config.yml
+++ b/.github/ISSUE_TEMPLATE/config.yml
@@ -24,4 +24,4 @@ contact_links:
url: https://g.co/vulnz
about: >
To report a security issue, please use https://g.co/vulnz. The Google Security Team will
- respond within 5 working days of your report on https://g.co/vulnz.
\ No newline at end of file
+ respond within 5 working days of your report on https://g.co/vulnz.
diff --git a/.github/workflows/ci.yaml b/.github/workflows/ci.yaml
index fc8a2a87..e4291408 100644
--- a/.github/workflows/ci.yaml
+++ b/.github/workflows/ci.yaml
@@ -42,6 +42,40 @@ jobs:
python -m pip install --upgrade pip
pip install -e ".[dev,test]"
- - name: Run tox (lint + tests)
+ - name: Run unit tests and linting
run: |
- tox
\ No newline at end of file
+ PY_VERSION=$(echo "${{ matrix.python-version }}" | tr -d '.')
+ tox -e py${PY_VERSION},format,lint-src,lint-tests
+
+ live-api-tests:
+ needs: test
+ runs-on: ubuntu-latest
+ if: |
+ github.event_name == 'push' ||
+ (github.event_name == 'pull_request' &&
+ github.event.pull_request.head.repo.full_name == github.repository)
+
+ steps:
+ - uses: actions/checkout@v4
+
+ - name: Set up Python 3.11
+ uses: actions/setup-python@v4
+ with:
+ python-version: "3.11"
+
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ pip install -e ".[dev,test]"
+
+ - name: Run live API tests
+ env:
+ GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
+ LANGEXTRACT_API_KEY: ${{ secrets.GEMINI_API_KEY }} # For backward compatibility
+ OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
+ run: |
+ if [[ -z "$GEMINI_API_KEY" && -z "$OPENAI_API_KEY" ]]; then
+ echo "::notice::Live API tests skipped - no provider secrets configured"
+ exit 0
+ fi
+ tox -e live-api
diff --git a/.github/workflows/publish.yml b/.github/workflows/publish.yml
new file mode 100644
index 00000000..cb3ff700
--- /dev/null
+++ b/.github/workflows/publish.yml
@@ -0,0 +1,55 @@
+# Copyright 2025 Google LLC.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+name: Publish to PyPI
+
+on:
+ release:
+ types: [published]
+
+permissions:
+ contents: read
+ id-token: write
+
+jobs:
+ pypi-publish:
+ name: Publish to PyPI
+ runs-on: ubuntu-latest
+ environment: pypi
+ permissions:
+ id-token: write
+ steps:
+ - uses: actions/checkout@v4
+
+ - name: Set up Python
+ uses: actions/setup-python@v5
+ with:
+ python-version: '3.11'
+
+ - name: Install build dependencies
+ run: |
+ python -m pip install --upgrade pip
+ pip install build
+
+ - name: Build package
+ run: python -m build
+
+ - name: Verify build artifacts
+ run: |
+ ls -la dist/
+ pip install twine
+ twine check dist/*
+
+ - name: Publish to PyPI
+ uses: pypa/gh-action-pypi-publish@release/v1
diff --git a/.github/workflows/validate_pr_template.yaml b/.github/workflows/validate_pr_template.yaml
new file mode 100644
index 00000000..46c4963e
--- /dev/null
+++ b/.github/workflows/validate_pr_template.yaml
@@ -0,0 +1,41 @@
+name: Validate PR template
+
+on:
+ pull_request:
+ types: [opened, edited, synchronize, reopened]
+
+permissions:
+ contents: read
+
+jobs:
+ check:
+ if: github.event.pull_request.draft == false # drafts can save early
+ runs-on: ubuntu-latest
+
+ steps:
+ - name: Fail if template untouched
+ env:
+ PR_BODY: ${{ github.event.pull_request.body }}
+ run: |
+ printf '%s\n' "$PR_BODY" | tr -d '\r' > body.txt
+
+ # Required sections from the template
+ required=( "# Description" "Fixes #" "# How Has This Been Tested?" "# Checklist" )
+ err=0
+
+ # Check for required sections
+ for h in "${required[@]}"; do
+ grep -Fq "$h" body.txt || { echo "::error::$h missing"; err=1; }
+ done
+
+ # Check for placeholder text that should be replaced
+ grep -Eiq 'Replace this with|Choose one:' body.txt && {
+ echo "::error::Template placeholders still present"; err=1;
+ }
+
+ # Also check for the unmodified issue number placeholder
+ grep -Fq 'Fixes #[issue number]' body.txt && {
+ echo "::error::Issue number placeholder not updated"; err=1;
+ }
+
+ exit $err
diff --git a/.gitignore b/.gitignore
index 458f449d..fc93e588 100644
--- a/.gitignore
+++ b/.gitignore
@@ -51,4 +51,4 @@ docs/_build/
*.swp
# OS-specific
-.DS_Store
\ No newline at end of file
+.DS_Store
diff --git a/.hgignore b/.hgignore
index 4ef06c6c..3fb66f47 100644
--- a/.hgignore
+++ b/.hgignore
@@ -12,4 +12,4 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-gdm/codeai/codemind/cli/GEMINI.md
\ No newline at end of file
+gdm/codeai/codemind/cli/GEMINI.md
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
new file mode 100644
index 00000000..84410316
--- /dev/null
+++ b/.pre-commit-config.yaml
@@ -0,0 +1,46 @@
+# Copyright 2025 Google LLC.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Pre-commit hooks for LangExtract
+# Install with: pre-commit install
+# Run manually: pre-commit run --all-files
+
+repos:
+ - repo: https://github.com/PyCQA/isort
+ rev: 5.13.2
+ hooks:
+ - id: isort
+ name: isort (import sorting)
+ # Configuration is in pyproject.toml
+
+ - repo: https://github.com/google/pyink
+ rev: 24.3.0
+ hooks:
+ - id: pyink
+ name: pyink (Google's Black fork)
+ args: ["--config", "pyproject.toml"]
+
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.5.0
+ hooks:
+ - id: end-of-file-fixer
+ exclude: \.gif$|\.svg$
+ - id: trailing-whitespace
+ - id: check-yaml
+ - id: check-added-large-files
+ args: ['--maxkb=1000']
+ - id: check-merge-conflict
+ - id: check-case-conflict
+ - id: mixed-line-ending
+ args: ['--fix=lf']
diff --git a/.pylintrc b/.pylintrc
index 5709bc73..2e09c87f 100644
--- a/.pylintrc
+++ b/.pylintrc
@@ -14,10 +14,418 @@
[MASTER]
+# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
+# number of processors available to use.
+jobs=0
+
+# When enabled, pylint would attempt to guess common misconfiguration and emit
+# user-friendly hints instead of false-positive error messages.
+suggestion-mode=yes
+
+# Pickle collected data for later comparisons.
+persistent=yes
+
+# List of plugins (as comma separated values of python modules names) to load,
+# usually to register additional checkers.
+# Note: These plugins require Pylint >= 3.0
+load-plugins=
+ pylint.extensions.docparams,
+ pylint.extensions.typing
+
+# Allow loading of arbitrary C extensions. Extensions are imported into the
+# active Python interpreter and may run arbitrary code.
+unsafe-load-any-extension=no
+
+
[MESSAGES CONTROL]
-disable=all
-enable=F
+
+# Enable the message, report, category or checker with the given id(s). You can
+# either give multiple identifier separated by comma (,) or put this option
+# multiple time.
+enable=
+ useless-suppression
+
+# Disable the message, report, category or checker with the given id(s). You
+# can either give multiple identifier separated by comma (,) or put this option
+# multiple time (only on the command line, not in the configuration file where
+# it should appear only once).
+disable=
+ abstract-method, # Protocol/ABC classes often have abstract methods
+ too-few-public-methods, # Valid for data classes with minimal interface
+ fixme, # TODO/FIXME comments are useful for tracking work
+ # --- Code style and formatting ---
+ line-too-long, # Handled by pyink formatter
+ bad-indentation, # Pyink uses 2-space indentation
+ # --- Design complexity ---
+ too-many-positional-arguments,
+ too-many-locals,
+ too-many-arguments,
+ too-many-branches,
+ too-many-statements,
+ too-many-nested-blocks,
+ # --- Style preferences ---
+ no-else-return,
+ no-else-raise,
+ # --- Documentation ---
+ missing-function-docstring,
+ missing-class-docstring,
+ missing-raises-doc,
+ # --- Gradual improvements ---
+ deprecated-typing-alias, # For typing.Type etc.
+ unspecified-encoding,
+ unused-import
+
[REPORTS]
+
+# Set the output format. Available formats are text, parseable, colorized, msvs
+# (visual studio) and html.
output-format=text
-reports=no
\ No newline at end of file
+
+# Tells whether to display a full report or only the messages
+reports=no
+
+# Activate the evaluation score.
+score=no
+
+
+[REFACTORING]
+
+# Maximum number of nested blocks for function / method body
+max-nested-blocks=5
+
+# Complete name of functions that never returns. When checking for
+# inconsistent-return-statements if a never returning function is called then
+# it will be considered as an explicit return statement and no message will be
+# printed.
+never-returning-functions=sys.exit
+
+
+[BASIC]
+
+# Naming style matching correct argument names.
+argument-naming-style=snake_case
+
+# Naming style matching correct attribute names.
+attr-naming-style=snake_case
+
+# Bad variable names which should always be refused, separated by a comma.
+bad-names=foo,bar,baz,toto,tutu,tata
+
+# Naming style matching correct class attribute names.
+class-attribute-naming-style=any
+
+# Naming style matching correct class names.
+class-naming-style=PascalCase
+
+# Naming style matching correct constant names.
+const-naming-style=UPPER_CASE
+
+# Minimum line length for functions/classes that require docstrings, shorter
+# ones are exempt.
+docstring-min-length=-1
+
+# Naming style matching correct function names.
+function-naming-style=snake_case
+
+# Good variable names which should always be accepted, separated by a comma.
+good-names=i,j,k,ex,Run,_,id,ok
+
+# Good variable names regexes, separated by a comma. If names match any regex,
+# they will always be accepted
+good-names-rgxs=
+
+# Include a hint for the correct naming format with invalid-name.
+include-naming-hint=no
+
+# Naming style matching correct inline iteration names.
+inlinevar-naming-style=any
+
+# Naming style matching correct method names.
+method-naming-style=snake_case
+
+# Naming style matching correct module names.
+module-naming-style=snake_case
+
+# Colon-delimited sets of names that determine each other's naming style when
+# the name regexes allow several styles.
+name-group=
+
+# Regular expression which should only match function or class names that do
+# not require a docstring.
+no-docstring-rgx=^_
+
+# List of decorators that produce properties, such as abc.abstractproperty. Add
+# to this list to register other decorators that produce valid properties.
+# These decorators are taken in consideration only for invalid-name.
+property-classes=abc.abstractproperty
+
+# Naming style matching correct variable names.
+variable-naming-style=snake_case
+
+
+[FORMAT]
+
+# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
+expected-line-ending-format=LF
+
+# Regexp for a line that is allowed to be longer than the limit.
+ignore-long-lines=^\s*(# )??$
+
+# Number of spaces of indent required inside a hanging or continued line.
+indent-after-paren=2
+
+# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
+# tab).
+indent-string=" "
+
+# Maximum number of characters on a single line.
+max-line-length=80
+
+# Maximum number of lines in a module.
+max-module-lines=2000
+
+# Allow the body of a class to be on the same line as the declaration if body
+# contains single statement.
+single-line-class-stmt=no
+
+# Allow the body of an if to be on the same line as the test if there is no
+# else.
+single-line-if-stmt=no
+
+
+[LOGGING]
+
+# The type of string formatting that logging methods do. `old` means using %
+# formatting, `new` is for `{}` formatting.
+logging-format-style=old
+
+# Logging modules to check that the string format arguments are in logging
+# function parameter format.
+logging-modules=logging
+
+
+[MISCELLANEOUS]
+
+# List of note tags to take in consideration, separated by a comma.
+notes=FIXME,XXX,TODO
+
+
+[SIMILARITIES]
+
+# Ignore comments when computing similarities.
+ignore-comments=yes
+
+# Ignore docstrings when computing similarities.
+ignore-docstrings=yes
+
+# Ignore imports when computing similarities.
+ignore-imports=no
+
+# Minimum lines number of a similarity.
+min-similarity-lines=4
+
+
+[SPELLING]
+
+# Limits count of emitted suggestions for spelling mistakes.
+max-spelling-suggestions=4
+
+# Spelling dictionary name. Available dictionaries: none. To make it working
+# install python-enchant package..
+spelling-dict=
+
+# List of comma separated words that should not be checked.
+spelling-ignore-words=
+
+# A path to a file that contains private dictionary; one word per line.
+spelling-private-dict-file=
+
+# Tells whether to store unknown words to indicated private dictionary in
+# --spelling-private-dict-file option instead of raising a message.
+spelling-store-unknown-words=no
+
+
+[TYPECHECK]
+
+# List of decorators that produce context managers, such as
+# contextlib.contextmanager. Add to this list to register other decorators that
+# produce valid context managers.
+contextmanager-decorators=contextlib.contextmanager
+
+# List of members which are set dynamically and missed by pylint inference
+# system, and so shouldn't trigger E1101 when accessed. Python regular
+# expressions are accepted.
+generated-members=
+
+# Tells whether missing members accessed in mixin class should be ignored. A
+# mixin class is detected if its name ends with "mixin" (case insensitive).
+ignore-mixin-members=yes
+
+# Tells whether to warn about missing members when the owner of the attribute
+# is inferred to be None.
+ignore-none=yes
+
+# This flag controls whether pylint should warn about no-member and similar
+# checks whenever an opaque object is returned when inferring. The inference
+# can return multiple potential results while evaluating a Python object, but
+# some branches might not be evaluated, which results in partial inference. In
+# that case, it might be useful to still emit no-member and other checks for
+# the rest of the inferred objects.
+ignore-on-opaque-inference=yes
+
+# List of class names for which member attributes should not be checked (useful
+# for classes with dynamically set attributes). This supports the use of
+# qualified names.
+ignored-classes=optparse.Values,thread._local,_thread._local,dataclasses.InitVar,typing.Any
+
+# List of module names for which member attributes should not be checked
+# (useful for modules/projects where namespaces are manipulated during runtime
+# and thus existing member attributes cannot be deduced by static analysis. It
+# supports qualified module names, as well as Unix pattern matching.
+ignored-modules=dotenv,absl,more_itertools,pandas,requests,pydantic,yaml,IPython.display,
+ tqdm,numpy,google,langfun,typing_extensions
+
+# Show a hint with possible names when a member name was not found. The aspect
+# of finding the hint is based on edit distance.
+missing-member-hint=yes
+
+# The minimum edit distance a name should have in order to be considered a
+# similar match for a missing member name.
+missing-member-hint-distance=1
+
+# The total number of similar names that should be taken in consideration when
+# showing a hint for a missing member.
+missing-member-max-choices=1
+
+# List of decorators that change the signature of a decorated function.
+signature-mutators=
+
+
+[VARIABLES]
+
+# List of additional names supposed to be defined in builtins. Remember that
+# you should avoid defining new builtins when possible.
+additional-builtins=
+
+# Tells whether unused global variables should be treated as a violation.
+allow-global-unused-variables=yes
+
+# List of strings which can identify a callback function by name. A callback
+# name must start or end with one of those strings.
+callbacks=cb_,_cb
+
+# A regular expression matching the name of dummy variables (i.e. expected to
+# not be used).
+dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
+
+# Argument names that match this expression will be ignored. Default to name
+# with leading underscore.
+ignored-argument-names=_.*|^ignored_|^unused_
+
+# Tells whether we should check for unused import in __init__ files.
+init-import=no
+
+# List of qualified module names which can have objects that can redefine
+# builtins.
+redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
+
+
+[CLASSES]
+
+# List of method names used to declare (i.e. assign) instance attributes.
+defining-attr-methods=__init__,
+ __new__,
+ setUp,
+ __post_init__
+
+# List of member names, which should be excluded from the protected access
+# warning.
+exclude-protected=_asdict,
+ _fields,
+ _replace,
+ _source,
+ _make
+
+# List of valid names for the first argument in a class method.
+valid-classmethod-first-arg=cls
+
+# List of valid names for the first argument in a metaclass class method.
+valid-metaclass-classmethod-first-arg=cls
+
+
+[DESIGN]
+
+# Maximum number of arguments for function / method.
+max-args=7
+
+# Maximum number of attributes for a class (see R0902).
+max-attributes=10
+
+# Maximum number of boolean expressions in an if statement.
+max-bool-expr=5
+
+# Maximum number of branch for function / method body.
+max-branches=12
+
+# Maximum number of locals for function / method body.
+max-locals=15
+
+# Maximum number of parents for a class (see R0901).
+max-parents=7
+
+# Maximum number of public methods for a class (see R0904).
+max-public-methods=20
+
+# Maximum number of return / yield for function / method body.
+max-returns=6
+
+# Maximum number of statements in function / method body.
+max-statements=50
+
+# Minimum number of public methods for a class (see R0903).
+min-public-methods=0
+
+
+[IMPORTS]
+
+# Allow wildcard imports from modules that define __all__.
+allow-wildcard-with-all=yes
+
+# Analyse import fallback blocks. This can be used to support both Python 2 and
+# 3 compatible code, which means that the block might have code that exists
+# only in one or another interpreter, leading to false positives when analysed.
+analyse-fallback-blocks=no
+
+# Deprecated modules which should not be used, separated by a comma.
+deprecated-modules=optparse,tkinter.tix
+
+# Create a graph of external dependencies in the given file (report RP0402 must
+# not be disabled).
+ext-import-graph=
+
+# Create a graph of every (i.e. internal and external) dependencies in the
+# given file (report RP0402 must not be disabled).
+import-graph=
+
+# Create a graph of internal dependencies in the given file (report RP0402 must
+# not be disabled).
+int-import-graph=
+
+# Force import order to recognize a module as part of the standard
+# compatibility libraries.
+known-standard-library=
+
+# Force import order to recognize a module as part of a third party library.
+known-third-party=enchant,numpy,pandas,torch,langfun,pyglove
+
+# Couples of modules and preferred modules, separated by a comma.
+preferred-modules=
+
+
+[EXCEPTIONS]
+
+# Exceptions that will emit a warning when being caught. Defaults to
+# "BaseException, Exception".
+overgeneral-exceptions=BaseException,
+ Exception
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 724ff7f6..60f2eaae 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -23,13 +23,111 @@ sign a new one.
This project follows HAI-DEF's
[Community guidelines](https://developers.google.com/health-ai-developer-foundations/community-guidelines)
-## Contribution process
+## Reporting Issues
-### Code Reviews
+If you encounter a bug or have a feature request, please open an issue on GitHub.
+We have templates to help guide you:
+
+- **[Bug Report](.github/ISSUE_TEMPLATE/1-bug.md)**: For reporting bugs or unexpected behavior
+- **[Feature Request](.github/ISSUE_TEMPLATE/2-feature-request.md)**: For suggesting new features or improvements
+
+When creating an issue, GitHub will prompt you to choose the appropriate template.
+Please provide as much detail as possible to help us understand and address your concern.
+
+## Contribution Process
+
+### 1. Development Setup
+
+To get started, clone the repository and install the necessary dependencies for development and testing. Detailed instructions can be found in the [Installation from Source](https://github.com/google/langextract#from-source) section of the `README.md`.
+
+**Windows Users**: The formatting scripts use bash. Please use one of:
+- Git Bash (comes with Git for Windows)
+- WSL (Windows Subsystem for Linux)
+- PowerShell with bash-compatible commands
+
+### 2. Code Style and Formatting
+
+This project uses automated tools to maintain a consistent code style. Before submitting a pull request, please format your code:
+
+```bash
+# Run the auto-formatter
+./autoformat.sh
+```
+
+This script uses:
+- `isort` to organize imports with Google style (single-line imports)
+- `pyink` (Google's fork of Black) to format code according to Google's Python Style Guide
+
+You can also run the formatters manually:
+```bash
+isort langextract tests
+pyink langextract tests --config pyproject.toml
+```
+
+Note: The formatters target only `langextract` and `tests` directories by default to avoid
+formatting virtual environments or other non-source directories.
+
+### 3. Pre-commit Hooks (Recommended)
+
+For automatic formatting checks before each commit:
+
+```bash
+# Install pre-commit
+pip install pre-commit
+
+# Install the git hooks
+pre-commit install
+
+# Run manually on all files
+pre-commit run --all-files
+```
+
+### 4. Linting and Testing
+
+All contributions must pass linting checks and unit tests. Please run these locally before submitting your changes:
+
+```bash
+# Run linting with Pylint 3.x
+pylint --rcfile=.pylintrc langextract tests
+
+# Run tests
+pytest tests
+```
+
+**Note on Pylint Configuration**: We use a modern, minimal configuration that:
+- Only disables truly noisy checks (not entire categories)
+- Keeps critical error detection enabled
+- Uses plugins for enhanced docstring and type checking
+- Aligns with our pyink formatter (80-char lines, 2-space indents)
+
+For full testing across Python versions:
+```bash
+tox # runs pylint + pytest on Python 3.10 and 3.11
+```
+
+### 5. Submit Your Pull Request
All submissions, including submissions by project members, require review. We
use [GitHub pull requests](https://docs.github.com/articles/about-pull-requests)
for this purpose.
+When you create a pull request, GitHub will automatically populate it with our
+[pull request template](.github/PULL_REQUEST_TEMPLATE/pull_request_template.md).
+Please fill out all sections of the template to help reviewers understand your changes.
+
+#### Pull Request Guidelines
+
+- **Keep PRs focused and small**: Each PR should address a single, specific change. This makes review easier and faster.
+- **Reference related issues**: Use "Fixes #123" or "Addresses #123" in your PR description to link to relevant issues.
+- **Single-change commits**: A PR should typically comprise a single git commit. Squash multiple commits before submitting.
+- **Clear description**: Explain what your change does and why it's needed.
+- **Ensure all tests pass**: Check that both formatting and tests are green before requesting review.
+- **Respond to feedback promptly**: Address reviewer comments in a timely manner.
+
+If your change is large or complex, consider:
+- Opening an issue first to discuss the approach
+- Breaking it into multiple smaller PRs
+- Clearly explaining in the PR description why a larger change is necessary
+
For more details, read HAI-DEF's
[Contributing guidelines](https://developers.google.com/health-ai-developer-foundations/community-guidelines#contributing)
diff --git a/Dockerfile b/Dockerfile
new file mode 100644
index 00000000..e8a74312
--- /dev/null
+++ b/Dockerfile
@@ -0,0 +1,11 @@
+# Production Dockerfile for LangExtract
+FROM python:3.10-slim
+
+# Set working directory
+WORKDIR /app
+
+# Install LangExtract from PyPI
+RUN pip install --no-cache-dir langextract
+
+# Set default command
+CMD ["python"]
diff --git a/README.md b/README.md
index b49d4b6a..e88a89e3 100644
--- a/README.md
+++ b/README.md
@@ -1,12 +1,12 @@
# LangExtract
-[](https://badge.fury.io/py/langextract)
+[](https://pypi.org/project/langextract/)
[](https://github.com/google/langextract)

@@ -111,7 +111,7 @@ The extractions can be saved to a `.jsonl` file, a popular format for working wi
```python
# Save the results to a JSONL file
-lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
+lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# Generate the visualization from the file
html_content = lx.visualize("extraction_results.jsonl")
@@ -121,7 +121,7 @@ with open("visualization.html", "w") as f:
This creates an animated and interactive HTML file:
-
+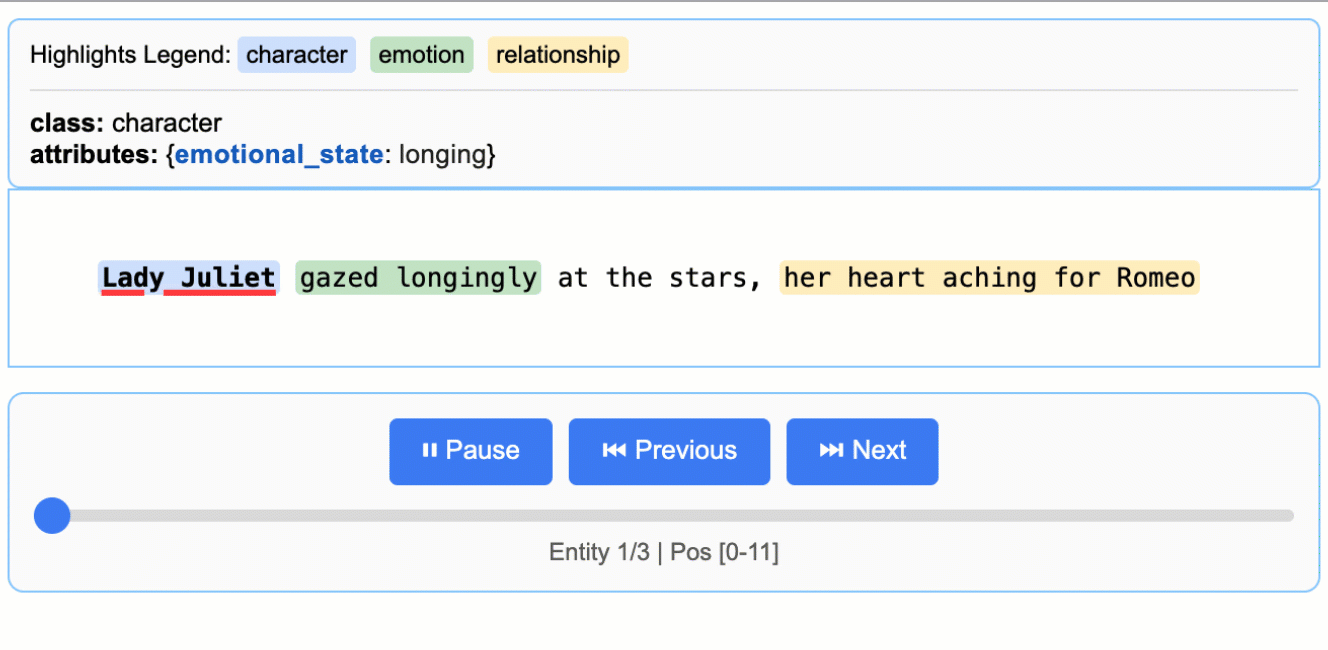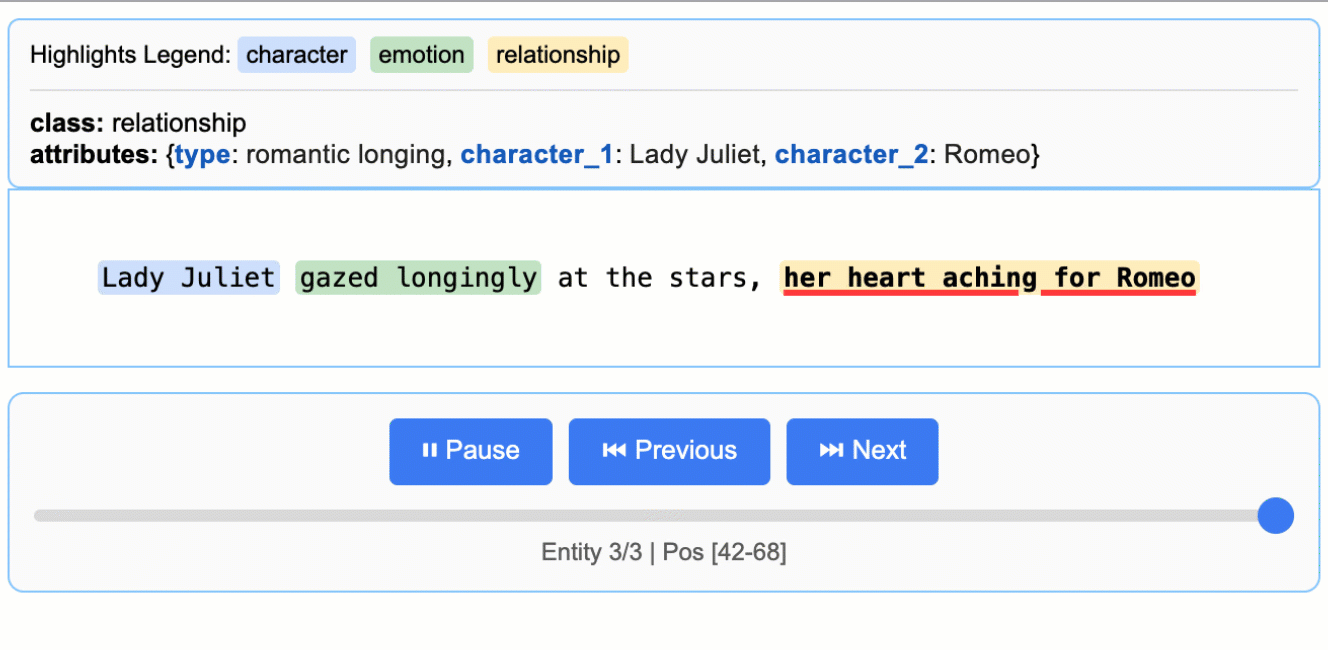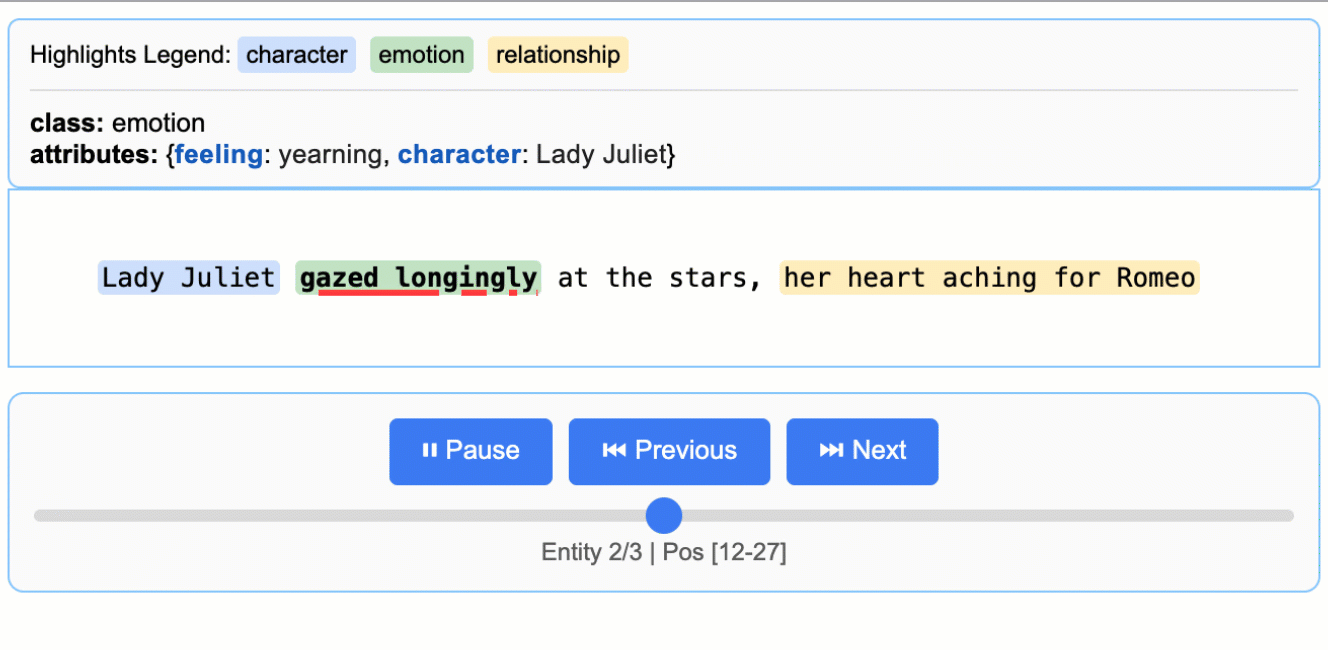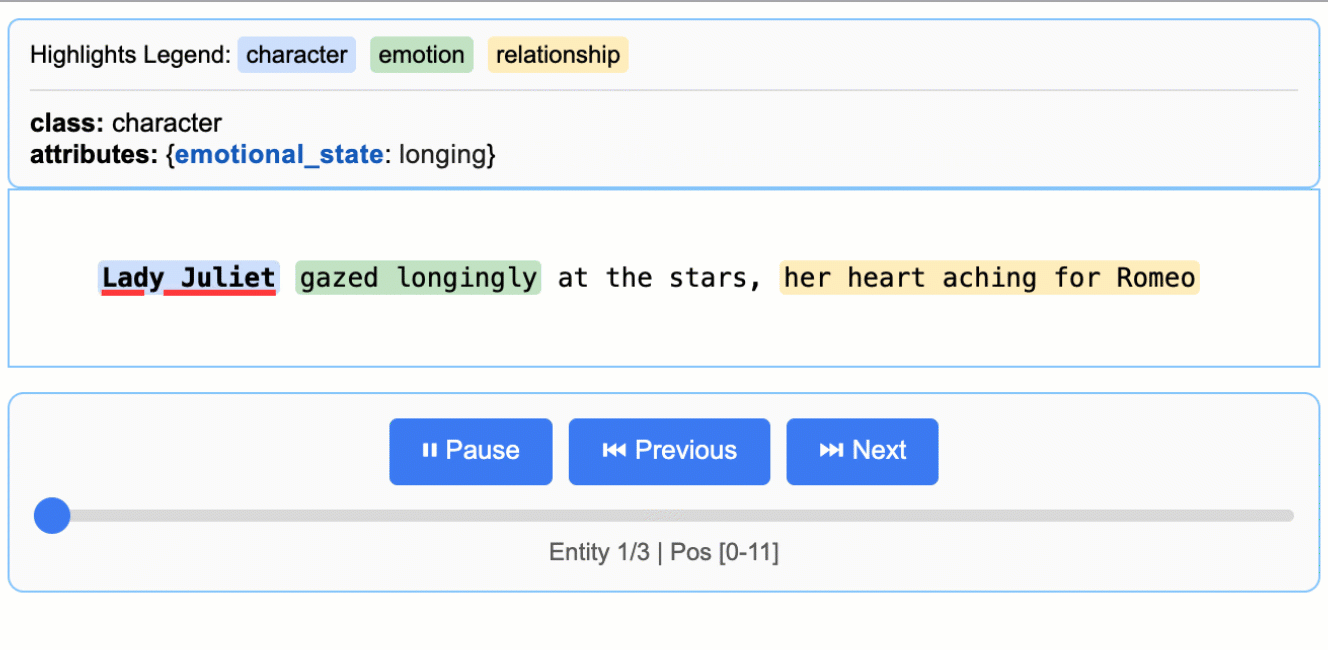
> **Note on LLM Knowledge Utilization:** This example demonstrates extractions that stay close to the text evidence - extracting "longing" for Lady Juliet's emotional state and identifying "yearning" from "gazed longingly at the stars." The task could be modified to generate attributes that draw more heavily from the LLM's world knowledge (e.g., adding `"identity": "Capulet family daughter"` or `"literary_context": "tragic heroine"`). The balance between text-evidence and knowledge-inference is controlled by your prompt instructions and example attributes.
@@ -142,7 +142,7 @@ result = lx.extract(
)
```
-This approach can extract hundreds of entities from full novels while maintaining high accuracy. The interactive visualization seamlessly handles large result sets, making it easy to explore hundreds of entities from the output JSONL file. **[See the full *Romeo and Juliet* extraction example →](docs/examples/longer_text_example.md)** for detailed results and performance insights.
+This approach can extract hundreds of entities from full novels while maintaining high accuracy. The interactive visualization seamlessly handles large result sets, making it easy to explore hundreds of entities from the output JSONL file. **[See the full *Romeo and Juliet* extraction example →](https://github.com/google/langextract/blob/main/docs/examples/longer_text_example.md)** for detailed results and performance insights.
## Installation
@@ -181,10 +181,16 @@ pip install -e ".[dev]"
pip install -e ".[test]"
```
+### Docker
+
+```bash
+docker build -t langextract .
+docker run --rm -e LANGEXTRACT_API_KEY="your-api-key" langextract python your_script.py
+```
## API Key Setup for Cloud Models
-When using LangExtract with cloud-hosted models (like Gemini), you'll need to
+When using LangExtract with cloud-hosted models (like Gemini or OpenAI), you'll need to
set up an API key. On-device models don't require an API key. For developers
using local LLMs, LangExtract offers built-in support for Ollama and can be
extended to other third-party APIs by updating the inference endpoints.
@@ -195,6 +201,7 @@ Get API keys from:
* [AI Studio](https://aistudio.google.com/app/apikey) for Gemini models
* [Vertex AI](https://cloud.google.com/vertex-ai/generative-ai/docs/sdks/overview) for enterprise use
+* [OpenAI Platform](https://platform.openai.com/api-keys) for OpenAI models
### Setting up API key in your environment
@@ -244,6 +251,27 @@ result = lx.extract(
)
```
+## Using OpenAI Models
+
+LangExtract also supports OpenAI models. Example OpenAI configuration:
+
+```python
+from langextract.inference import OpenAILanguageModel
+
+result = lx.extract(
+ text_or_documents=input_text,
+ prompt_description=prompt,
+ examples=examples,
+ language_model_type=OpenAILanguageModel,
+ model_id="gpt-4o",
+ api_key=os.environ.get('OPENAI_API_KEY'),
+ fence_output=True,
+ use_schema_constraints=False
+)
+```
+
+Note: OpenAI models require `fence_output=True` and `use_schema_constraints=False` because LangExtract doesn't implement schema constraints for OpenAI yet.
+
## More Examples
Additional examples of LangExtract in action:
@@ -252,7 +280,7 @@ Additional examples of LangExtract in action:
LangExtract can process complete documents directly from URLs. This example demonstrates extraction from the full text of *Romeo and Juliet* from Project Gutenberg (147,843 characters), showing parallel processing, sequential extraction passes, and performance optimization for long document processing.
-**[View *Romeo and Juliet* Full Text Example →](docs/examples/longer_text_example.md)**
+**[View *Romeo and Juliet* Full Text Example →](https://github.com/google/langextract/blob/main/docs/examples/longer_text_example.md)**
### Medication Extraction
@@ -260,7 +288,7 @@ LangExtract can process complete documents directly from URLs. This example demo
LangExtract excels at extracting structured medical information from clinical text. These examples demonstrate both basic entity recognition (medication names, dosages, routes) and relationship extraction (connecting medications to their attributes), showing LangExtract's effectiveness for healthcare applications.
-**[View Medication Examples →](docs/examples/medication_examples.md)**
+**[View Medication Examples →](https://github.com/google/langextract/blob/main/docs/examples/medication_examples.md)**
### Radiology Report Structuring: RadExtract
@@ -270,7 +298,7 @@ Explore RadExtract, a live interactive demo on HuggingFace Spaces that shows how
## Contributing
-Contributions are welcome! See [CONTRIBUTING.md](CONTRIBUTING.md) to get started
+Contributions are welcome! See [CONTRIBUTING.md](https://github.com/google/langextract/blob/main/CONTRIBUTING.md) to get started
with development, testing, and pull requests. You must sign a
[Contributor License Agreement](https://cla.developers.google.com/about)
before submitting patches.
@@ -297,14 +325,47 @@ Or reproduce the full CI matrix locally with tox:
tox # runs pylint + pytest on Python 3.10 and 3.11
```
+## Development
+
+### Code Formatting
+
+This project uses automated formatting tools to maintain consistent code style:
+
+```bash
+# Auto-format all code
+./autoformat.sh
+
+# Or run formatters separately
+isort langextract tests --profile google --line-length 80
+pyink langextract tests --config pyproject.toml
+```
+
+### Pre-commit Hooks
+
+For automatic formatting checks:
+```bash
+pre-commit install # One-time setup
+pre-commit run --all-files # Manual run
+```
+
+### Linting
+
+Run linting before submitting PRs:
+
+```bash
+pylint --rcfile=.pylintrc langextract tests
+```
+
+See [CONTRIBUTING.md](CONTRIBUTING.md) for full development guidelines.
+
## Disclaimer
This is not an officially supported Google product. If you use
LangExtract in production or publications, please cite accordingly and
-acknowledge usage. Use is subject to the [Apache 2.0 License](LICENSE).
+acknowledge usage. Use is subject to the [Apache 2.0 License](https://github.com/google/langextract/blob/main/LICENSE).
For health-related applications, use of LangExtract is also subject to the
[Health AI Developer Foundations Terms of Use](https://developers.google.com/health-ai-developer-foundations/terms).
---
-**Happy Extracting!**
\ No newline at end of file
+**Happy Extracting!**
diff --git a/autoformat.sh b/autoformat.sh
new file mode 100755
index 00000000..5b7b1897
--- /dev/null
+++ b/autoformat.sh
@@ -0,0 +1,125 @@
+#!/bin/bash
+# Copyright 2025 Google LLC
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Autoformat LangExtract codebase
+#
+# Usage: ./autoformat.sh [target_directory ...]
+# If no target is specified, formats the current directory
+#
+# This script runs:
+# 1. isort for import sorting
+# 2. pyink (Google's Black fork) for code formatting
+# 3. pre-commit hooks for additional formatting (trailing whitespace, end-of-file, etc.)
+
+set -e
+
+echo "LangExtract Auto-formatter"
+echo "=========================="
+echo
+
+# Check for required tools
+check_tool() {
+ if ! command -v "$1" &> /dev/null; then
+ echo "Error: $1 not found. Please install with: pip install $1"
+ exit 1
+ fi
+}
+
+check_tool "isort"
+check_tool "pyink"
+check_tool "pre-commit"
+
+# Parse command line arguments
+show_usage() {
+ echo "Usage: $0 [target_directory ...]"
+ echo
+ echo "Formats Python code using isort and pyink according to Google style."
+ echo
+ echo "Arguments:"
+ echo " target_directory One or more directories to format (default: langextract tests)"
+ echo
+ echo "Examples:"
+ echo " $0 # Format langextract and tests directories"
+ echo " $0 langextract # Format only langextract directory"
+ echo " $0 src tests # Format multiple specific directories"
+}
+
+# Check for help flag
+if [ "$1" = "-h" ] || [ "$1" = "--help" ]; then
+ show_usage
+ exit 0
+fi
+
+# Determine target directories
+if [ $# -eq 0 ]; then
+ TARGETS="langextract tests"
+ echo "No target specified. Formatting default directories: langextract tests"
+else
+ TARGETS="$@"
+ echo "Formatting targets: $TARGETS"
+fi
+
+# Find pyproject.toml relative to script location
+SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
+CONFIG_FILE="${SCRIPT_DIR}/pyproject.toml"
+
+if [ ! -f "$CONFIG_FILE" ]; then
+ echo "Warning: pyproject.toml not found at ${CONFIG_FILE}"
+ echo "Using default configuration."
+ CONFIG_ARG=""
+else
+ CONFIG_ARG="--config $CONFIG_FILE"
+fi
+
+echo
+
+# Run isort
+echo "Running isort to organize imports..."
+if isort $TARGETS; then
+ echo "Import sorting complete"
+else
+ echo "Import sorting failed"
+ exit 1
+fi
+
+echo
+
+# Run pyink
+echo "Running pyink to format code (Google style, 80 chars)..."
+if pyink $TARGETS $CONFIG_ARG; then
+ echo "Code formatting complete"
+else
+ echo "Code formatting failed"
+ exit 1
+fi
+
+echo
+
+# Run pre-commit hooks for additional formatting
+echo "Running pre-commit hooks for additional formatting..."
+if pre-commit run --all-files; then
+ echo "Pre-commit hooks passed"
+else
+ echo "Pre-commit hooks made changes - please review"
+ # Exit with success since formatting was applied
+ exit 0
+fi
+
+echo
+echo "All formatting complete!"
+echo
+echo "Next steps:"
+echo " - Run: pylint --rcfile=${SCRIPT_DIR}/.pylintrc $TARGETS"
+echo " - Commit your changes"
diff --git a/docs/examples/longer_text_example.md b/docs/examples/longer_text_example.md
index 62d1ff39..5adb4c06 100644
--- a/docs/examples/longer_text_example.md
+++ b/docs/examples/longer_text_example.md
@@ -76,7 +76,7 @@ result = lx.extract(
print(f"Extracted {len(result.extractions)} entities from {len(result.text):,} characters")
# Save and visualize the results
-lx.io.save_annotated_documents([result], output_name="romeo_juliet_extractions.jsonl")
+lx.io.save_annotated_documents([result], output_name="romeo_juliet_extractions.jsonl", output_dir=".")
# Generate the interactive visualization
html_content = lx.visualize("romeo_juliet_extractions.jsonl")
@@ -171,4 +171,4 @@ LangExtract combines precise text positioning with world knowledge enrichment, e
---
-¹ Models like Gemini 1.5 Pro show strong performance on many benchmarks, but [needle-in-a-haystack tests](https://cloud.google.com/blog/products/ai-machine-learning/the-needle-in-the-haystack-test-and-how-gemini-pro-solves-it) across million-token contexts indicate that performance can vary in multi-fact retrieval scenarios. This demonstrates how LangExtract's smaller context windows approach ensures consistently high quality across entire documents by avoiding the complexity and potential degradation of massive single-context processing.
\ No newline at end of file
+¹ Models like Gemini 1.5 Pro show strong performance on many benchmarks, but [needle-in-a-haystack tests](https://cloud.google.com/blog/products/ai-machine-learning/the-needle-in-the-haystack-test-and-how-gemini-pro-solves-it) across million-token contexts indicate that performance can vary in multi-fact retrieval scenarios. This demonstrates how LangExtract's smaller context windows approach ensures consistently high quality across entire documents by avoiding the complexity and potential degradation of massive single-context processing.
diff --git a/docs/examples/medication_examples.md b/docs/examples/medication_examples.md
index 7fb27b11..d6474964 100644
--- a/docs/examples/medication_examples.md
+++ b/docs/examples/medication_examples.md
@@ -62,7 +62,7 @@ for entity in result.extractions:
print(f"• {entity.extraction_class.capitalize()}: {entity.extraction_text}{position_info}")
# Save and visualize the results
-lx.io.save_annotated_documents([result], output_name="medical_ner_extraction.jsonl")
+lx.io.save_annotated_documents([result], output_name="medical_ner_extraction.jsonl", output_dir=".")
# Generate the interactive visualization
html_content = lx.visualize("medical_ner_extraction.jsonl")
@@ -193,7 +193,11 @@ for med_name, extractions in medication_groups.items():
print(f" • {extraction.extraction_class.capitalize()}: {extraction.extraction_text}{position_info}")
# Save and visualize the results
-lx.io.save_annotated_documents([result], output_name="medical_relationship_extraction.jsonl")
+lx.io.save_annotated_documents(
+ [result],
+ output_name="medical_ner_extraction.jsonl",
+ output_dir="."
+)
# Generate the interactive visualization
html_content = lx.visualize("medical_relationship_extraction.jsonl")
@@ -239,4 +243,4 @@ This example demonstrates how attributes enable efficient relationship extractio
- **Relationship Extraction**: Groups related entities using attributes
- **Position Tracking**: Records exact positions of extracted entities in the source text
- **Structured Output**: Organizes information in a format suitable for healthcare applications
-- **Interactive Visualization**: Generates HTML visualizations for exploring complex medical extractions with entity groupings and relationships clearly displayed
\ No newline at end of file
+- **Interactive Visualization**: Generates HTML visualizations for exploring complex medical extractions with entity groupings and relationships clearly displayed
diff --git a/exceptions.py b/exceptions.py
new file mode 100644
index 00000000..0199da56
--- /dev/null
+++ b/exceptions.py
@@ -0,0 +1,30 @@
+# Copyright 2025 Google LLC.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Base exceptions for LangExtract.
+
+This module defines the base exception class that all LangExtract exceptions
+inherit from. Individual modules define their own specific exceptions.
+"""
+
+__all__ = ["LangExtractError"]
+
+
+class LangExtractError(Exception):
+ """Base exception for all LangExtract errors.
+
+ All exceptions raised by LangExtract should inherit from this class.
+ This allows users to catch all LangExtract-specific errors with a single
+ except clause.
+ """
diff --git a/kokoro/presubmit.cfg b/kokoro/presubmit.cfg
index 6d821424..746c6d14 100644
--- a/kokoro/presubmit.cfg
+++ b/kokoro/presubmit.cfg
@@ -28,4 +28,4 @@ container_properties {
xunit_test_results {
target_name: "pytest_results"
result_xml_path: "git/repo/pytest_results/test.xml"
-}
\ No newline at end of file
+}
diff --git a/kokoro/test.sh b/kokoro/test.sh
index ba75ace2..87134817 100644
--- a/kokoro/test.sh
+++ b/kokoro/test.sh
@@ -103,4 +103,4 @@ deactivate
echo "========================================="
echo "Kokoro test script for langextract finished successfully."
-echo "========================================="
\ No newline at end of file
+echo "========================================="
diff --git a/langextract/__init__.py b/langextract/__init__.py
index 817e04f2..a278a095 100644
--- a/langextract/__init__.py
+++ b/langextract/__init__.py
@@ -18,13 +18,14 @@
from collections.abc import Iterable, Sequence
import os
-from typing import Any, Type, TypeVar, cast
+from typing import Any, cast, Type, TypeVar
import warnings
import dotenv
from langextract import annotation
from langextract import data
+from langextract import exceptions
from langextract import inference
from langextract import io
from langextract import prompting
@@ -32,6 +33,19 @@
from langextract import schema
from langextract import visualization
+__all__ = [
+ "extract",
+ "visualize",
+ "annotation",
+ "data",
+ "exceptions",
+ "inference",
+ "io",
+ "prompting",
+ "resolver",
+ "schema",
+ "visualization",
+]
LanguageModelT = TypeVar("LanguageModelT", bound=inference.BaseLanguageModel)
diff --git a/langextract/annotation.py b/langextract/annotation.py
index fe3b5a54..a370be9e 100644
--- a/langextract/annotation.py
+++ b/langextract/annotation.py
@@ -31,6 +31,7 @@
from langextract import chunking
from langextract import data
+from langextract import exceptions
from langextract import inference
from langextract import progress
from langextract import prompting
@@ -39,7 +40,7 @@
ATTRIBUTE_SUFFIX = "_attributes"
-class DocumentRepeatError(Exception):
+class DocumentRepeatError(exceptions.LangExtractError):
"""Exception raised when identical document ids are present."""
diff --git a/langextract/chunking.py b/langextract/chunking.py
index 3625d7a1..2663ed85 100644
--- a/langextract/chunking.py
+++ b/langextract/chunking.py
@@ -28,10 +28,11 @@
import more_itertools
from langextract import data
+from langextract import exceptions
from langextract import tokenizer
-class TokenUtilError(Exception):
+class TokenUtilError(exceptions.LangExtractError):
"""Error raised when token_util returns unexpected values."""
diff --git a/langextract/exceptions.py b/langextract/exceptions.py
new file mode 100644
index 00000000..b3103ab7
--- /dev/null
+++ b/langextract/exceptions.py
@@ -0,0 +1,26 @@
+# Copyright 2025 Google LLC.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Base exceptions for LangExtract."""
+
+__all__ = ["LangExtractError"]
+
+
+class LangExtractError(Exception):
+ """Base exception for all LangExtract errors.
+
+ All exceptions raised by LangExtract should inherit from this class.
+ This allows users to catch all LangExtract-specific errors with a single
+ except clause.
+ """
diff --git a/langextract/inference.py b/langextract/inference.py
index 822661fd..f041126d 100644
--- a/langextract/inference.py
+++ b/langextract/inference.py
@@ -24,17 +24,15 @@
from typing import Any
from google import genai
-import langfun as lf
+import openai
import requests
from typing_extensions import override
import yaml
-
-
from langextract import data
+from langextract import exceptions
from langextract import schema
-
_OLLAMA_DEFAULT_MODEL_URL = 'http://localhost:11434'
@@ -52,7 +50,7 @@ def __str__(self) -> str:
return f'Score: {self.score:.2f}\nOutput:\n{formatted_lines}'
-class InferenceOutputError(Exception):
+class InferenceOutputError(exceptions.LangExtractError):
"""Exception raised when no scored outputs are available from the language model."""
def __init__(self, message: str):
@@ -99,49 +97,6 @@ class InferenceType(enum.Enum):
MULTIPROCESS = 'multiprocess'
-# TODO: Add support for llm options.
-@dataclasses.dataclass(init=False)
-class LangFunLanguageModel(BaseLanguageModel):
- """Language model inference class using LangFun language class.
-
- See https://github.com/google/langfun for more details on LangFun.
- """
-
- _lm: lf.core.language_model.LanguageModel # underlying LangFun model
- _constraint: schema.Constraint = dataclasses.field(
- default_factory=schema.Constraint, repr=False, compare=False
- )
- _extra_kwargs: dict[str, Any] = dataclasses.field(
- default_factory=dict, repr=False, compare=False
- )
-
- def __init__(
- self,
- language_model: lf.core.language_model.LanguageModel,
- constraint: schema.Constraint = schema.Constraint(),
- **kwargs,
- ) -> None:
- self._lm = language_model
- self._constraint = constraint
-
- # Preserve any unused kwargs for debugging / future use
- self._extra_kwargs = kwargs or {}
- super().__init__(constraint=constraint)
-
- @override
- def infer(
- self, batch_prompts: Sequence[str], **kwargs
- ) -> Iterator[Sequence[ScoredOutput]]:
- responses = self._lm.sample(prompts=batch_prompts)
- for a_response in responses:
- for sample in a_response.samples:
- yield [
- ScoredOutput(
- score=sample.response.score, output=sample.response.text
- )
- ]
-
-
@dataclasses.dataclass(init=False)
class OllamaLanguageModel(BaseLanguageModel):
"""Language model inference class using Ollama based host."""
@@ -429,7 +384,186 @@ def infer(
yield [result]
def parse_output(self, output: str) -> Any:
- """Parses Gemini output as JSON or YAML."""
+ """Parses Gemini output as JSON or YAML.
+
+ Note: This expects raw JSON/YAML without code fences.
+ Code fence extraction is handled by resolver.py.
+ """
+ try:
+ if self.format_type == data.FormatType.JSON:
+ return json.loads(output)
+ else:
+ return yaml.safe_load(output)
+ except Exception as e:
+ raise ValueError(
+ f'Failed to parse output as {self.format_type.name}: {str(e)}'
+ ) from e
+
+
+@dataclasses.dataclass(init=False)
+class OpenAILanguageModel(BaseLanguageModel):
+ """Language model inference using OpenAI's API with structured output."""
+
+ model_id: str = 'gpt-4o-mini'
+ api_key: str | None = None
+ organization: str | None = None
+ model_url: str | None = None
+ format_type: data.FormatType = data.FormatType.JSON
+ temperature: float = 0.0
+ max_workers: int = 10
+ _client: openai.OpenAI | None = dataclasses.field(
+ default=None, repr=False, compare=False
+ )
+ _extra_kwargs: dict[str, Any] = dataclasses.field(
+ default_factory=dict, repr=False, compare=False
+ )
+
+ def __init__(
+ self,
+ model_id: str = 'gpt-4o-mini',
+ api_key: str | None = None,
+ organization: str | None = None,
+ model_url: str | None = None,
+ format_type: data.FormatType = data.FormatType.JSON,
+ temperature: float = 0.0,
+ max_workers: int = 10,
+ **kwargs,
+ ) -> None:
+ """Initialize the OpenAI language model.
+
+ Args:
+ model_id: The OpenAI model ID to use (e.g., 'gpt-4o-mini', 'gpt-4o').
+ api_key: API key for OpenAI service.
+ organization: Optional OpenAI organization ID.
+ model_url: Optional OpenAI model URL.
+ format_type: Output format (JSON or YAML).
+ temperature: Sampling temperature.
+ max_workers: Maximum number of parallel API calls.
+ **kwargs: Ignored extra parameters so callers can pass a superset of
+ arguments shared across back-ends without raising ``TypeError``.
+ """
+ self.model_id = model_id
+ self.api_key = api_key
+ self.organization = organization
+ self.model_url = model_url
+ self.format_type = format_type
+ self.temperature = temperature
+ self.max_workers = max_workers
+ self._extra_kwargs = kwargs or {}
+
+ if not self.api_key:
+ raise ValueError('API key not provided.')
+
+ # Initialize the OpenAI client
+ #Mandatory parameters for OpenAI client
+ client_kwargs = {
+ 'api_key': self.api_key,
+ 'organization': self.organization,
+ }
+
+ # Optional parameters
+ if self.model_url:
+ client_kwargs['base_url'] = self.model_url
+
+ self._client = openai.OpenAI(**client_kwargs)
+
+ super().__init__(
+ constraint=schema.Constraint(constraint_type=schema.ConstraintType.NONE)
+ )
+
+ def _process_single_prompt(self, prompt: str, config: dict) -> ScoredOutput:
+ """Process a single prompt and return a ScoredOutput."""
+ try:
+ # Prepare the system message for structured output
+ system_message = ''
+ if self.format_type == data.FormatType.JSON:
+ system_message = (
+ 'You are a helpful assistant that responds in JSON format.'
+ )
+ elif self.format_type == data.FormatType.YAML:
+ system_message = (
+ 'You are a helpful assistant that responds in YAML format.'
+ )
+
+ # Create the chat completion using the v1.x client API
+ response = self._client.chat.completions.create(
+ model=self.model_id,
+ messages=[
+ {'role': 'system', 'content': system_message},
+ {'role': 'user', 'content': prompt},
+ ],
+ temperature=config.get('temperature', self.temperature),
+ max_tokens=config.get('max_output_tokens'),
+ top_p=config.get('top_p'),
+ n=1,
+ )
+
+ # Extract the response text using the v1.x response format
+ output_text = response.choices[0].message.content
+
+ return ScoredOutput(score=1.0, output=output_text)
+
+ except Exception as e:
+ raise InferenceOutputError(f'OpenAI API error: {str(e)}') from e
+
+ def infer(
+ self, batch_prompts: Sequence[str], **kwargs
+ ) -> Iterator[Sequence[ScoredOutput]]:
+ """Runs inference on a list of prompts via OpenAI's API.
+
+ Args:
+ batch_prompts: A list of string prompts.
+ **kwargs: Additional generation params (temperature, top_p, etc.)
+
+ Yields:
+ Lists of ScoredOutputs.
+ """
+ config = {
+ 'temperature': kwargs.get('temperature', self.temperature),
+ }
+ if 'max_output_tokens' in kwargs:
+ config['max_output_tokens'] = kwargs['max_output_tokens']
+ if 'top_p' in kwargs:
+ config['top_p'] = kwargs['top_p']
+
+ # Use parallel processing for batches larger than 1
+ if len(batch_prompts) > 1 and self.max_workers > 1:
+ with concurrent.futures.ThreadPoolExecutor(
+ max_workers=min(self.max_workers, len(batch_prompts))
+ ) as executor:
+ future_to_index = {
+ executor.submit(
+ self._process_single_prompt, prompt, config.copy()
+ ): i
+ for i, prompt in enumerate(batch_prompts)
+ }
+
+ results: list[ScoredOutput | None] = [None] * len(batch_prompts)
+ for future in concurrent.futures.as_completed(future_to_index):
+ index = future_to_index[future]
+ try:
+ results[index] = future.result()
+ except Exception as e:
+ raise InferenceOutputError(
+ f'Parallel inference error: {str(e)}'
+ ) from e
+
+ for result in results:
+ if result is None:
+ raise InferenceOutputError('Failed to process one or more prompts')
+ yield [result]
+ else:
+ # Sequential processing for single prompt or worker
+ for prompt in batch_prompts:
+ result = self._process_single_prompt(prompt, config.copy())
+ yield [result]
+
+ def parse_output(self, output: str) -> Any:
+ """Parses OpenAI output as JSON or YAML.
+
+ Note: This expects raw JSON/YAML without code fences.
+ Code fence extraction is handled by resolver.py.
+ """
try:
if self.format_type == data.FormatType.JSON:
return json.loads(output)
diff --git a/langextract/io.py b/langextract/io.py
index 7f94a193..59dead7a 100644
--- a/langextract/io.py
+++ b/langextract/io.py
@@ -18,23 +18,21 @@
import dataclasses
import json
import os
+import pathlib
from typing import Any, Iterator
import pandas as pd
import requests
-import os
-import pathlib
-import os
-import pathlib
from langextract import data
from langextract import data_lib
+from langextract import exceptions
from langextract import progress
DEFAULT_TIMEOUT_SECONDS = 30
-class InvalidDatasetError(Exception):
+class InvalidDatasetError(exceptions.LangExtractError):
"""Error raised when Dataset is empty or invalid."""
@@ -83,7 +81,7 @@ def load(self, delimiter: str = ',') -> Iterator[data.Document]:
def save_annotated_documents(
annotated_documents: Iterator[data.AnnotatedDocument],
- output_dir: pathlib.Path | None = None,
+ output_dir: pathlib.Path | str | None = None,
output_name: str = 'data.jsonl',
show_progress: bool = True,
) -> None:
@@ -92,7 +90,7 @@ def save_annotated_documents(
Args:
annotated_documents: Iterator over AnnotatedDocument objects to save.
output_dir: The directory to which the JSONL file should be written.
- Defaults to 'test_output/' if None.
+ Can be a Path object or a string. Defaults to 'test_output/' if None.
output_name: File name for the JSONL file.
show_progress: Whether to show a progress bar during saving.
@@ -102,6 +100,8 @@ def save_annotated_documents(
"""
if output_dir is None:
output_dir = pathlib.Path('test_output')
+ else:
+ output_dir = pathlib.Path(output_dir)
output_dir.mkdir(parents=True, exist_ok=True)
diff --git a/langextract/progress.py b/langextract/progress.py
index a79b9126..41c4f3b8 100644
--- a/langextract/progress.py
+++ b/langextract/progress.py
@@ -16,6 +16,7 @@
from typing import Any
import urllib.parse
+
import tqdm
# ANSI color codes for terminal output
diff --git a/langextract/prompting.py b/langextract/prompting.py
index 5d6623b1..4484273b 100644
--- a/langextract/prompting.py
+++ b/langextract/prompting.py
@@ -16,17 +16,18 @@
import dataclasses
import json
+import os
+import pathlib
import pydantic
import yaml
-import os
-import pathlib
from langextract import data
+from langextract import exceptions
from langextract import schema
-class PromptBuilderError(Exception):
+class PromptBuilderError(exceptions.LangExtractError):
"""Failure to build prompt."""
diff --git a/langextract/resolver.py b/langextract/resolver.py
index e9085f16..c6496b82 100644
--- a/langextract/resolver.py
+++ b/langextract/resolver.py
@@ -31,6 +31,7 @@
import yaml
from langextract import data
+from langextract import exceptions
from langextract import schema
from langextract import tokenizer
@@ -151,7 +152,7 @@ def align(
ExtractionValueType = str | int | float | dict | list | None
-class ResolverParsingError(Exception):
+class ResolverParsingError(exceptions.LangExtractError):
"""Error raised when content cannot be parsed as the given format."""
diff --git a/langextract/schema.py b/langextract/schema.py
index 2c02baac..dd553bdc 100644
--- a/langextract/schema.py
+++ b/langextract/schema.py
@@ -22,7 +22,6 @@
import enum
from typing import Any
-
from langextract import data
diff --git a/langextract/tokenizer.py b/langextract/tokenizer.py
index f4036f36..5028fb0f 100644
--- a/langextract/tokenizer.py
+++ b/langextract/tokenizer.py
@@ -30,8 +30,10 @@
from absl import logging
+from langextract import exceptions
-class BaseTokenizerError(Exception):
+
+class BaseTokenizerError(exceptions.LangExtractError):
"""Base class for all tokenizer-related errors."""
diff --git a/langextract/visualization.py b/langextract/visualization.py
index 513cfa58..b382961a 100644
--- a/langextract/visualization.py
+++ b/langextract/visualization.py
@@ -28,10 +28,10 @@
import html
import itertools
import json
-import textwrap
-
import os
import pathlib
+import textwrap
+
from langextract import data as _data
from langextract import io as _io
@@ -119,9 +119,7 @@
padding: 8px 10px; margin-top: 8px; font-size: 13px;
}
.lx-current-highlight {
- text-decoration: underline;
- text-decoration-color: #ff4444;
- text-decoration-thickness: 3px;
+ border-bottom: 4px solid #ff4444;
font-weight: bold;
animation: lx-pulse 1s ease-in-out;
}
@@ -130,9 +128,9 @@
50% { text-decoration-color: #ff0000; }
100% { text-decoration-color: #ff4444; }
}
- .lx-legend {
- font-size: 12px; margin-bottom: 8px;
- padding-bottom: 8px; border-bottom: 1px solid #e0e0e0;
+ .lx-legend {
+ font-size: 12px; margin-bottom: 8px;
+ padding-bottom: 8px; border-bottom: 1px solid #e0e0e0;
}
.lx-label {
display: inline-block;
@@ -456,12 +454,12 @@ def _extraction_sort_key(extraction):