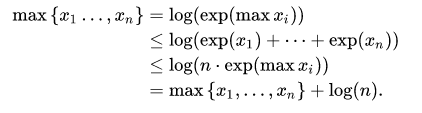Weighted normalization term missing #1
Description
In general, a PNN for M classes is defined as:
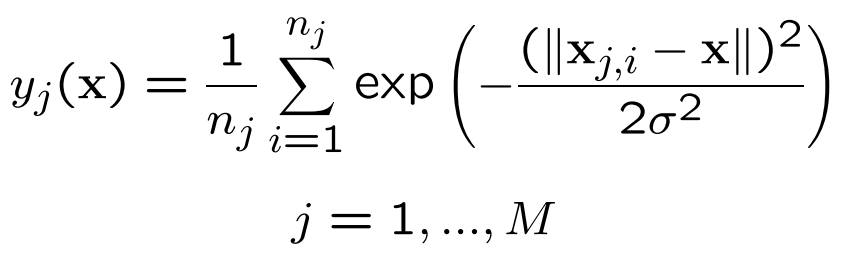
therefore, the normalization term 1/n_j, where j is the i-th class of the dataset, is missing in the pattern layer of the algorithm. This term grants that there's no probability greater than 1.
Thus, in the final layer, when the maximum a posterior probability (MAP) hypothesis is tested we must take into account such term as shown in the equation below.